1、TiDB引入
1.1. 数据库技术发展简史
数据库技术产生于20世纪60年代末70年代初,其主要主要研究如何存储,使用和管理数据。随着计算机硬件和软件的发展,数据库技术也不断地发展。数据库技术在理论研究和系统开发上都取得了辉煌的成就。
从数据管理的角度看,数据库技术到目前共经历了如下三个阶段:
- 人工管理阶段-数据量小独立,用户直接管理
- 文件系统阶段-使用文件存取数据,冗余度高,管理维护难
- 数据库系统阶段-专门的数据库软件系统管理数据,高效方便,易于共享维护
按照数据模型发展的主线,数据库技术的形成过程和发展可分为如下三个阶段:
层次和网状数据库管理系统-可以理解为使用指针来表示数据之间的联系
关系数据库管理系统(RDBMS)-可以理解为理解为使用二维表来表示维护数据间的关系
新一代数据库技术的研究和发展-针对关系型数据库存在数据模型,性能,扩展性,伸缩性等方面的缺点,出现了:
ORDBMS:面向对象数据库技术。如:PostGreSQL
NoSQL:非结构化数据库技术。如
1):键值存储数据库:Redis
2):列式储数数据库:HBase
3):文档型数据库:MongoDB
4):图形数据库:Neo4J
NewSQL:这类数据库不仅具有NoSQL对海量数据的存储管理能力,还保持了传统数据库支持ACID和SQL等特性。如:TiDB
1.2. 从MySQL到TiDB
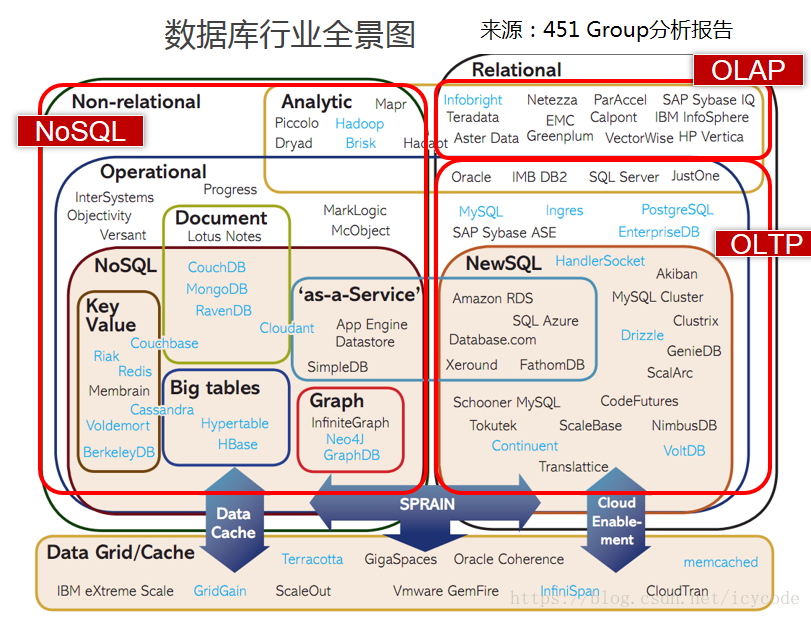
如今的数据库种类繁多,RDBMS(关系型数据库)、NoSQL(Not Only SQL)、NewSQL,在数据库领域均有一席之地,可谓百家争鸣之势。那么我们为什么要学习使用TiDB呢?接下来就从我们最熟悉的MySQL的使用说起!
1.2.1. 场景引入
假设现在有一个高速发展的互联网公司,核心业务库MySQL的数据量已经近亿行,且还在不断增长中,公司对于数据资产较为重视,所有数据要求多副本保存至少5年,且除了有对历史数据进行统计分析的离线报表业务外,还有一些针对用户数据实时查询的需求,如用户历史订单实时查询。
1.2.2. 问题分析
1、MySQL能否满足上述场景需求
根据以往的MySQL使用经验,MySQL单表在 5000 万行以内时,性能较好,单表超过5000万行后,数据库性能、可维护性都会极剧下降。当然这时候可以做MySQL分库分表,如使用Mycat或Sharding-jdbc
2、分库分表的能否解决问题
分库分表的优点非常明显,如:
- 将大表拆分成小表,单表数据量控制在 5000 万行以内,使 MySQL 性能稳定可控。
- 将单张大表拆分成小表后,能水平扩展,通过部署到多台服务器,提升整个集群的 QPS、TPS、Latency 等数据库服务指标。
但是,此方案的缺点也非常明显:
- 分表跨实例后,产生分布式事务管理难题,一旦数据库服务器宕机,有事务不一致风险。
- 分表后,对 SQL 语句有一定限制,对业务方功能需求大打折扣。尤其对于实时报表统计类需求,限制非常之大。事实上,报表大多都是提供给高层领导使用的,其重要性不言而喻。
- 分表后,需要维护的对象呈指数增长(MySQL实例数、需要执行的 SQL 变更数量等)。
3、能不能使用nosql数据库解决
我们是不是可以使用hbase、redis、mongdb等数据库解决?不行,因为nosql数据库能解决单表数据量的问题,但是它们对sql的支持不好,它们只方便于解决特定领域的问题有优势。
1.2.3. 问题解决
基于以上核心痛点,我们需要探索新的数据库技术方案来应对业务爆发式增长所带来的挑战,为业务提供更好的数据库服务支撑。
调研市场上的各大数据库,我们可以考虑选用NewSQL技术来解决,因为NewSQL技术有如下显著特点:
- 无限水平扩展能力(可以无限的加机器)
- 分布式强一致性,确保数据 100% 安全
- 完整的分布式事务处理能力与 传统数据库的ACID 特性
而TiDB数据库 GitHub的活跃度及社区贡献者方面都可以算得上是国际化的开源项目,是NewSQL技术中的代表性产品,所以我们可以选择使用TiDB数据库!
