万物并育而不相害,道并行而不相悖。
周末到了,你想在线上订购一张期待已久的电影票,选好座位点击确认后,网站却弹出一个窗口,提示你所选择的座位已经被别人预订。工作中,你兴致勃勃地专注于功能开发时,产品经理却过来告诉你,这个需求需要修改。年关将近,你想在线上买一张回家的火车票,却发现早已销售一空。你永远不知道下一刻会发生什么,因为现实世界是并发的。
计算机是为人类提供服务的,也必须具备这种并发处理能力。在多道程序系统还未被支持的计算机发展早期,程序员就面临着一种尴尬:编写好的程序上机运行必须要排队。相比之下,现代计算机时代的程序员就幸运多了,可以在写代码的同时听音乐,在听音乐的同时使用搜索引擎来查阅各种资料。
在现实世界中,电影座位可以重新选择一个,火车票也可以重新选择另外一天的,开发流程可以重新修正,并发造成的结果是可以承受的。但是在计算机世界中,并发则可能会造成恶劣的影响。比如,提供电影票预订服务的手机App,允许两个人同时预订同一个场次的同一个座位,这恐怕会引起纠纷。你可能会想,为什么会出现这种情况?如何避免?这正是本章接下来要探讨的内容。
11.1 通用概念
并发(Concurrency)的概念很容易和并行(Parallelism)混淆,事实上它们是不同的概念。
谷歌著名工程师罗布·派克(Rob Pike)说过,“并发就是同时应对(Dealing With)多件事情的能力,并行是同时执行(Doing)多件事情的能力”。这句话非常透彻地阐述了并发和并行的区别,在于“应对”和“执行”。
如果你在吃饭的时候观察一下餐馆中的某个服务员,你会发现他一会帮顾客点单,一会要端茶倒水,一会又要收钱,甚至有可能要去厨房催菜,这些事情表现起来像是同时发生的。其实服务员只是把这些事情切分成一个个小任务,将它们分配在不同的时间片内,交替完成。这就是并发,关注点在于任务的切分,这是一种逻辑架构、一种能力。将视角从某个固定的服务员移到其他不同的服务员,你会发现他们做的事情是类似的,但他们每一个人都是这些事情执行的个体,相互无影响,各自独立完成自己的工作。这就是并行,关注点在于同时执行,这是具体的实施状态。并发并不要求一定要并行,利用并发可以制造出并行的假象。
图11-1展示了并发和并行的区别。
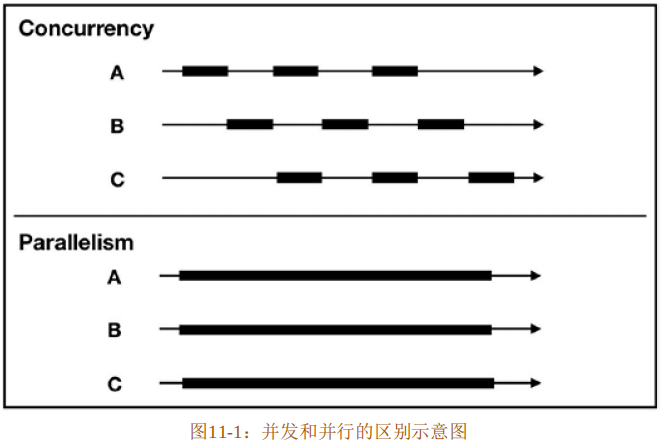
在实际编程中,对任务进行分解才是重点,一旦将任务分解正确,到了执行层面,并行就会自然发生,也容易保证正确性。如何分解任务是并发设计要解决的问题,所以,通常更关注并发而非并行。
使用并发主要出于两个主要原因:性能和容错。
随着多核计算机的普及,为了利用其日益增长的计算能力,就必须要编写并发程序。并发编程越来越受重视,甚至可能成为一种新的编程范式,Go语言的横空出世就证明了这一点。另外,并发编程还可以将程序分为不同的功能区域,让程序更容易理解和测试,从而减少程序出错的可能性。
在计算机中,通常使用一些独立的运行实体对并发进行支持,分为如下两类:
- 操作系统提供的进程和线程。
- 编程语言内置的用户级线程。
11.1.1 多进程和多线程
进程是资源分配的最小单元,线程是程序执行时的最小单元。
- 从操作系统的角度来看,进程代表操作系统分配的内存、CPU时间片等资源的基本单位,它为程序提供基本的运行环境。不同的应用程序可以按业务划分为不同的进程。
- 从用户的角度来看,进程代表运行中的应用程序,它是动态条件下由操作系统维护的资源管理实体,而非静态的应用程序文件。每个进程都享有自己独立的内存单元,从而极大地提高了程序的运行效率。
可以使用多进程来提供并发,比如 Master-Worker 模式(filecoin: lotus、miner、worker),由 Master进程来管理 Worker子进程,Worker子进程执行任务。Master和Worker之间通常使用Socket来进行进程间通信(IPC)。这样的好处就是具有极高的健壮性,当某个Worker子进程出现问题时,不会影响到其他子进程。但缺点也非常明显,其中最让人诟病的是进程会占用相当可观的系统资源。除此之外,进程还有切换复杂、CPU利用率低、创建和销毁复杂等缺点。
为了寻求比进程更小的资源占用,线程应运而生。线程是进程内的实体,它无法独立存在,必须依靠进程,线程的系统资源都来源于进程,包括内存。
- 每个进程至少拥有一个线程,这个线程就是主线程。
- 每个进程也可以生成若干个线程来并发执行多任务,但只能有一个主线程,线程和线程之间可以共享同一个进程内的资源。
- 一个线程也可以创建或销毁另一个线程,所以线程会有创建、就绪、运行、阻塞和死亡五种状态。
- 每个线程也有自己独享的资源,比如线程栈。
- 线程和进程一样,都受操作系统内核的调度。
- 线程拥有进程难以企及的优点,比如占用内存少,切换简单,CPU利用率高,创建/销毁简单、快速等。
- 线程的缺点也是非常明显的,比如编程相当复杂,调试困难等。正是由于这些缺点,导致多线程并发编程成为众多开发者心中的痛。
11.1.2 事件驱动、异步回调和协程
多线程虽然比多进程更省资源,但其依然存在昂贵的系统内核调度代价。互联网的发展让这个问题更加突出。在服务器领域有一个非常出名的C10K问题,主要是指单台服务器要同时处理10K量级的并发连接,解决此问题最直接的就是多进程(线程)并发,每个进程(线程)处理一个连接。但是,这种处理方式显然是有问题的,因为服务器根本没有这么多资源可以分配给如此多的进程(线程)。
为了解决C10K问题,事件驱动编程应运而生,最知名的就是Linux推出的epoll技术。事件驱动也可以称为事件轮询,它的优点在于编程更加容易,不用做并发设计的考虑,不需要引入锁,不需要考虑内部调度,只需要依赖于事件,最重要的是不会阻塞。所以它可以很方便地和编程语言相集成,比如Node.js,也就是第一个事件驱动编程模型语言。在 Node.js中,仅仅使用单线程就可以拥有强大的并发处理能力,其力量来源就是事件驱动和异步回调(Callback)。通过内置的事件循环机制,不断地从事件队列中查询是否有事件发生,当读取到事件时,就会调用和此事件关联的回调函数,整个过程是非阻塞的。
事件驱动和回调函数虽然解决了C10K的问题,但是对于开发者来说还远远没有那么完美。问题就出在回调函数上面,如果编写业务比较复杂的代码,开发者将陷入“回调地狱(Call Hell)”中,代码中充斥着各种回调嵌套,很快就会变成一团乱麻。回调函数的这种写法,并不符合人类的思维直觉,所以使用起来比较痛苦。
为了避免“回调地狱”,不停地有新方案被提出,比如Promise和Future,这两种方案从不同的角度来处理回调函数。Promise 站在任务处理者的角度,将异步任务完成或失败的状态标记到 Promise 对象中。Future 则站在任务调用者的角度,来检测任务是否完成,如果完成则直接获取结果,如果未完成则阻塞直到获取到结果,或者编写回调函数避免阻塞,根据相应的完成状态执行此回调函数。虽然Promise和Future可以进一步缓解回调函数的问题,但它们还是不够完美,代码中依然充斥着各种冗余。