1.2.4. 总结
传统关系型数据库历史比较久,目前RDBMS的代表为Oracle、MySQL、PostgreSQL,在数据库领域也是“辈份”比较高的,其广泛应用在各行各业,RDBMS大多为本地存储或共享存储。
但是此类数据库存在着一些问题,如自身容量的限制。随着业务量不断增加,容量渐渐成为瓶颈,此时DBA(数据库管理员Database Administrator)会通过多次的分库分表(中间件sharding-JDBC),以此来缓解容量问题。大量的分库分表,不仅耗费了大量人力,还使得业务访问数据库的路由逻辑变得复杂。除此之外,RDBMS伸缩性比较差,通常集群扩容缩容成本较高,且不满足分布式的事务。
NoSQL类数据库的代表为Hbase、Redis、MongoDB、Cassandra等,这类数据库解决了 RDBMS伸缩性差的问题,集群容量扩容变得方便很多,但是由于存储方式为多个KV存储,所以对SQL的兼容性就大打折扣。对于NoSQL类数据库来说,只能满足部分分布式事务的特点。
NewSQL领域的代表是Google的spanner和F1,其号称可以实现全球数据中心容灾,且完全满足分布式事务的ACID,但是只能在Google云上使用。
TiDB诞生在大背景下,也弥补了国内在NewSQL领域中的空缺。TiDB自2015年5月写下第一行代码以来,至今已发布大小版本几十次,版本迭代十分迅速。
1.3. TiDB概述
1.3.1. 官网
https://pingcap.com/index.html
https://docs.pingcap.com/zh/tidb/stable
TiDB:开源分布式关系型数据库,可以理解为是MySQL的加强版/分布式MySQL/MySQLPlus。

1.3.2. 简介
TiDB 是 PingCAP 公司自主设计、研发的开源分布式关系型数据库,是一款同时支持在线事务处理与在线分析处理 (Hybrid Transactional and Analytical Processing, HTAP)的融合型分布式数据库产品,具备水平扩容或者缩容、金融级高可用、实时 HTAP、云原生的分布式数据库、兼容 MySQL 5.7 协议和 MySQL 生态等重要特性。目标是为用户提供一站式 OLTP (Online Transactional Processing)、OLAP (Online Analytical Processing)、HTAP 解决方案。TiDB 适合高可用、强一致要求较高、数据规模较大等各种应用场景。
TiDB数据库具备「分布式强一致性事务、在线弹性水平扩展、故障自恢复的高可用、跨数据中心多活」等核心特性,是大数据时代理想的数据库集群和云数据库解决方案。目前,已被近 1000 家不同行业的领先企业应用在实际生产环境,涉及互联网、游戏、银行、保险、证券、航空、制造业、电信、新零售、政府等多个行业,包括美国、欧洲、日本、东南亚等海外用户。
TiDB 的设计目标是 100% 的 OLTP 场景和 80% 的 OLAP 场景,更复杂的 OLAP 分析可以通过 TiSpark 项目来完成。
TiDB 对业务没有任何侵入性,能优雅的替换传统的数据库中间件、数据库分库分表等 Sharding 方案。同时它也让开发运维人员不用关注数据库 Scale 的细节问题,专注于业务开发,极大的提升研发的生产力。
1.4. 扩展阅读
1.4.1. 数据管理技术发展阶段
人工管理阶段:20世纪50年代以前,计算机主要用于数值计算.从当时的硬件看,外存只有纸带,卡片,磁带,没有直接存取设备;从软件看(实际上,当时还未形成软件的整体概念),没有操作系统以及管理数据的软件;从数据看,数据量小,数据无结构,由用户直接管理,且数据间缺乏逻辑组织,数据依赖于特定的应用程序,缺乏独立性.
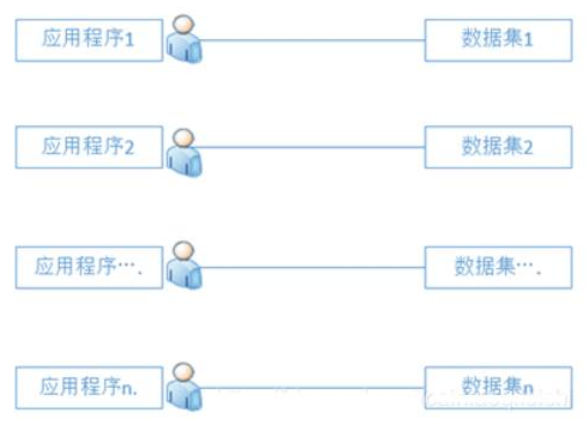
文件系统阶段:50年代后期到60年代中期,出现了磁鼓,磁盘等数据存储设备.新的数据处理系统迅速发展起来.这种数据处理系统是把计算机中的数据组织成相互独立的数据文件,系统可以按照文件的名称对其进行访问,对文件中的记录进行存取,并可以实现对文件的修改,插入和删除,这就是文件系统.文件系统实现了记录内的结构化,即给出了记录内各种数据间的关系.但是,文件从整体来看却是无结构的.其数据面向特定的应用程序,因此数据共享性差,且冗余度大,管理和维护的代价也很大.
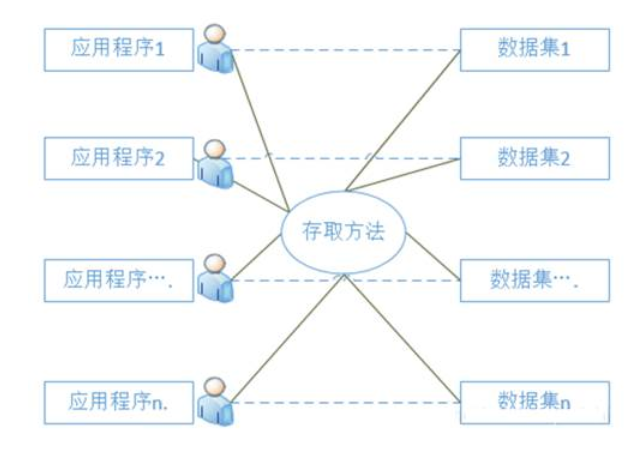
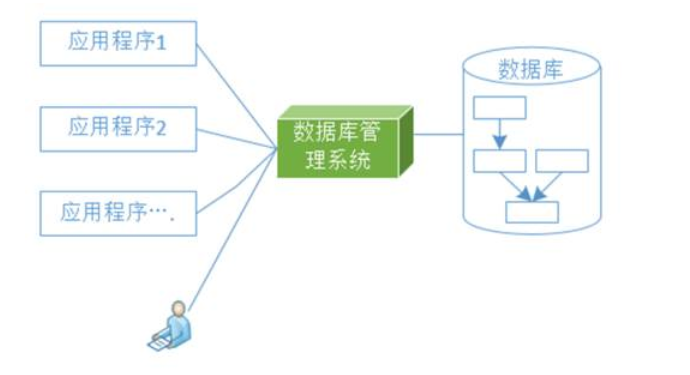
数据库系统阶段:60年代后期,出现了数据库这样的数据管理技术.数据库的特点是数据不再只针对某一特定应用,而是面向全组织,具有整体的结构性,共享性高,冗余度小,具有一定的程序与数据间的独立性,并且实现了对数据进行统一的控制.