为了进一步完善基于事件驱动的编程体验,一种叫作协程的解决方案浮出水面。协程的概念很古老,甚至可以追溯到20世纪60年代的COBOL语言,但是因为时代使然,协程并未成为像线程那样的通用编程元素。然而,随着事件编程的兴起,协程又有了用武之地。
协程为协同任务提供了一种抽象,这种抽象本质上就是控制流的出让和恢复。协程的这种机制,正好符合现实世界中人类异步处理事务的直觉。比如,程序员可以暂停自己写代码的过程,进行场景切换,去参加产品经理组织的会议,当会议结束后,再切换回之前的场景继续编写代码。虽然处理了不同的事件,但对于程序员来说,都是顺序执行的。可以看出,协程和事件驱动属于绝配。当事件来临时,出让当前的控制权,切换场景,完成该事件,然后再切换回之前的场景,恢复之前的工作。如果说事件驱动编程和异步回调是站在事件发生的角度进行编程的,那么协程就是站在开发者的角度来进行编程的。开发者将自身代入各种事件中,看上去就是顺序执行的。总的来说,协程可以让开发者用写同步(顺序)代码的方式编写可异步执行的代码。
在现代编程语言中,实现协程的方法有很多,但其中的区别只在于是否有适合的应用场景。常见的有Go语言的go协程(goroutines)、Erlang语言的轻量级进程(LWP)。另外,像Python、Ruby、JavaScript这样的主流编程语言也实现了协程,当然Rust语言也支持协程。协程是以线程为容器的,协程的特点是内存占用比线程更小、上下文切换的开销更小、没有昂贵的系统内核调度,这也意味着协程的运行效率更加高效。协程非常轻量,也被称为用户态线程,所以可大量使用。但协程也不是“银弹”,它虽然充分挖掘了单线程的利用率,在单线程下可以处理高并发I/O,但却无法利用多核。
图11-2展示了进程、线程和协程之间的关系。

当然,可以将协程和多线程配合使用,来充分利用多核。但是,从单线程迁移到多线程并不会只带来好处,它也会带来更多的风险。
11.1.3 线程安全
线程其实是对底层硬件运行过程的直接抽象,这种抽象方式既有优点又有缺点。
- 优点在于很多编程语言都对其提供了支持,并且没有对其使用方式加以限制,开发者可以自由地实现多线程并发程序,充分利用多核。
- 缺点包含两个方面:一方面,线程的调度完全由系统内核来控制,完全随机,这就导致多个线程的运行顺序是完全无法预测的,有可能产生奇怪的结果;另一方面,编写正确的多线程并发程序对开发者的要求太高,对多线程编程没有充足知识储备的开发者很容易写出满是Bug的多线程代码,并且还很难重现和调试。
多线程存在问题主要是因为资源共享,比如共享内存、文件、数据库等。实际上,只有当一个或多个线程对这些资源进行写操作时才会出现问题,如果只读不写,资源不会发生变化,自然也不会存在安全问题。假如一个方法、数据结构或库在多线程环境中不会出现任何问题,则可以称之为线程安全。所以,多线程编程的重点就是如何写出线程安全的代码。
(1)竞态条件与临界区
要想写出线程安全的代码,必须先了解安全的边界在哪里。代码清单11-1展示了一个线程不安全的函数示例。
代码清单11-1:线程不安全的函数示例
static mut V: i32 = 0;
fn unsafe_seq() -> i32 {
unsafe {
V += 1;
V
}
}在代码清单11-1所展示的示例中,首先初始化了一个可变的静态变量V。在unsafe_seq函数中通过“+=”操作来改变V的值。因为在Rust中默认不允许修改静态变量的值,所以需要在unsafe块中进行操作。
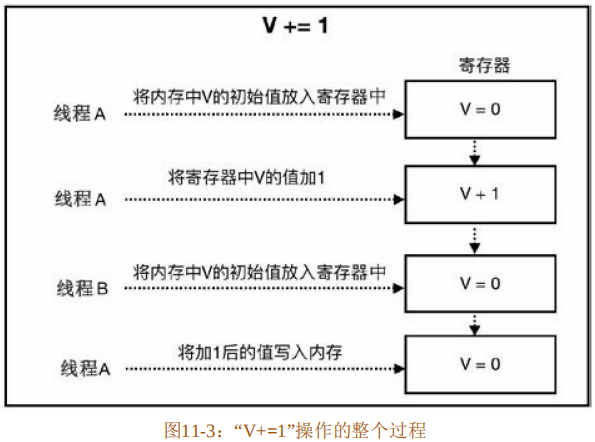
在单线程环境中,unsafe_seq 函数不会有任何问题,但是将其放到多线程环境中,则会有问题。问题主要出在代码第4行的“V+=1”操作上。实际上,该操作在运行过程中并非单个指令,而是可以分为三步:
(1)从内存中将V的初始值放入寄存器中。
(2)将寄存器中V的值加1。
(3)将加1后的值写入内存。
这三步操作无法保证在同一个线程中被一次执行完成。因为系统内核调度的存在,很有可能在线程A执行第2步操作之后,从线程A切换到了线程B,而线程B此时并不知道线程A已经执行了第1步操作,它又重复将V的初始值放入寄存器中,当又切换回线程A后,线程A会继续执行第3步操作,此时就从寄存器中读取了错误的值。
“V+=1”操作的整个过程如图11-3所示。
代码清单11-1展示了一种常见的并发安全问题,叫作竞态条件(Race Condition)。当某个计算的正确性取决于多个线程交替执行的顺序时,就会产生竞态条件。也就是说,想计算出正确的结果,全靠运气。最常见的竞态条件类型是“读取-修改-写入”和“先检查后执行”操作。代码清单11-1展示的就是“读取-修改-写入”竞态条件;而“先检查后执行”竞态条件则出现在需要判断某个条件为真之后才采取相应的动作时。产生竞态条件的区域,就叫作临界区。
在代码清单11-1中展示的代码也同时引起了数据竞争(Data Race)。“数据竞争”这个术语很容易和竞态条件相混淆。当一个线程写一个变量而另一个线程读这个变量时,如果这两个线程没有进行同步,则会发生数据竞争。因为竞态条件的存在,读操作很可能在写操作之前就完成了,那么读到的数据就是错误的。并非所有的竞态条件都是数据竞争,也并非所有的数据竞争都是竞态条件。
简单来说,当有多个线程对同一个变量同时进行读写操作,且至少有一个线程对该变量进行写操作时,则会发生数据竞争。也就是说,如果所有的线程都是进行读操作,则不会发生数据竞争。数据竞争的后果会造成该变量的值不可知,多线程程序的运行结果将完全不可预测,甚至直接崩溃。
而竞态条件是指代码受多线程乱序执行的影响,运行结果产生预料之外的变化。比如对于同一段程序,多次运行会产生不同的结果,完全无法预测,它由输入的数据和多线程执行的顺序决定。
现在用一个银行转账的示例来具体说明竞态条件和数据竞争的区别。代码清单11-2展示的伪代码为用于转账操作的函数trans1。
代码清单11-2:用于转账操作的函数
trans1(amount, account_from, account_to) {
if (account_from.blance < amount) return FALSE;
account_to.balance += amount;
account_from.balance -= amount;
return TRUE;
}在多线程环境中,这个伪代码示例既包含了竞态条件,又包含了数据竞争,转账结果将不可预测。为了解决该问题,采用某种同步操作,比如使用互斥量(Mutex)或某种禁用中断操作的事务,将包含数据竞争的操作变为原子性操作,如代码清单11-3所示。
代码清单11-3:改进转账操作的函数
trans2(amount, account_from, account_to) {
atomic { bal = account_from.balance; }
if (bal < amount) return FALSE;
atomic { account_to.balance += amount; }
atomic { account_from.balance -= amount; }
return TRUE;
}在代码清单 11-3 中使用的 atomic 块,表示将其范围内的操作变为原子性的某种手段。总之,现在数据竞争被消除了。但还存在竞态条件,不同的线程依然可以乱序执行代码第 4行和第5行的操作。整个交易函数trans2的正确性,在不同的线程执行顺序之下,会出现不同的结果。所以还需要继续对其改进,如代码清单11-4所示。
代码清单11-4:继续改进转账操作的函数
trans3(amount, account_from, account_to) {
atomic {
if (account_from.balance < amount) return FALSE;
account_to.balance += amount;
account_from.balance -= amount;
return TRUE;
}
}在trans3函数中,通过atomic块将整个函数的执行过程赋予原子性,这样就完全消除了数据竞争和竞态条件。可以看出,消除竞态条件的关键在于判断出正确的临界区。
还可以对其进一步改进,创建一个有数据竞争但无竞态条件的函数,如代码清单11-5所示。
代码清单11-5:进一步改进转账操作的函数
trans4(amount, account_from, account_to) {
account_from.activity = true;
account_to.activity = true;
atomic {
if (account_from.balance < amount) return FALSE;
account_to.balance += amount;
account_from.balance -= amount;
return TRUE;
}
}在trans4函数中增加了两行伪代码,如代码第2行和第3行所示,这两行代码表示这两个账号上会出现某些状态变更的行为。这两行代码会出现数据竞争,但不存在竞态条件。但这里的数据竞争并不会影响到交易行为的正确性,所以是无害的。
通过上面的四段伪代码,刻意区分了数据竞争和竞态条件之间的区别。在多线程编程中,数据竞争是最常见、最严重、最难调试的并发问题之一,可能会引起崩溃或内存不安全。
接下来看看Rust 多线程代码实际产生竞态条件和数据竞争问题的例子。代码清单11-6展示了在多线程环境中使用unsafe_seq函数的情形。
代码清单11-6:在多线程环境中使用unsafe_seq函数
use std::thread;
static mut V: i32 = 0;
fn unsafe_seq() -> i32 {
unsafe {
V += 1;
V
}
}
fn main() {
let child = thread::spawn(move || {
for _ in 0..10 {
unsafe_seq();
unsafe{println!("child: {}", V);}
}
});
for _ in 0..10 {
unsafe_seq();
unsafe{println!("main: {}", V);}
}
child.join().unwrap();
}在代码清单11-6中,使用std::thread模块中提供的spawn方法在main主线程中生成子线程child,并在其中循环使用unsafe_seq函数,如代码第10~15行所示。同样,在main主线程中也循环使用unsafe_seq函数,如代码第16~19行所示。最后在代码第20行,调用child子线程的join方法,让主线程等待子线程执行完再退出。
在正常情况下,对该段代码进行编译执行,期待的输出结果是main主线程和child子线程一共输出从 0 到 20 的数字。但实际执行多次会看到不同的输出结果,基本会出现以下两种情况:
- 在main主线程输出的结果中会莫名其妙地少一位,并不是从0到10的连续值。
- child子线程输出的结果和main主线程输出的结果有重复。
可以看出,该段代码在多线程环境中的行为和结果完全无法预测,完全无法保证正确性。
(2)同步、互斥和原子类型
综上所述,产生竞态条件主要是因为线程乱序执行,发生数据竞争主要是因为多线程同时对同一块内存进行读写。那么,要消除竞态条件,只需要保证线程按指定顺序来访问即可。要避免数据竞争,只需要保证相关数据结构操作的原子性即可。所以,很多编程语言都通过提供同步机制来消除竞态条件,使用互斥和原子类型来避免数据竞争。
- 同步是指保证多线程按指定顺序执行的手段。
- 互斥是指同一时刻只允许单个线程对临界资源进行访问,对其他线程具有排他性,线程之间的关系表现为互斥。
- 原子类型是指修改临界数据结构的内部实现,确保对它们做任何更新,在外界看来都是原子性的,不可中断。
通常可以使用锁、信号量(Semaphores)、屏障(Barrier)和条件变量(Condition Variable)机制来实现线程同步。根据不同的并发场景分为很多不同类型的锁,有互斥锁(Mutex)、读写锁(RwLock)和自旋锁(Spinlock)等。锁的作用是可以保护临界区,同时达到同步和互斥的效果。
不同的锁表现不同:
- 互斥锁,每次只允许单个线程访问临界资源;
- 读写锁可以同时支持多个线程读或单个线程写;
- 自旋锁和互斥锁类似,但当获取锁失败时,它不会让线程睡眠,而是不断地轮询直到获取锁成功。
信号量可以在线程间传递信号,也叫作信号灯,它可以为资源访问进行计数。信号量是一个非负整数,所有通过它的线程都会将该整数减1,如果信号量为 0,那么其他线程只能等待。当线程执行完毕离开临界区时,信号量会再次加1。当信号量只允许设置0和1时,效果相当于互斥锁。
屏障可以让一系列线程在某个指定的点进行同步。通过让参与指定屏障区域的线程等待,直到所有参与线程都到达指定的点。而条件变量用来自动阻塞一个线程,直到出现指定的条件,通常和互斥锁配合使用。
通过一些锁机制,比如互斥锁,也可以用来避免数据竞争。本质上,是通过锁来保护指定区域的原子性的。有些语言也提供了原子类型来保证原子性,比如Java、C++以及Rust。具有原子性的操作一定是不可分割的,要么全部完成,要么什么都不做。原子类型使用起来简单,但其背后的机制却一点也不简单,了解其背后的机制有助于更好地使用原子类型。
11.2 多线程并发编程
Rust为开发者提供的并发编程工具和其他语言类似,主要包括如下两个方面:
- 线程管理,在std::thread模块中定义了管理线程的各种函数和一些底层同步原语。
- 线程同步,在std::sync模块中定义了锁、Channel、条件变量和屏障。