1.4.2. 数据库模型发展阶段
第一代数据库系统 层次和网状数据库管理系统
层次和网状数据库的代表产品是IBM公司在1969年研制出的层次模型数据库管理系统。层次数据库是数据库系统的先驱,而网状数据库则是数据库概念、方法、技术的奠基。第二代数据库系统 关系数据库管理系统(RDBMS)
1970年,IBM公司的研究员E.F.Codd在题为《大型共享数据库数据的关系模型》的论文中提出了数据库的关系模型,为关系数据库技术奠定了理论基础。到了80年代,几乎所有新开发的数据库系统都是关系型的。真正使得关系数据库技术实用化的关键人物是James Gray。Gray在解决如何保障数据的完整性、安全性、并发性以及数据库的故障恢复能力等重大技术问题方面发挥了关键作用。关系数据库系统的出现,促进了数据库的小型化和普及化,使得在微型机上配置数据库系统成为可能。
新一代数据库技术的研究和发展
目前已从多方面发展了现行的数据库系统技术。我们可以从数据模型、新技术内容、应用领域三个方面概括新一代数据库系统的发展。
(1) 面向对象的方法和技术对数据库发展的影响最为深远
80年代,面向对象的方法和技术的出现,对计算机各个领域,包括程序设计语言、软件工程、信息系统设计以及计算机硬件设备等都产生了深远的影响,也给面临新挑战的数据库技术带来了新的机遇和希望。数据库研究人员借鉴和吸收了面向对象的方法和技术,提出了面向对象的数据库模型(简称对象模型)。当前有许多研究是建立在数据库已有的成果和技术上的,针对不同的应用,对传统的DBMS,主要是RDBMS进行不同层次上的扩充,例如建立对象关系(OR)模型和建立对象关系数据库(ORDB)。
(2) 数据库技术与多学科技术的有机结合
数据库技术与多学科技术的有机结合是当前数据库发展的重要特征。计算机领域中其他新兴技术的发展对数据库技术产生了重大影响。传统的数据库技术和其他计算机技术的结合、互相渗透,使数据库中新的技术内容层出不穷。数据库的许多概念、技术内容、应用领域,甚至某些原理都有了重大的发展和变化。建立和实现了一系列新型的数据库,如分布式数据库、并行数据库、演绎数据库、知识库、多媒体库、移动数据库等,它们共同构成了数据库大家族。
(3) 面向专门应用领域的数据库技术的研究
为了适应数据库应用多元化的要求,在传统数据库基础上,结合各个专门应用领域的特点,研究适合该应用领域的数据库技术,如工程数据库、统计数据库、科学数据库、空间数据库、地理数据库、Web数据库等,这是当前数据库技术发展的又一重要特征。同时,数据库系统结构也由主机/终端的集中式结构发展到网络环境的分布式结构,随后又发展成两层、三层或多层客户/服务器结构以及Internet环境下的浏览器/服务器和移动环境下的动态结构。多种数据库结构满足了不同应用的需求,适应了不同的应用环境。
1.4.3. SQL,NoSQL,NewSQL
1、关系型数据库(RDBMS,即SQL数据库)
商业软件: Oracle,DB2
开源软件:MySQL,PostgreSQL
单机版本已经很难满足海量数据的需求
2、NoSQL
NoSQL = Not Only SQL,意即“不仅仅是SQL,提倡运用非关系型的数据存储
普遍选择牺牲掉复杂 SQL 的支持及 ACID 事务换取弹性扩展能力
通常不保证强一致性的(支持最终一致)
主要分类:
- 键值(Key-Value)数据库:如 MemcacheDB,Redis
- 文档存储:如 MongoDB
- 列存储:方便存储结构化和半结构化数据,并做数据压缩,对某几列的查询有非常大的IO优势: 如 HBase,Cassandra
- 图数据库:存储图关系(注意:不是图片)。如 Neo4J
3、NewSQL
针对OLTP的读写,提供与NOSQL相同的可扩展性和性能,同时能支持满足ACID特性的事务,即保持NoSQL的高可扩展和高性能,并且保持关系模型。
为什么需要NewSQL?
- NoSQL 不能完全取代 RDBMS
- 单机RDBMS 无法满足性能需求
- 使用“单机RDBMS + 中间件”方式,在中间件层很难解决分布式事务、高可用问题
NewSQL设计架构
- 可以基于全新的数据库平台,也可以基于现有的SQL引擎优化。
- 无共享存储(MPP架构)是比较常见的架构
- 基于多副本实现高可用和容灾
- 分布式查询
- 数据Sharding机制
- 通过2PC,Paxos/Raft等协议实现数据一致
代表产品
- Google Spanner
- OceanBase
- TiDB
1.4.4. OLTP和OLAP
OLTP
强调支持短时间内大量并发的事务操作(增删改查)能力,每个操作涉及的数据量都很小(比如几十到几百字节)
强调事务的强一致性(想想银行转账交易,容不得差错)
举例:“双十一”期间,可能有几十万用户在同一秒内下订单。后台数据库要能够并发的、以近乎实时的速度处理这些订单请求(如果下了订单,十几分钟还没有反应,用户肯定要骂人了)
OLAP
偏向于复杂的只读查询,读取海量数据进行分析计算,查询时间往往很长
举例:“双十一”结束,淘宝的运营人员对订单进行分析挖掘,找出一些市场规律等等。 这种分析可能需要读取所有的历史订单进行计算,耗时几十秒甚至几十分钟都有可能。
代表产品:
Greenplum
TeraData
阿里 AnalyticDB
1.4.5. TiDB怎么诞生的?
著名的开源分布式缓存服务 Codis 的作者,PingCAP联合创始人& CTO ,资深 infrastructure 工程师的黄东旭,擅长分布式存储系统的设计与实现,开源狂热分子的技术大神级别人物。即使在互联网如此繁荣的今天,在数据库这片边界模糊且不确定地带,他还在努力寻找确定性的实践方向。
2012 年底,他看到 Google 发布的两篇论文,如同棱镜般,折射出他自己内心微烁的光彩。这两篇论文描述了 Google 内部使用的一个海量关系型数据F1/Spanner,解决了关系型数据库、弹性扩展以及全球分布的问题,并在生产中大规模使用。“如果这个能实现,对数据存储领域来说将是颠覆性的”,黄东旭为完美方案的出现而兴奋, PingCAP 的 TiDB 在此基础上诞生了。
2、TiDB架构特性
2.1. TiDB 整体架构
TiDB 集群主要包括三个核心组件:TiDB Server,PD Server 和 TiKV Server。此外,还有用于解决用户复杂 OLAP 需求的 TiSpark 组件和简化云上部署管理的 TiDB Operator 组件。
架构图解
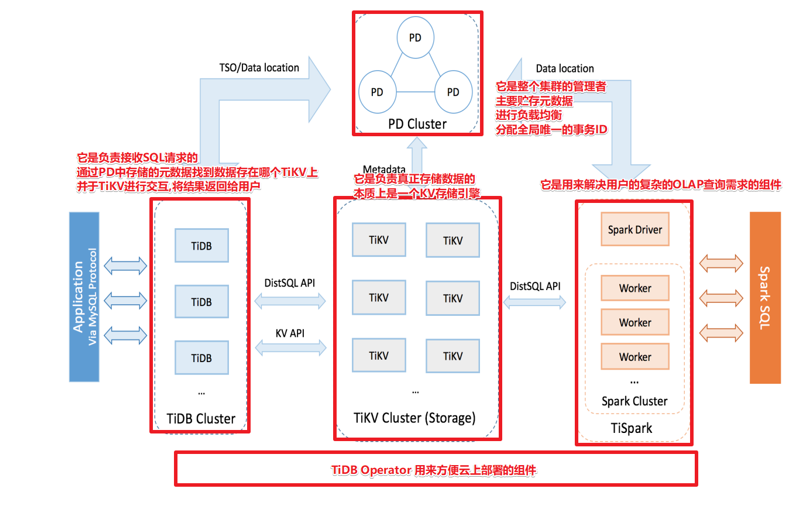
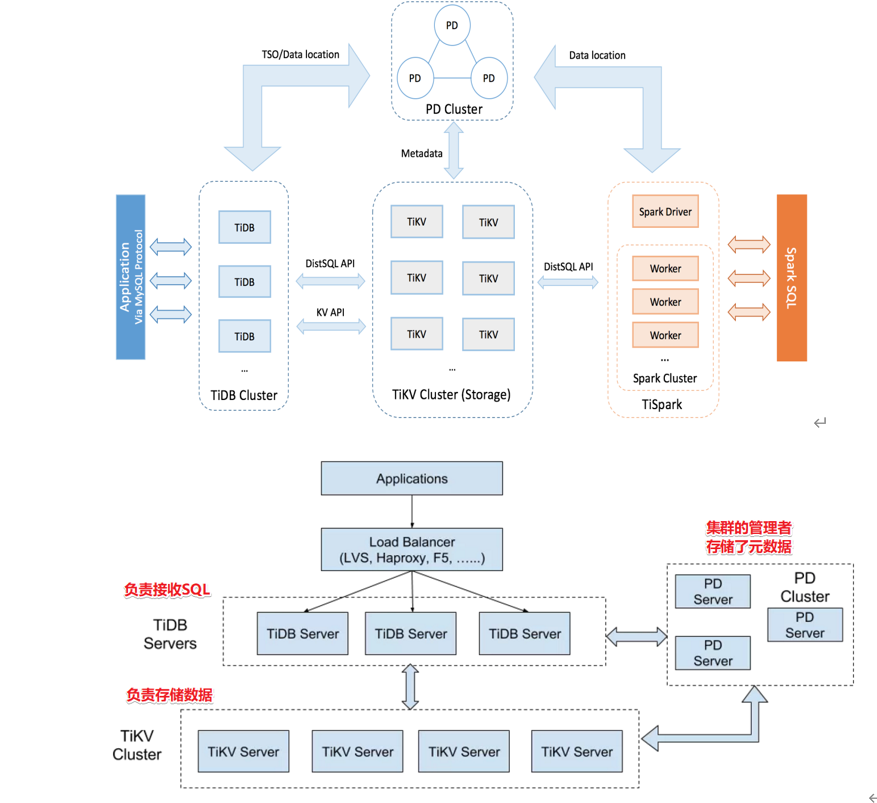