11.2.1 线程管理
Rust中的线程是本地线程,每个线程都有自己的栈和本地状态。创建一个线程很简单,如代码清单11-7所示。
代码清单11-7:创建线程
use std::thread;
fn main() {
let mut v = vec![];
for id in 0..5 {
let child = thread::spawn(move || {
println!("in child: {}", id);
});
v.push(child);
}
println!("in main: join before");
for child in v {
child.join();
}
println!("in main: join after");
}在代码清单11-7中,必须使用use导入std::thread模块使用线程创建的函数spawn。代码第3行,初始化了一个可变的动态数组v,用于存放生成的子线程。
代码第4~9行,使用for循环迭代生成5个子线程,并将其存放到数组v中。其中代码第5~7行,使用spawn函数创建子线程,接收一个闭包作为参数,并且该闭包需要捕获循环变量id,默认是按引用来捕获的。但这里涉及生命周期的问题,传递给子线程的闭包有可能存活周期长于当前函数,如果直接传递引用,则可能引起悬垂指针的问题,这是Rust绝对不允许的。所以,这里使用move关键字来强行将捕获变量id的所有权转移到闭包中。
代码第 11~13 行,对数组 v 进行迭代,调用其中每一个子线程的join 方法,就可以让main主线程等待这些子线程都执行完毕。代码第10行和第14行,分别在子线程join的前后打印相应的信息。
可以对该段代码进行多次编译执行,代码清单11-8展示了其中某次执行的结果。
代码清单11-8:执行结果
in child: 3
in child: 1
in child: 2
in child: 0
in main: join before
in child: 4
in main: join after通过对比多次执行的结果可以看出,main主线程和子线程永远是乱序执行的,“in main:join before”的输出位置并不固定,但是“in main:join after”的位置是固定的,永远在结尾。
假如在代码清单11-7中不使用join方法,main主线程并不会等待子线程执行完毕,那么编译执行的结果就会变得更加难以预料。首先可以确定的是,在 main 主线程中打印的两条信息永远会输出,但是在子线程中打印的结果就不一定了。因为乱序执行的存在,有时候能看到一个子线程的输出,有时候能看到三个子线程的输出,有时候完全看不到,完全无法预料,因为谁也无法保证子线程一定会比main线程先执行完毕。
所以,如果想要多个线程协作,则通常会使用join方法来指定一个线程等待其他线程执行完之后再执行它自己的任务。线程join机制示意图如图11-5所示。
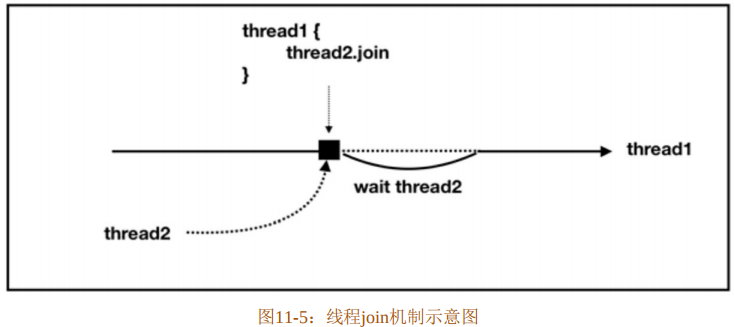
从图11-5中可以看出,如果在thread1中调用thread2的join方法,则thread1就会在调用join方法的那一刻等待thread2,并且阻塞自身,只有thread2执行完毕后才继续执行thread1中的任务。这也就是在代码清单11-8中“in main:join after”输出永远在最后的原因。
(1)定制线程
直接使用thread::spawn生成的线程,默认没有名称,并且其栈大小默认为2MB。如果想为线程指定名称或者修改默认栈大小,则可以使用 thread::Builder 结构体来创建可配置的线程,如代码清单11-9所示。
代码清单11-9:使用thread::Builder来定制线程
use std::panic;
use std::thread::{Builder, current};
fn main() {
let mut v = vec![];
for id in 0..5 {
let thread_name = format!("child-{}", id);
let size: usize = 3 * 1024;
let builder = Builder::new()
.name(thread_name).stack_size(size);
let child = builder.spawn(move || {
println!("in child: {}", id);
if id == 3 {
panic::catch_unwind(|| {
panic!("oh no!");
});
println!("in {} do sm", current().name().unwrap());
}
}).unwrap();
v.push(child);
}
for child in v {
child.join().unwrap();
}
}代码清单11-9是对代码清单11-7的部分修改,使用thread::Builder来定制新的线程。代码第6行和第7行,分别声明了线程的名称和栈大小。代码第8行和第9行,通过Builder::new方法来生成新的 Builder 实例,然后分别将事先声明好的名称和栈大小参数传入 name 和stack_size方法中,就可以生成指定名称和栈大小的线程。这里值得注意的是,主线程的大小与Rust语言无关,这是因为主线程的栈实际上就是进程的栈,由操作系统来决定。修改所生成线程的默认值也可以通过指定环境变量RUST_MIN_STACK来完成,但是它的值会被Builder::stack_size覆盖掉。代码第10行,调用builder.spawn方法来生成线程,该spawn方法是Builder实例的方法,与thread::spawn函数不一样。实际上,在thread::spawn内部也是使用Builder来生成默认配置的线程的。
代码第12~17行,特意在第三个线程中使用panic!来产生恐慌,并且使用catch_unwind来捕获恐慌。在 catch_unwind 之后,再次输出一些特定信息。其中代码第 16 行使用了thread::current函数来获取当前线程。
注意代码第18行,在spawn方法结尾处又调用了unwrap方法。实际上,之前thread::spawn方法返回的是JoinHandle<T>类型,而Builder的spawn方法返回的是Result<JoinHandle<T>>类型,所以这里需要加unwrap方法。JoinHandle<T>代表线程与其他线程join的权限。
代码清单11-9执行的结果如代码清单11-10所示。
代码清单11-10:执行结果
thread `child-3` panicked at `oh no!`, src/main.rs:14:24 note: Run with `RUST_BACKTRACE=1` for a backtradce.
in child: 1
in child: 0
in child: 2
in child: 4
in child: 3
in child-3 do sm从代码清单11-10中可以看出,为线程指定的名称可以在线程发生恐慌时显示出来,此处为“child-3”。如果不给线程指定名称,则默认显示“unknow”。该正常输出的信息也都输出了,说明child-3线程中的恐慌已经被捕获,线程得以恢复。
(2)线程本地存储
线程本地存储(Thread Local Storage,TLS)是每个线程独有的存储空间,在这里可以存放其他线程无法访问的本地数据,如代码清单11-11所示。
代码清单11-11:线程本地存储示例
use std::cell::RefCell;
use std::thread;
fn main() {
thread_local!(static FOO: RefCell<u32> = RefCell::new(1));
FOO.with(|f| {
assert_eq!(*f.borrow(), 1);
*f.borrow_mut() = 2;
});
thread::spawn(|| {
FOO.with(|f| {
assert_eq!(*f.borrow(), 1);
*f.borrow_mut() = 3;
});
});
FOO.with(|f| {
assert_eq!(*f.borrow(), 2)
});
}在代码清单11-11中,代码第4行,使用thread_local!宏以一个类型为RefCell<u32>并且初始值为1的静态变量FOO作为参数,最终会生成类型为thread::LocalKey的实例FOO。为了提供内部可变性,有时候thread_local!宏会配合Cell和RefCell一起使用。
thread::LocalKey 是一个结构体,它提供了一个 with 方法,可以通过给该方法传入闭包来操作线程本地存储中包含的变量。如代码第5~8行所示,首先判断初始值是否为1,然后通过调用borrow_mut方法将线程本地存储内部的值修改为2。
代码第9~14行,生成了子线程,并且该子线程也有一个线程本地存储实例FOO,初始值为1。当然,也可以通过thread_local!宏在该子线程中重新创建一个LocalKey实例。但是本例中还是使用来自main主线程的FOO副本。代码第11行和第12行,首先验证FOO初始值,然后将它的值改为3。
代码第 15~17 行,主要用来判断主线程中的线程本地存储实例FOO 内部的值有没有发生变化。通过编译执行该段代码,可以得知,main主线程中的线程本地存储实例FOO内部的值并没有因为子线程中的修改而发生变化。在标准库中很多数据结构实现都使用了thread_local!宏来定义单个线程内的一些独享数据,比如映射类型HashMap。
(3)底层同步原语
在std::thread模块中还提供了一些函数,用来支持底层同步原语,主要包括park/unpark和yield_now函数。 std::thread::park函数提供了阻塞线程的基本能力,而std::thread::Thread::unpark函数可以将阻塞的线程重启。可以利用 park和 unpark 函数来方便地创建一些新的同步原语,比如某种锁。但要注意park函数并不能永久地阻塞线程,也可以通过std::thread::park_timeout来显式指定阻塞超时时间。
代码清单11-12展示了park和unpark函数的用法。
代码清单11-12:park和unpark函数使用示例
use std::thread;
use std::time::Duration;
fn main() {
let parked_thread = thread::Builder::new()
.spawn(|| {
println!("Packing thread");
thread::park();
println!("Thread unparked");
}).unwrap();
thread::sleep(Duration::from_millis(10));
println!("Unpark the thread");
parked_thread.thread().unpark();
parked_thread.join().unwrap();
}在代码清单11-12中引入了std::time模块,其中的Duration类型专门用于表示系统超时,默认new方法生成以纳秒(ns)为时间单位的实例,但是也提供了from_secs和from_millis方法分别生成以秒(s)和毫秒(ms)为时间单位的实例。
代码第4~9行,通过Builder来生成线程,并在该线程传递的闭包中调用thread::park函数,目的在于阻塞该线程。
代码第10行,使用thread::sleep函数让主线程睡眠10ms。等待子线程parked_thread生成完毕,目的在于让子线程能先打印出相关的信息。但值得注意的是,千万不要使用sleep来进行任何线程同步的操作,它并不会保证线程执行的顺序。
代码第12行,通过调用parked_thread的thread方法从JoinHandle中得到具体的线程,然后调用unpark函数,就可以将处于阻塞状态的parked_thread线程重启,该线程会继续沿着之前暂停的上下文开始执行。
代码清单11-12的执行结果如代码清单11-13所示。
代码清单11-13:执行结果
Parking thread
Unpark the thread
Thread unparked可以看出,thread::sleep函数起作用了,首先输出的是子线程parked_thread 阻塞前的打印信息,之后调用到thread::park函数,线程就会发生阻塞。接下来轮到main主线程开始执行,打印出“Unpark the thread”之后,获取parked_thread线程并执行unpark方法将其重启。最后通过join方法等待parked_thread线程执行完毕,输出最终结果。
除了阻塞/重启的同步原语,std::thread 模块还提供了主动出让当前线程时间片的函数yield_now。众所周知,操作系统是抢占式调度线程的,每个线程都有固定的执行时间片,时间片是由操作系统切分好的,以便每个线程都可以拥有公平使用CPU的机会。但是有时开发者明确知道某个线程在一段时间内会什么都不做,为了节省计算时间,可以使用 yield_now函数主动放弃当前操作系统分配的时间片,让给其他线程执行。
11.2.2 Send和Sync
从Rust提供的线程管理工具来看,并没有发现什么特殊的地方,和传统语言的线程管理方式非常相似。那么,Rust 是如何做到之前宣称的那样默认线程安全的呢?这要归功于std::marker::Send和std::marker::Sync两个特殊的内置trait。Send和Sync被定义于std::marker模块中,它们属于标记trait,其作用如下:
- 实现了Send的类型,可以安全地在线程间传递所有权。也就是说,可以跨线程移动。
- 实现了Sync的类型,可以安全地在线程间传递不可变借用。也就是说,可以跨线程共享。
这两个标记trait反映了Rust看待线程安全的哲学:多线程共享内存并非线程不安全问题所在,问题在于错误地共享数据。通过Send和Sync将类型贴上“标签”,由编译器来识别这些类型是否可以在多个线程之间移动或共享,从而做到在编译期就能发现线程不安全的问题。和Send/Sync相反的标记是!Send/!Sync,表示不能在线程间安全传递的类型。
我们来观察std::thread::spawn函数的源码实现,如代码清单11-14所示。
代码清单11-14:spawn函数的源码实现
pub fn spawn<F, T>(f: F) -> JoinHandle<T> where
F: FnOnce() -> T, F: Send + 'static, T: Send + 'static
{
Builder::new().spawn(f).unwrap()
}在代码清单11-14中,spawn函数中的闭包F与闭包的返回类型T都被加上了Send和'static限定。其中Send限定了闭包的类型以及闭包的返回值都必须是实现了Send的类型,只有实现了 Send 的类型才可以在线程间传递。而闭包的类型是和捕获变量相关的,如果捕获变量的类型实现了Send,那么闭包就实现了Send。
而'static限定表示类型T只能是非引用类型(除&'static之外)。其实这个很容易理解,闭包在线程间传递,如果直接携带了引用类型,生命周期将无法保证,很容易出现悬垂指针,造成内存不安全。这是Rust绝对不允许出现的情况。
既然不允许在线程间直接传递引用,那么如何才能在多个线程之间安全地共享变量呢?如果是不可变的变量,则可以通过Arc<T>来共享。Arc<T>是Rc<T>的线程安全版本,因为在 Rc<T>内部并未使用原子操作,所以在多个线程之间共享会出现安全问题;而在 Arc<T>内部使用了原子操作,所以默认线程安全。
代码清单11-15展示了为Arc<T>实现Send和Sync。
代码清单11-15:为Arc<T>实现Send和Sync
unsafe impl<T: ?Sized + Sync + Send> Send for Arc<T> {}
unsafe impl<T: ?Sized + Sync + Send> Sync for Arc<T> {}可以看出,只要T是实现了Send和Sync的类型,那么Arc<T>也会实现Send和Sync。值得注意的是,Send和Sync这两个trait是unsafe的,这意味着如果开发者为自定义类型手动实现这两个trait,编译器是不保证线程安全的。实际上,在Rust标准库std::marker模块内部,就为所有类型默认实现了Send和Sync,换句话说,就是为所有类型设定好了默认的线程安全规则,如代码清单11-16所示。
代码清单11-16:在标准库内部默认为所有类型实现了 Send和Sync
unsafe impl Send for .. { }