2.1.1. TiDB Server
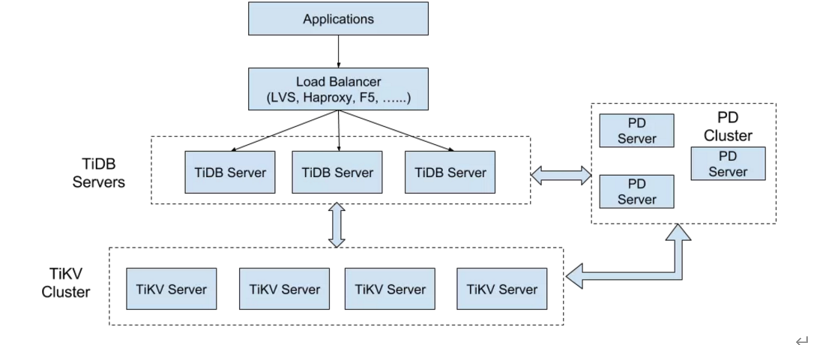
TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑,并通过 PD 找到存储计算所需数据的 TiKV 地址,与 TiKV 交互获取数据,最终返回结果。TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(如LVS、HAProxy 或 F5)对外提供统一的接入地址。
2.1.2. PD Server
Placement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个:一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader 的迁移等);三是分配全局唯一且递增的事务 ID。
PD 通过 Raft 协议保证数据的安全性。Raft 的 leader server 负责处理所有操作,其余的 PD server 仅用于保证高可用。建议部署奇数个 PD 节点。
2.1.3. TiKV Server
TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 Raft Group,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度。
2.1.4. TiSpark
TiSpark 作为 TiDB 中解决用户复杂 OLAP 需求的主要组件,将 Spark SQL 直接运行在 TiDB 存储层上,同时融合 TiKV 分布式集群的优势,并融入大数据社区生态。至此,TiDB 可以通过一套系统,同时支持 OLTP 与 OLAP,免除用户数据同步的烦恼。
2.1.5. TiDB Operator
TiDB Operator 提供在主流云基础设施(Kubernetes)上部署管理 TiDB 集群的能力。它结合云原生社区的容器编排最佳实践与 TiDB 的专业运维知识,集成一键部署、多集群混部、自动运维、故障自愈等能力,极大地降低了用户使用和管理 TiDB 的门槛与成本。
2.2. TiDB 核心特性
TiDB 具备如下众多特性,其中两大核心特性为:水平扩展与高可用
1、高度兼容 MySQL
大多数情况下,无需修改代码即可从 MySQL 轻松迁移至 TiDB,分库分表后的 MySQL 集群亦可通过 TiDB 工具进行实时迁移。
对于用户使用的时候,可以透明地从MySQL切换到TiDB 中,只是“新MySQL”的后端是存储“无限的”,不再受制于Local的磁盘容量。在运维使用时也可以将TiDB当做一个从库挂到MySQL主从架构中。
2、分布式事务
TiDB 100% 支持标准的 ACID 事务。
3、一站式 HTAP 解决方案
HTAP: 在线事务处理/在线分析处理(Hybrid Transactional/Analytical Processing)
TiDB 作为典型的 OLTP 行存数据库,同时兼具强大的 OLAP 性能,配合 TiSpark,可提供一站式 HTAP 解决方案,一份存储同时处理 OLTP & OLAP,无需传统繁琐的 ETL 过程。
4、云原生 SQL 数据库
TiDB 是为云而设计的数据库,支持公有云、私有云和混合云,配合 TiDB Operator 项目 可实现自动化运维,使部署、配置和维护变得十分简单。
5、水平弹性扩展
通过简单地增加新节点即可实现 TiDB 的水平扩展,按需扩展吞吐或存储,轻松应对高并发、海量数据场景。
6、真正金融级高可用
相比于传统主从 (M-S) 复制方案,基于 Raft 的多数派选举协议可以提供金融级的 100% 数据强一致性保证,且在不丢失大多数副本的前提下,可以实现故障的自动恢复 (auto-failover),无需人工介入。
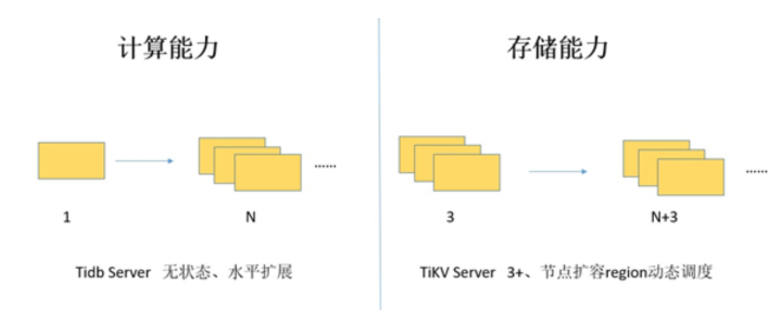
2.2.1. 水平扩展
无限水平扩展是 TiDB 的一大特点,这里说的水平扩展包括两方面:计算能力(TiDB)和存储能力(TiKV)。
TiDB Server 负责处理 SQL 请求,随着业务的增长,可以简单的添加 TiDB Server 节点,提高整体的处理能力,提供更高的吞吐。
TiKV 负责存储数据,随着数据量的增长,可以部署更多的 TiKV Server 节点解决数据 Scale 的问题。
PD 会在 TiKV 节点之间以 Region 为单位做调度,将部分数据迁移到新加的节点上。
所以在业务的早期,可以只部署少量的服务实例(推荐至少部署 3 个 TiKV, 3 个 PD,2 个 TiDB),随着业务量的增长,按照需求添加 TiKV 或者 TiDB 实例。
2.2.2. 高可用
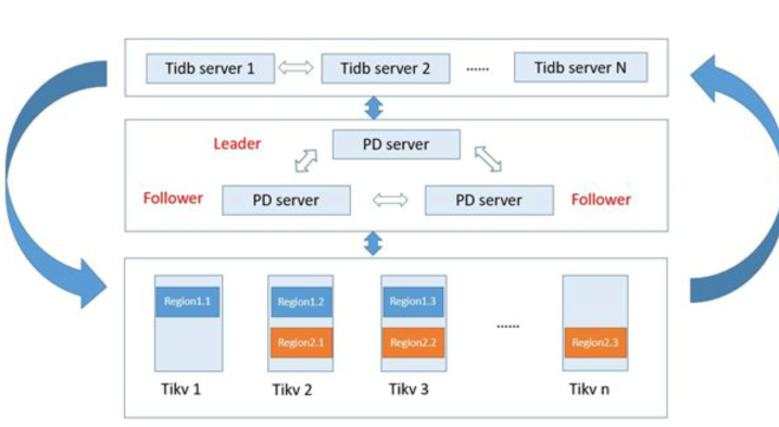
高可用是 TiDB 的另一大特点,TiDB/TiKV/PD 这三个组件都能容忍部分实例失效,不影响整个集群的可用性。下面分别说明这三个组件的可用性、单个实例失效后的后果以及如何恢复。
1、TiDB
TiDB 是无状态的,推荐至少部署两个实例,前端通过负载均衡组件对外提供服务。当单个实例失效时,会影响正在这个实例上进行的 Session,从应用的角度看,会出现单次请求失败的情况,重新连接后即可继续获得服务。单个实例失效后,可以重启这个实例或者部署一个新的实例。
2、PD
PD 是一个集群,通过 Raft 协议保持数据的一致性,单个实例失效时,如果这个实例不是 Raft 的 leader,那么服务完全不受影响;如果这个实例是 Raft 的 leader,会重新选出新的 Raft leader,自动恢复服务。PD 在选举的过程中无法对外提供服务,这个时间大约是3秒钟。推荐至少部署三个 PD 实例,单个实例失效后,重启这个实例或者添加新的实例。
3、TiKV
TiKV 是一个集群,通过 Raft 协议保持数据的一致性(副本数量可配置,默认保存三副本),并通过 PD 做负载均衡调度。单个节点失效时,会影响这个节点上存储的所有 Region。对于 Region 中的 Leader 节点,会中断服务,等待重新选举;对于 Region 中的 Follower 节点,不会影响服务。当某个 TiKV 节点失效,并且在一段时间内(默认 30 分钟)无法恢复,PD 会将其上的数据迁移到其他的 TiKV 节点上。
2.3. TiDB 存储和计算能力
2.3.1. 存储能力-TiKV-LSM
TiKV Server通常是3+的,TiDB每份数据缺省为3副本,这一点与HDFS有些相似,但是通过Raft协议进行数据复制,TiKV Server上的数据的是以Region为单位进行,由PD Server集群进行统一调度,类似HBASE的Region调度。
TiKV集群存储的数据格式是KV的,在TiDB中,并不是将数据直接存储在 HDD/SSD中,而是通过RocksDB实现了TB级别的本地化存储方案,着重提的一点是:RocksDB和HBASE一样,都是通过 LSM树作为存储方案,避免了B+树叶子节点膨胀带来的大量随机读写。从何提升了整体的吞吐量。
2.3.2. 计算能力-TiDB Server
TiDB Server本身是无状态的,意味着当计算能力成为瓶颈的时候,可以直接扩容机器,对用户是透明的。理论上TiDB Server的数量并没有上限限制。
2.4. 总结
TiDB作为新一代的NewSQL数据库,在数据库领域已经逐渐站稳脚跟,结合了Etcd/MySQL/HDFS/HBase/Spark等技术的突出特点,随着TiDB的大面积推广,会逐渐弱化 OLTP/OLAP的界限,并简化目前冗杂的ETL流程,引起新一轮的技术浪潮。
一言以蔽之,TiDB,前景可待,未来可期。
3、TiDB安装部署
快速安装体验
https://docs.pingcap.com/zh/tidb/stable/quick-start-with-tidb
CLUSTER START SUCCESSFULLY, Enjoy it ^-^
To connect TiDB: mysql --host 10.3.6.62 --port 4001 -u root -p (no password)
To connect TiDB: mysql --host 10.3.6.62 --port 4000 -u root -p (no password)
To view the dashboard: http://10.3.6.62:2379/dashboard
To view the Prometheus: http://10.3.6.62:9090
To view the Grafana: http://10.3.6.62:3000补充:
- tiup playground v5.0.0 –db 2 –pd 3 –kv 3 –monitor –host 10.3.6.62 添加–host,局域网外部访问
- Grafana默认用户名admin,密码admin
- dashboard默认用户名为 root,密码为空
4、TiDB实践
4.1 TiDB-SQL操作
操作文档:https://docs.pingcap.com/zh/tidb/stable/basic-sql-operations
To connect TiDB: mysql --host 10.3.6.62 --port 4001 -u root -p (no password)
To connect TiDB: mysql --host 10.3.6.62 --port 4000 -u root -p (no password)TiDB与mysql兼容性对比:https://docs.pingcap.com/zh/tidb/stable/mysql-compatibility
成功部署 TiDB 集群之后,便可以在 TiDB 中执行 SQL 语句了。因为 TiDB 兼容 MySQL,可以使用 MySQL 客户端连接 TiDB,并且大多数情况下可以直接执行 MySQL 语句。
mysql --host 10.3.6.62 --port 4000 -u root -p
show databases;
4.1.1 创建、查看和删除数据库
1、要创建一个名为 samp_db 的数据库,可使用以下语句。
CREATE DATABASE IF NOT EXISTS samp_db;2、使用 SHOW DATABASES 语句查看数据库。
SHOW DATABASES;3、使用 DROP DATABASE 语句删除数据库。
DROP DATABASE samp_db;4、再次查看数据库。
SHOW DATABASES;4.1.2 创建、查看和删除表
1、先创建一个库。
CREATE DATABASE IF NOT EXISTS samp_db;
USE samp_db;2、使用 SHOW TABLES 语句查看数据库中的所有表。
SHOW TABLES FROM samp_db;3、使用 CREATE TABLE 语句创建表。
如果表已存在,添加 IF NOT EXISTS 可防止发生错误。
CREATE TABLE IF NOT EXISTS person (
number INT(11),
name VARCHAR(255),
birthday DATE
);4、使用 SHOW CREATE 语句查看建表语句。
SHOW CREATE table person;5、使用 SHOW FULL COLUMNS 语句查看表的列。
SHOW FULL COLUMNS FROM person;6、使用 DROP TABLE 语句删除表。
DROP TABLE person;
或者
DROP TABLE IF EXISTS person;4.1.3 创建、查看和删除索引
1、先创建一张表。
CREATE TABLE IF NOT EXISTS person (
number INT(11),
name VARCHAR(255),
birthday DATE
);2、对于值不唯一的列,可使用 CREATE INDEX 或 ALTER TABLE 语句。
CREATE INDEX person_num ON person (number);
或者
ALTER TABLE person ADD INDEX person_num (number);
CREATE UNIQUE INDEX person_num ON person(number); // 创建唯一索引3、使用 SHOW INDEX 语句查看表内所有索引。
SHOW INDEX from person;4、使用 ALTER TABLE 或 DROP INDEX 语句来删除索引。与 CREATE INDEX 语句类似,DROP INDEX 也可以嵌入 ALTER TABLE 语句。
DROP INDEX person_num ON person;
ALTER TABLE person DROP INDEX person_num;5、对于值唯一的列,可以创建唯一索引。