impl<T: ?Sized> !Send for *const T { }
impl<T: ?Sized> !Send for *mut T { }
unsafe impl Sync for .. { }
impl<T: ?Sized> !Sync for *const T { }
impl<T: ?Sized> !Sync for *mut T { }
mod impls {
unsafe impl<'a, T: Sync + ?Sized> Send for &'a T {}
unsafe impl<'a, T: Send + ?Sized> Send for &'a mut T {}
}在代码清单11-16中,代码第1行和第4行使用了一种特殊的语法,分别表示为所有类型实现了Send和Sync。这里要注意Send和Sync本身只是标记trait,没有任何默认的方法。如果想使用第1行和第4行这样的语法,必须满足两个条件:
- impl和trait必须在同一个模块中。
- 在该trait内部不能有任何方法。
代码第2行和第3行以及代码第5行和第6行,分别为*const T和*mut T类型实现了!Send和!Sync,表示实现这两种trait的类型不能在线程间安全传递。
代码第7~10行,分别为&'a T和&'a mut T实现了Send,但是对T的限定不同。&'a T要求T必须是实现了Sync的类型,表示只要实现了Sync的类型,其不可变借用就可以安全地在线程间共享;而&'a mut T要求T必须是实现了Send的类型,表示只要实现了Send的类型,其可变借用就可以安全地在线程间移动。
除在std::marker模块中标记的上述未实现Send和Sync的类型之外,在其他模块中也有。比如Cell和RefCell都实现了!Sync,表示它们无法跨线程共享;再比如Rc实现了!Send,表示它无法跨线程移动。
通过Send和Sync构建的规则,编译器就可以方便地识别线程安全问题。代码清单11-17展示了在线程间传递可变字符串。
代码清单11-17:在线程间传递可变字符串
use std::thread;
fn main() {
let mut s = "Hello".to_string();
for _ in 0..3 {
thread::spawn(move || {
s.push_str(" Rust!");
});
}
}代码清单11-17展示的示例是在多个线程中在字符串s尾部追加字符串。该段代码存在数据竞争隐患。虽然当前示例内容不会有什么危害,但是多个线程对同一个可变变量进行写操作比较危险。对此段代码进行编译,编译器会报出如下错误:
error[E0382]: capture of moved value: `s`
5 | thread::spawn(move || {
| ------- value moved (into closure) here
6 | s.push_str(" hello");
| ^ value captured here after move错误信息提示使用了所有权已经被移动的值 s,违反了 Rust 所有权机制。在这里 Rust所有权机制帮助发现了一个潜在的风险。
如果想在多个线程中共享s,则需要使用Rc或Arc。现在已经知道Rc实现了!Send,但是可以尝试使用它跨线程共享所有权,看看会发生什么情况,如代码清单11-18所示。
代码清单11-18:尝试使用Rc共享所有权
use std::thread;
use std::rc::Rc;
fn main() {
let mut s = Rc::new("Hello".to_string());
for _ in 0..3 {
let mut s_clone = s.clone();
thread::spawn(move || {
s_clone.push_str(" hello");
});
}
}在代码清单11-18中使用Rc包装了变量s,然后在迭代中使用clone方法来共享所有权。编译该段代码,编译器会报出如下错误:
error[E0277]: the trait bound `std::rc::Rc<std::string::String>:
std::marker::Send` is not satisfied in `[closure@src/main.rs:
7:23: 9:10 s_clone::std::rc::Rc<std::string::String>]`
7 | thread::spawn(move || {
| ^^^^^^^^^^^^^^ `std::rc::Rc<std::string::String>` cannot be send between threads safely通过错误信息可知,spawn函数传入的闭包没有实现Send,这是因为捕获变量没有实现Send。捕获变量是Rc<String>类型,实现的是!Send,正好和Send相反。同时,错误信息最后一句也提示了Rc<String>不能在线程间进行安全移动。这是因为Rc<T>底层不是原子操作,有可能发生多个线程同时修改引用计数器的情况,存在数据竞争。编译器又一次发现了线程不安全的隐患。
既然Rc<T>不行,那么就换成可以在多线程间被移动和共享的Arc<T>,如代码清单11-19所示。
代码清单11-19:使用Arc共享所有权
use std::thread;
use std::sync::Arc;
fn main() {
let s = Arc::new("Hello".to_string());
for _ in 0..3 {
let s_clone = s.clone();
thread::spawn(move || {
s_clone.push_str(" world!");
});
}
}在代码清单11-19中,使用Arc替换了Rc,但是编译时还是会报出如下错误:
error[E0596]: cannot borrow immutable borrowed content as mutable
8 | s_clone.push_str(" world!");
| ^^^^^^^ cannot borrow as mutable该错误信息表明,把不可变借用当作可变借用,这是因为 Arc<T>默认是不可变的。如果想完成目标,还需要使用具备内部可变性的类型,比如Cell、RefCell等。现在我们已经知道,Cell和RefCell均是线程不安全的容器类型,它们实现了!Sync,无法跨线程共享。代码清单11-20展示了使用RefCell来支持内部可变性。
代码清单11-20:使用RefCell支持内部可变性
use std::thread;
use std::sync::Arc;
use std::cell::RefCell;
fn main() {
let s = Arc::new(RefCell::new("Hello".to_string()));
for _ in 0..3 {
let s_clone = s_clone();
thread::spawn(move || {
let s_clone = s_clone.borrow_mut();
s_clone.push_str(" world!");
});
}
}在代码清单11-20中,使用RefCell来提供内部可变性,但是编译时依旧会报出如下错误:
error[E0277]: the trait bound `std::cell::RefCell<std::string::String>:std::marker::Sync` is not satisfied
8 | thread::spawn(move || {
| ^^^^^^^^^^^^^^ `std::cell::RefCell<std::string::String>` cannot be shared between threads safely该错误信息表明,RefCell<String>没有实现Sync,但是Arc只支持实现Sync的类型。同时,错误信息最后一句也提示了RefCell<String>不能在线程间安全共享。编译器又一次避免了线程不安全的风险。
11.2.3 使用锁进行线程同步
要修复代码清单11-20中的错误,只需要使用支持跨线程安全共享可变变量的容器即可,所以可以使用Rust提供的Mutex<T>类型,如代码清单11-21所示。
代码清单11-21:使用Mutex在多线程环境中共享可变变量
use std::thread;
use std::sync::{Arc, Mutex};
fn main() {
let s = Arc::new(Mutex::new("Hello".to_string()));
let mut v = vec![];
for _ in 0..3 {
let s_clone = s_clone();
let child = thread::spawn(move || {
let mut s_clone = s_clone.lock().unwrap();
s_clone.push_str(" world!");
});
v.push(child);
}
for child in v {
child.join().unwrap();
}
}编译代码清单 11-21,终于不再报错了,可以说该段代码实现了线程安全。因为 Mutex消除了跨线程写操作的数据竞争风险,虽然存在竞态条件(比如push_str操作会乱序执行),但就当前示例而言,属于良性竞态条件。
(1)互斥锁(Mutex)
Mutex<T>其实就是Rust实现的互斥锁,用于保护共享数据。如果类型T实现了Send,那么Mutex<T>会自动实现Send和Sync。在互斥锁的保护下,每次只能有一个线程有权限访问数据,但在访问数据之前,必须通过调用lock方法阻塞当前线程,直到得到互斥锁,才能得到访问权限。
Mutex<T>类型实现的lock方法会返回一个LockResult<MutexGuard<T>>类型,LockResult<T>是std::sync模块中定义的错误类型,MutexGuard<T>基于RAII机制实现,只要超出作用域范围就会自动释放锁。另外,Mutex<T>也实现了try_lock方法,该方法在获取锁的时候不会阻塞当前线程,如果得到锁,就返回MutexGuard<T>;如果得不到锁,就返回Err。