CREATE UNIQUE INDEX person_num ON person (number);
或者
ALTER TABLE person ADD UNIQUE person_num (number);4.1.4 增删改查数据
1、使用 INSERT 语句向表内插入数据。
INSERT INTO person VALUES("1","tom","20170912");2、使用 SELECT 语句检索表内数据。
SELECT * FROM person;3、使用 UPDATE 语句修改表内数据。
UPDATE person SET birthday='20200202' WHERE name='tom';
SELECT * FROM person;4、使用 DELETE 语句删除表内数。
DELETE FROM person WHERE number=1;
SELECT * FROM person;4.1.5 创建、授权和删除用户
1、使用 CREATE USER 语句创建一个用户 tiuser,密码为 123456。
CREATE USER 'tiuser'@'localhost' IDENTIFIED BY '123456';2、授权用户 tiuser 可检索数据库 samp_db 内的表。
GRANT SELECT ON samp_db.* TO 'tiuser'@'localhost';3、查询用户 tiuser 的权限。
SHOW GRANTS for tiuser@localhost;4、删除用户 tiuser。
DROP USER 'tiuser'@'localhost';5、查看所有权限。
SHOW GRANTS;4.2 TiDB-读取历史数据
接下来介绍 TiDB 如何读取历史版本数据,包括具体的操作流程以及历史数据的保存策略。
4.2.1 功能说明
TiDB 实现了通过标准 SQL 接口读取历史数据功能,无需特殊的 client 或者 driver。当数据被更新、删除后,依然可以通过 SQL 接口将更新/删除前的数据读取出来。
另外即使在更新数据之后,表结构发生了变化,TiDB 依旧能用旧的表结构将数据读取出来。
4.2.2 操作流程
为支持读取历史版本数据, 引入了一个新的 system variable: tidb_snapshot ,这个变量是 Session 范围有效,可以通过标准的 Set 语句修改其值。其值为文本,能够存储 TSO 和日期时间。TSO 即是全局授时的时间戳,是从 PD 端获取的; 日期时间的格式可以为: “2020-10-08 16:45:26.999”,一般来说可以只写到秒,比如”2020-10-08 16:45:26”。 当这个变量被设置时,TiDB 会用这个时间戳建立 Snapshot(没有开销,只是创建数据结构),随后所有的 Select 操作都会在这个 Snapshot 上读取数据。
注意:TiDB 的事务是通过 PD 进行全局授时,所以存储的数据版本也是以 PD 所授时间戳作为版本号。在生成 Snapshot 时,是以 tidb_snapshot 变量的值作为版本号,如果 TiDB Server 所在机器和 PD Server 所在机器的本地时间相差较大,需要以 PD 的时间为准。
当读取历史版本操作结束后,可以结束当前 Session 或者是通过 Set 语句将 tidb_snapshot 变量的值设为 “”,即可读取最新版本的数据。
4.2.3 历史数据保留策略
TiDB 使用 MVCC 管理版本,当更新/删除数据时,不会做真正的数据删除,只会添加一个新版本数据,所以可以保留历史数据。历史数据不会全部保留,超过一定时间的历史数据会被彻底删除,以减小空间占用以及避免历史版本过多引入的性能开销。
TiDB 使用周期性运行的 GC(Garbage Collection,垃圾回收)来进行清理,关于 GC 的详细介绍参见 TiDB 垃圾回收 (GC)。
这里需要重点关注的是 tikv_gc_life_time 和 tikv_gc_safe_point 这条。tikv_gc_life_time 用于配置历史版本保留时间,可以手动修改;tikv_gc_safe_point 记录了当前的 safePoint,用户可以安全地使用大于 safePoint 的时间戳创建 snapshot 读取历史版本。safePoint 在每次 GC 开始运行时自动更新。
示例
1、初始化阶段,创建一个表,并插入几行数据。
create table t (c int);
insert into t values (1), (2), (3);2、查看表中的数据。
select * from t;
+------+
| c |
+------+
| 1 |
| 2 |
| 3 |
+------+3、查看当前时间。
select now();
+---------------------+
| now() |
+---------------------+
| 2021-01-11 14:05:26 |
+---------------------+4、更新某一行数据。
update t set c=22 where c=2;5、确认数据已经被更新。
select * from t;
+------+
| c |
+------+
| 1 |
| 22 |
| 3 |
+------+6、设置一个特殊的环境变量,这个是一个 session scope 的变量,其意义为读取这个时间之前的最新的一个版本。
set @@tidb_snapshot="2021-01-11 14:05:26";注意:这里的时间设置的是 update 语句之前的那个时间。
在 tidb_snapshot 前须使用 @@ 而非 @,因为 @@ 表示系统变量,@ 表示用户变量。
7、这里读取到的内容即为 update 之前的内容,也就是历史版本。
select * from t;
+------+
| c |
+------+
| 1 |
| 2 |
| 3 |
+------+8、清空这个变量后,即可读取最新版本数据。
set @@tidb_snapshot="";
select * from t;
+------+
| c |
+------+
| 1 |
| 22 |
| 3 |
+------+注意:在 tidb_snapshot 前须使用 @@ 而非 @,因为 @@ 表示系统变量,@ 表示用户变量。
4.3 数据迁移-TiDB Lightning
原本使用的是MySQL数据库,现在随着数据量的变大,需要迁移到TiDB数据库,那么原本mysql的数据库如何迁移呢?
https://docs.pingcap.com/zh/tidb/stable/migrate-from-aurora-using-lightning
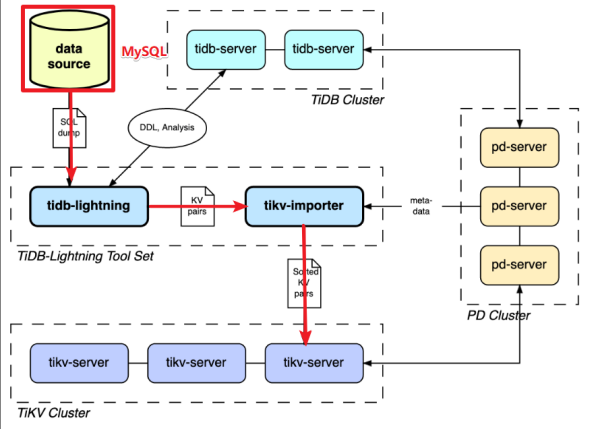
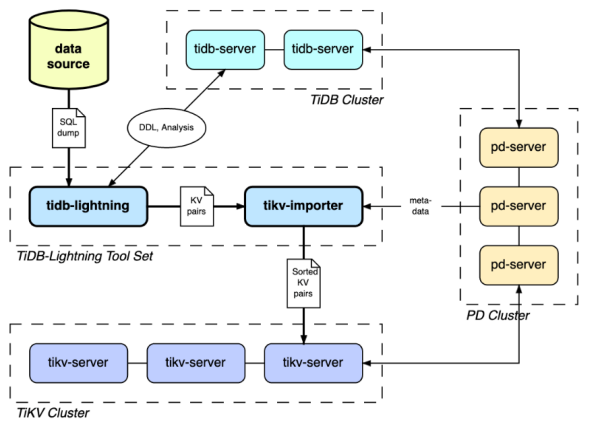
4.4.1 TiDB Lightning介绍
TiDB Lightning 是一个将全量数据高速导入到 TiDB 集群的工具,目前支持 Mydumper 或 CSV 输出格式的数据源。你可以在以下两种场景下使用 Lightning:
- 迅速导入大量新数据。
- 备份恢复所有数据。
TiDB Lightning 主要包含两个部分:
- tidb-lightning(“前端”):主要完成适配工作,通过读取数据源,在下游 TiDB 集群建表、将数据转换成键/值对 (KV 对) 发送到 tikv-importer、检查数据完整性等。
- tikv-importer(“后端”):主要完成将数据导入 TiKV 集群的工作,把 tidb-lightning 写入的 KV 对缓存、排序、切分并导入到 TiKV 集群。
4.4.2 准备迁移工具
wget https://download.pingcap.org/tidb-enterprise-tools-latest-linux-amd64.tar.gz
wget https://download.pingcap.org/tidb-toolkit-latest-linux-amd64.tar.gz
解压4.4.3 准备MySQL数据
CREATE DATABASE mytest;
USE mytest;
CREATE TABLE mytest.t1 (
id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
c CHAR (32),
PORT INT
);
insert into t1 values (),(),(),(),(),(),(),();
insert into t1 (id) select null from t1;
insert into t1 (id) select null from t1;
insert into t1 (id) select null from t1;
insert into t1 (id) select null from t1;
insert into t1 (id) select null from t1;
update t1 set c=md5(id), port=@@port;
CREATE TABLE mytest.t2 (
id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
c CHAR (32),
PORT INT
);
insert into t2 values (),(),(),(),(),(),(),();
insert into t2 (id) select null from t2;
insert into t2 (id) select null from t2;
insert into t2 (id) select null from t2;
insert into t2 (id) select null from t2;
insert into t2 (id) select null from t2;
update t2 set c=md5(id), port=@@port;4.4.4 导出数据
mkdir -p /data/my_database/
cd tidb-enterprise-tools-latest-linux-amd64/bin/
./mydumper -h 127.0.0.1 -P 3306 -u root -p Root@1234 -t 16 -F 256 -B mytest -T t1,t2 --skip-tz-utc -o /data/my_database/
cd /data/my_database其中:
-B mytest :从 mytest 数据库导出。
-T t1,t2:只导出 t1 和 t2 这两个表。
-t 16:使用 16 个线程导出数据。
-F 256:将每张表切分成多个文件,每个文件大小约为 256 MB。
–skip-tz-utc:添加这个参数则会忽略掉 TiDB 与导数据的机器之间时区设置不一致的情况,禁止自动转换。
这样全量备份数据就导出到了/data/my_database目录中。
4.4.5 启动tikv-importer
cd tidb-toolkit-v4.0.9-linux-amd64/bin/
vim tikv-importer.toml# TiKV Importer 配置文件模版
# 日志文件。
log-file = "tikv-importer.log"
# 日志等级:trace、debug、info、warn、error、off。
log-level = "info"
[server]
# tikv-importer 监听的地址,tidb-lightning 需要连到这个地址进行数据写入。
addr = "192.168.19.130:8287"
[import]
# 存储引擎文档 (engine file) 的文件夹路径。
import-dir = "/mnt/ssd/data.import/"nohup ./tikv-importer -C tikv-importer.toml > nohup.out &4.4.6 启动tidb-lightning
vim run.sh#!/bin/bash
nohup ./tidb-lightning \
--importer 192.168.19.130:8287 \
-d /data/my_database/ \
--pd-urls 0.0.0.0:2379 \
--tidb-host 192.168.19.130 \
--tidb-user root \
--log-file tidb-lightning.log \
> nohup.out &chmod 755 run.sh
./run.sh4.4.7 注意
内存有性能要求,使用单机版测试即可
systemctl stop docker
cd tidb-v4.0.9-linux-amd64/
./bin/pd-server –data-dir=pd –log-file=pd.log &
./bin/tikv-server –pd=”127.0.0.1:2379” –data-dir=tikv –log-file=tikv.log &
./bin/tidb-server –store=tikv –path=”127.0.0.1:2379” –log-file=tidb.log &
5、TiDB技术内幕
6、TiDB 监控框架
https://docs.pingcap.com/zh/tidb/stable/tidb-monitoring-framework
6、生成亿级测试数据
建立tidb数据软连接
ln -s /nvme_201931448402/tidb-data tidb-data
ln -s /nvme_201931448402/tidb-deploy tidb-deploy使用go-tpc工具生成数据,使用方式:
- https://github.com/pingcap/go-tpc
- https://github.com/pingcap/go-tpc/blob/master/docs/import-to-tidb.md
- 数据量:https://docs.pingcap.com/zh/tidb/stable/benchmark-tidb-using-tpcc
编译go-tpc
// 10000条warehouses记录,数据库名test,tidb:192.168.1.93:4000,16个线程 ./go-tpc tpcc prepare --warehouses 10000 -D test -H 192.168.1.93 -P 4000 -T 16 --output-type csv --output-dir csv/
使用lightning导入数据https://docs.pingcap.com/zh/tidb/stable/tidb-lightning-overview
wget https://download.pingcap.org/tidb-toolkit-v4.0.8-linux-amd64.tar.gz // 修改配置 vim tidb-lightning.toml
执行导入
nohup ./tidb-toolkit-v4.0.8-linux-amd64/bin/tidb-lightning -config tidb-lightning.toml > nohup.out &
6.1 测试数据库tpcc表结构
1、 warehouse:仓库表
| 序号 | 名称 | 描述 | 类型 | 键 | 为空 | 额外 | 默认值 |
|---|---|---|---|---|---|---|---|
| 1 | w_id |
仓库ID | int(11) | PRI | NO | ||
| 2 | w_name |
仓库名称 | varchar(10) | YES | |||
| 3 | w_street_1 |
街道 | varchar(20) | YES | |||
| 4 | w_street_2 |
varchar(20) | YES | ||||
| 5 | w_city |
城市 | varchar(20) | YES | |||
| 6 | w_state |
状态 | char(2) | YES | |||
| 7 | w_zip |
char(9) | YES | ||||
| 8 | w_tax |
decimal(4,4) | YES | ||||
| 9 | w_ytd |
decimal(12,2) | YES |
2、 customer:客户表
| 序号 | 名称 | 描述 | 类型 | 键 | 为空 | 额外 | 默认值 |
|---|---|---|---|---|---|---|---|
| 1 | c_id |
客户ID | int(11) | PRI | NO | ||
| 2 | c_d_id |
地区ID | int(11) | PRI | NO | ||
| 3 | c_w_id |
仓库ID | int(11) | PRI | NO | ||
| 4 | c_first |
varchar(16) | YES | ||||
| 5 | c_middle |
char(2) | YES | ||||
| 6 | c_last |
varchar(16) | YES | ||||
| 7 | c_street_1 |
varchar(20) | YES | ||||
| 8 | c_street_2 |
varchar(20) | YES | ||||
| 9 | c_city |
varchar(20) | YES | ||||
| 10 | c_state |
char(2) | YES | ||||
| 11 | c_zip |
char(9) | YES | ||||
| 12 | c_phone |
char(16) | YES | ||||
| 13 | c_since |
datetime | YES | ||||
| 14 | c_credit |
char(2) | YES | ||||
| 15 | c_credit_lim |
decimal(12,2) | YES | ||||
| 16 | c_discount |
decimal(4,4) | YES | ||||
| 17 | c_balance |
decimal(12,2) | YES | ||||
| 18 | c_ytd_payment |
decimal(12,2) | YES | ||||
| 19 | c_payment_cnt |
int(11) | YES | ||||
| 20 | c_delivery_cnt |
int(11) | YES | ||||
| 21 | c_data |
varchar(500) | YES |
3、 history:交易历史表
| 序号 | 名称 | 描述 | 类型 | 键 | 为空 | 额外 | 默认值 |
|---|---|---|---|---|---|---|---|
| 1 | h_c_id |
客户ID | int(11) | NO | |||
| 2 | h_c_d_id |
客户地区ID | int(11) | NO | |||
| 3 | h_c_w_id |
客户仓库ID | int(11) | MUL | NO | ||
| 4 | h_d_id |
int(11) | NO | ||||
| 5 | h_w_id |
int(11) | MUL | NO | |||
| 6 | h_date |
datetime | YES | ||||
| 7 | h_amount |
decimal(6,2) | YES | ||||
| 8 | h_data |
varchar(24) | YES |
4、 new_order:最新订单表
| 序号 | 名称 | 描述 | 类型 | 键 | 为空 | 额外 | 默认值 |
|---|---|---|---|---|---|---|---|
| 1 | no_o_id |
订单ID | int(11) | PRI | NO | ||
| 2 | no_d_id |
地区ID | int(11) | PRI | NO | ||
| 3 | no_w_id |
仓库ID | int(11) | PRI | NO |
5、 orders:订单表
| 序号 | 名称 | 描述 | 类型 | 键 | 为空 | 额外 | 默认值 |
|---|---|---|---|---|---|---|---|
| 1 | o_id |
订单ID | int(11) | PRI | NO | ||
| 2 | o_d_id |
地区ID | int(11) | PRI | NO | ||
| 3 | o_w_id |
仓库ID | int(11) | PRI | NO | ||
| 4 | o_c_id |
客户ID | int(11) | YES | |||
| 5 | o_entry_d |
datetime | YES | ||||
| 6 | o_carrier_id |
int(11) | YES | ||||
| 7 | o_ol_cnt |
int(11) | YES | ||||
| 8 | o_all_local |
int(11) | YES |
6、 order_line:订单记录
| 序号 | 名称 | 描述 | 类型 | 键 | 为空 | 额外 | 默认值 |
|---|---|---|---|---|---|---|---|
| 1 | ol_o_id |
订单ID | int(11) | PRI | NO | ||
| 2 | ol_d_id |
地区ID | int(11) | PRI | NO | ||
| 3 | ol_w_id |
仓库ID | int(11) | PRI | NO | ||
| 4 | ol_number |
数量 | int(11) | PRI | NO | ||
| 5 | ol_i_id |
int(11) | NO | ||||
| 6 | ol_supply_w_id |
int(11) | YES | ||||
| 7 | ol_delivery_d |
datetime | YES | ||||
| 8 | ol_quantity |
int(11) | YES | ||||
| 9 | ol_amount |
decimal(6,2) | YES | ||||
| 10 | ol_dist_info |
char(24) | YES |
7、 stock:库存表
| 序号 | 名称 | 描述 | 类型 | 键 | 为空 | 额外 | 默认值 |
|---|---|---|---|---|---|---|---|
| 1 | s_i_id |
商品ID | int(11) | PRI | NO | ||
| 2 | s_w_id |
仓库ID | int(11) | PRI | NO | ||
| 3 | s_quantity |
数量 | int(11) | YES | |||
| 4 | s_dist_01 |
char(24) | YES | ||||
| 5 | s_dist_02 |
char(24) | YES | ||||
| 6 | s_dist_03 |
char(24) | YES | ||||
| 7 | s_dist_04 |
char(24) | YES | ||||
| 8 | s_dist_05 |
char(24) | YES | ||||
| 9 | s_dist_06 |
char(24) | YES | ||||
| 10 | s_dist_07 |
char(24) | YES | ||||
| 11 | s_dist_08 |
char(24) | YES | ||||
| 12 | s_dist_09 |
char(24) | YES | ||||
| 13 | s_dist_10 |
char(24) | YES | ||||
| 14 | s_ytd |
int(11) | YES | ||||
| 15 | s_order_cnt |
int(11) | YES | ||||
| 16 | s_remote_cnt |
int(11) | YES | ||||
| 17 | s_data |
varchar(50) | YES |
8、 item:商品表
| 序号 | 名称 | 描述 | 类型 | 键 | 为空 | 额外 | 默认值 |
|---|---|---|---|---|---|---|---|
| 1 | i_id |
ID | int(11) | PRI | NO | ||
| 2 | i_im_id |
int(11) | YES | ||||
| 3 | i_name |
商品名 | varchar(24) | YES | |||
| 4 | i_price |
商品价格 | decimal(5,2) | YES | |||
| 5 | i_data |
varchar(50) | YES |
9、 district:地区表
| 序号 | 名称 | 描述 | 类型 | 键 | 为空 | 额外 | 默认值 |
|---|---|---|---|---|---|---|---|
| 1 | d_id |
区域ID | int(11) | PRI | NO | ||
| 2 | d_w_id |
仓库ID | int(11) | PRI | NO | ||
| 3 | d_name |
varchar(10) | YES | ||||
| 4 | d_street_1 |
varchar(20) | YES | ||||
| 5 | d_street_2 |
varchar(20) | YES | ||||
| 6 | d_city |
varchar(20) | YES | ||||
| 7 | d_state |
char(2) | YES | ||||
| 8 | d_zip |
char(9) | YES | ||||
| 9 | d_tax |
decimal(4,4) | YES | ||||
| 10 | d_ytd |
decimal(12,2) | YES | ||||
| 11 | d_next_o_id |
int(11) | MUL | YES |
7、文档连接
TiDB中文简介
TiDB最佳实践等PPT
开源项目地址
TiDB 部署指导
https://docs.pingcap.com/zh/tidb/stable/hardware-and-software-requirements
TiDB整体架构
https://github.com/pingcap/docs-cn/blob/master/overview.md#tidb-%E6%95%B4%E4%BD%93%E6%9E%B6%E6%9E%84
TiDB:入门
https://www.bilibili.com/video/BV1Xz4y1Q79U?from=search&seid=10178516505465195871
prometheus
https://yunlzheng.gitbook.io/prometheus-book/parti-prometheus-ji-chu/promql/prometheus-metrics-types