(2)跨线程恐慌和错误处理
当子线程发生恐慌时,不会影响到其他线程,恐慌不会在线程间传播。当子线程发生错误时,因为Rust基于返回值的错误处理机制,也让跨线程错误处理变得非常方便。std::thread::JoinHandle实现的join方法会返回Result<T>,当子线程内部发生恐慌时,该方法会返回Err,但是通常不会对此类Err进行处理,而是直接使用unwrap方法,如果获取到合法的结果,则正常使用;如果是 Err,则故意让父线程也发生恐慌,这样就可以把子线程的恐慌传播到父线程,及早发现问题。
但是如果线程在获得锁之后发生恐慌,则称这种情况为“中毒(Posion)”,示例如代码清单11-22所示。
代码清单11-22:“中毒”示例
use std::sync::{Arc, Mutex};
use std::thread;
fn main() {
let mutex = Arc::new(Mutex::new(1));
let c_mutex = mutex.clone();
let _ = thread::spawn(move || {
let mut data = c_mutex.lock().unwrap();
*data = 2;
panic!("oh no");
}).join();
assert_eq!(mutex.is_poisoned(), true);
match mutex.lock() {
Ok(_) => unreachable!(),
Err(p_err) => {
let data = p_err.get_ref();
println!("recovered: {}", data);
}
}
}在代码清单11-22中,代码第6~10行,在子线程内部使用panic!宏故意制造了一个恐慌。需要注意的是,代码第 8 行使用解引用操作“*”来获取 data 中的数据,因为 data 是MutexGuard<T>类型,该类型实现了Deref和DerefMut。
代码第11行,使用is_poisoned方法来查看获得互斥锁的子线程是否发生了恐慌。代码第12~18 行,main 主线程通过lock 方法获得锁,因为子线程内部发生了恐慌,所以主线程调用这个lock方法就会返回Err,这里直接处理了Err的情况。该Err是PoisonError<T>类型,提供了get_ref或get_mut方法,可以得到其内部包装的T类型,所以代码第16行就可以对data数据进行打印直接输出“recovered:3”。
(3)死锁
现在使用多线程来模拟一个掷硬币的场景,硬币有正面和反面,规定连续掷出正面 10次为一轮。采用8个线程,每个线程模拟一轮掷硬币,然后分别统计每一轮掷硬币的总次数和8个线程的平均掷硬币次数。
首先需要写一个模拟掷硬币的函数,如代码清单11-23所示。
代码清单11-23:模拟掷硬币函数
extern crate rand;
fn main() {
// TODO
}
fn filp_simulate(target_flips: u64, total_flips: Arc<Mutex<u64>>) {
let mut continue_positive = 0;
let mut iter_counts = 0;
while continue_positive <= target_flips {
iter_counts += 1;
let pro_or_con = rand::random();
if pro_or_con {
continue_positive += 1;
} else {
continue_positive = 0;
}
}
println!("iter_counts: {}", iter_counts);
let mut total_flips = total_flips.lock().unwrap();
*total_flips += iter_counts;
}在代码清单11-23中引入了rand包,使用rand::random函数来获取随机的bool类型表示正反面。
代码第5~20行,实现了模拟掷硬币函数flip_simulate,其中第一个参数target_flips表示要达到的正面朝上目标数,第二个参数total_flips表示总掷硬币次数。这里total_flips需要累计在多个线程内掷硬币次数的总和,属于多线程共享的可变数据,故使用 Arc<Mutex<64>>类型。
代码第6行和第7行,分别声明了continue_positive和iter_counts来表示连续掷出正面的次数以及掷硬币次数。
代码第8~16行,在while表达式中模拟掷硬币,直到continue_positiv次数达到目标次数target_flips 为止。其中代码第 9 行,每次循环都累计一次掷硬币次数;代码第 10 行,调用rand::random函数模拟掷硬币,该函数是一个泛型函数,但这里没有指定具体的类型,是因为代码第11~15行是if条件表达式,Rust编译器可以据此自动推断出随机函数值的类型,这里为bool类型。当rand::random函数返回true时,continue_positiv的值累计加1,然后进行下一次循环。
代码第18行,调用互斥体total_flips的lock方法获取锁,然后在代码第19行将当前线程的掷硬币次数iter_counts累加到total_flips中。
接下来在main函数中生成8个线程进行掷硬币实验,如代码清单11-24所示。
代码清单11-24:完善main函数
extern crate rand;
use std::thread;
use std::sync::{Arc, Mutex};
fn main() {
let total_flips = Arc::new{Mutex::new(0)};
let completed = Arc::new(Mutex::new(0));
let runs = 8;
let target_flips = 10;
for _ in 0..runs {
let total_flips = total_flips.clone();
let completed = completed.clone();
thread::spawn(move || {
flip_simulate(target_flips, total_flips);
let mut completed = completed.lock().unwrap();
*completed += 1;
});
}
loop {
let completed = completed.lock().unwrap();
if *completed == runs {
let total_flips = total_flips.lock().unwrap();
println!("Final average: {}", *total_flips / *completed);
break;
}
}
}
fn flip_simulate(target_flips: u64, total_flips: Arc<Mutex<u64>>) {
// 同代码清单11-23
}在代码清单 11-24 中,定义了两个互斥体变量 total_flips 和 completed。其中total_flips依旧表示总掷硬币次数,completed用于记录掷硬币实验完成的总线程数。
代码第9~17行,执行for循环生成8个线程,在线程中调用flip_simulate函数来模拟掷硬币。第14行和第15行,通过调用互斥体completed的lock方法获取到互斥锁,在掷硬币完成之后对该线程进行计数。
代码第18~25行,利用loop循环来等待所有子线程完成掷硬币任务。代码第20行,如果所有的线程都完成了掷硬币任务,那么用总掷硬币次数除以完成掷硬币任务的线程总数,就可以得到掷硬币的平均数。
代码清单11-24的执行结果如代码清单11-25所示。
代码清单11-25:执行结果
iter_counts: 204
iter_counts: 1522
iter_counts: 1464
iter_counts: 1460
iter_counts: 1974
iter_counts: 423
iter_counts: 9913
iter_counts: 5447
Final average: 2800每次执行都会得到不同的结果。需要注意的是,在本次掷硬币实验的代码中,使用Mutex<T>保护的是在多个线程之间共享的数据,对于那些在函数中使用的局部变量,默认就是线程安全的。
上面的代码执行是没有问题的,但如果修改一下就可能发生死锁(Deadlock),如代码清单11-26所示。
代码清单11-26:会产生死锁的代码
fn main() {
// 同代码清单11-24
// loop循环的整段代码用下面四行代码替换
let completed = completed.lock().unwrap();
while *completed < runs {}
let total_flips = total_flips.lock().unwrap();
println!("Final average: {}", *total_flips / *completed);
}
fn flip_simulate(target_flips: u64, total_flips: Arc<Mutex<u64>>) {
// 同代码清单11-23
}在代码清单11-26中,只对代码清单11-24中的loop循环的整段代码进行了替换,其余部分不变。代码第4~7行和之前loop循环的代码相比,缺少了对完成线程总数和运行线程数的判断以及break。该段代码在Playgroud平台执行时会发生死锁,报出如下错误:
/root/entrypoint.sh: line 7: 5 Killed timeout --signal=KILL ${timeout} "$@"该超时错误是Playground平台的错误,但它是由死锁引起的。这是因为main主线程一直持有对 completed 互斥体的锁,将会导致所有的模拟掷硬币的子线程阻塞。子线程阻塞以后,就无法更新completed的值了,同时,main主线程还在等待子线程完成任务。这就造成了死锁。
Rust虽然可以避免数据竞争,但不能完全避免其他问题,比如死锁,还需要我们在日常开发中多加留意。
(4)读写锁(RwLock)
在 std::sync 模块中还提供了另外一种锁——读写锁 RwLock<T>。RwLock<T>和Mutex<T>十分类似,不同点在于,RwLock<T>对线程进行读者(Reader)和写者(Writer)的区分,不像 Mutex<T>只能独占访问。该锁支持多个读线程和一个写线程,其中读线程只允许进行只读访问,而写线程只能进行独占写操作。只要线程没有拿到写锁,RwLock<T>就允许任意数量的读线程获得读锁。和Mutex<T>一样,RwLock<T>也会因为恐慌而“中毒”。
代码清单11-27展示了一个读写锁示例。
代码清单11-27:读写锁示例
use std::sync::RwLock;
fn main() {
let lock = RwLock::new(5);
{
let r1 = lock.read().unwrap();
let r2 = lock.read().unwrap();
assert_eq!(*r1, 5);
assert_eq!(*r2, 5);
}
{
let mut w = lock.write().unwrap();
*w += 1;
assert_eq!(*w, 6);
}
}在代码清单11-27中,使用read方法来获取读锁,使用write方法来获取写锁。读锁和写锁要使用显式作用域块隔离开,这样的话,读锁或写锁才能在离开作用域之后自动释放;否则会引起死锁,因为读锁和写锁不能同时存在。
11.2.4 屏障和条件变量
Rust除支持互斥锁和读写锁之外,还支持屏障(Barrier)和条件变量(Condition Variable)同步原语。代码清单11-28展示了一个屏障示例。
代码清单11-28:屏障示例
use std::sync::{Arc, Barrier};
use std::thread;
fn main() {
let mut handles = Vec::with_capacity(5);
let barrier = Arc::new(Barrier::new(5));
for _ in 0..5 {
let c = barrier.clone();
handles.push(thread::spawn(move|| {
println!("before wait");
c.wait();
println!("after wait");
}));
}
for handle in handles {
handle.join().unwrap();
}
}屏障的用法和互斥锁类似,它可以通过wait方法在某个点阻塞全部进入临界区的线程,如代码第10行所示。屏障示例输出结果如代码清单11-29所示。
代码清单11-29:屏障示例输出结果
before wait
before wait
before wait
before wait
before wait
after wait
after wait
after wait
after wait
after wait一共5个线程,但输出结果就好像是线程被“一刀从中间切成两半”一样。实际上是wait方法阻塞了这5个线程,等全部线程执行完前半部分操作之后,再开始后半部分操作。屏障一般用于实现线程同步。
条件变量跟屏障有点相似,但它不是阻塞全部线程,而是在满足指定条件之前阻塞某一个得到互斥锁的线程。代码清单11-30展示了一个条件变量示例。
代码清单11-30:条件变量示例
use std::sync::{Arc, Condvar, Mutex};
use std::thread;
fn main() {
let pair = Arc::new((Mutex::new(false), Condvar::new()));
let pair_clone = pari.clone();
thread::spawn(move || {
let &(ref lock, ref cvar) = &*pair_clone;
let mut started = lock.lock().unwrap();
*started = true;
cvar.notify_none();
});
let &(ref lock, ref cvar) = &*pair;
let mut started = lock.lock().unwrap();
while !*started {
println!("{}", started); // false
started = cvar.wait(started).unwrap();
println!("{}", started); // true
}
}在代码清单 11-30 中,代码第 4 行使用互斥锁和条件变量声明了Arc<(Mutex<bool>,Condvar)>类型的变量pair。
代码第6~11行,创建子线程,并在子线程中得到互斥体lock,通过调用lock方法获得互斥锁,然后修改其中包含的bool类型数据为true。在修改完之后,通过调用条件变量的notify_one方法通知主线程。
代码第12~18行,得到互斥体lock的互斥锁,在while循环中通过条件变量的wait方法阻塞当前main主线程,直到子线程中started互斥体中的条件变为true。
这里值得注意的是,在运行中每个条件变量每次只能和一个互斥体一起使用。在有些线程需要获取某个状态成立的情况下,如果单独使用互斥锁会比较浪费系统资源,因为只有多次出入临界区才能获取到某个状态的信息。此时就可以配合使用条件变量,当状态成立时通知互斥体就可以,因此减少了系统资源的浪费。
11.2.5 原子类型
互斥锁、读写锁等同步原语确实可以满足基本的线程安全需求,但是有时候使用锁会影响性能,甚至存在死锁之类的风险,因此引入了原子类型。
原子类型内部封装了编程语言和操作系统的“契约”,基于此契约来实现一些自带原子操作的类型,而不需要对其使用锁来保证原子性,从而实现无锁(Lock-Free)并发编程。这个契约就是多线程内存模型。Rust的多线程内存模型借鉴于C++11,它保证了多线程并发的顺序一致性,不会因为底层的各种优化重排行为而失去原子性。
对于开发者来说,如果说编程语言提供的锁机制属于“白盒”操作的话,那么原子类型就属于“黑盒”操作。做个简单的类比。锁机制就相当于自家的厨房,你可以自由使用各种厨具和食材做出想要的美食,整个过程对你是透明的;而原子类型相当于去餐馆,你只能选择菜单上提供的菜品,然后交由餐馆后厨来帮你完成,整个过程是建立在对餐馆信任的基础上的,相信餐馆会遵守“契约”。对于原子类型来说,所谓的“菜单上提供的菜品”就如下面所示的操作:
Load,表示从一个原子类型内部读取值。
Store,表示往一个原子类型内部写入值。
各种提供原子“读取-修改-写入”的操作。
➢CAS(Compare-And-Swap),表示比较并交换。
➢Swap,表示原子交换操作。
➢Compare-Exchange,表示比较/交换操作。
➢Fetch-*,表示fetch_add、fetch_sub、fetch_and和fetch_or等一系列原子的加减或逻辑运算。
➢其他。
通过上面原子类型“对外公开”的一系列原子操作,就可以从外部来控制多线程内存模型内部的顺序一致性,从而不用担心底层各种指令重排会导致线程不安全的问题。
(1)Rust标准库中提供的原子类型
在 Rust 标准库 std::sync::atomic 模块中暂时提供了 4 个稳定的原子类型,分别是AtomicBool、AtomicIsize、AtomicPtr和AtomicUsize,另外还有很多基本的原子类型会逐步稳定。这些原子类型均提供了一系列原子操作。代码清单11-31展示了使用原子类型实现一个简单的自旋锁(Spinlock)。
代码清单11-31:使用原子类型实现一个简单的自旋锁
use std::sync::Arc;
use std::sync::atomic::{AtomicUsize, Ordering};
use std::thread;
fn main() {
let spinlock = Arc::new(AtomicUsize::new(1));
let spinlock_clone = spinlock.clone();
let thread = thread::spawn(move || {
spinlock_clone.store(0, Ordering::SeqCst);
});
while spinlock.load(Ordering::SeqCst) != 0 {}
if let Err(panic) = thread.join() {
println!("Thread had an error: {:?}", panic);
}
}在代码清单11-31中,使用了AtomicUsize原子类型。原子类型本身虽然可以保证原子性,但它自身不提供在多线程中共享的方法,所以需要使用 Arc<T>将其跨线程共享,如代码第5行所示。
代码第7~9行,在spawn函数生成的子线程中,通过调用spinlock_clone的store方法,将其内部AtomicUsize类型的值写为0。
代码第10行,在main主线程中使用spinlock的load方法读取其内部原子类型的值,如果不为0,则不停地循环测试锁的状态,直到其状态被置为0为止,这就制造了一个自旋锁。所以,所谓“自旋”就是指在语义上表示这种不断循环获取锁状态的行为。
代码第11~13行,使用join方法阻塞main主线程等待子线程完成,并且做了相应的错误处理。
这里值得注意的是,在使用 store 和 load 这两种原子操作的时候,参数中都出现了Ordering::SeqCst,并且在代码第2行中也引入了Ordering类型。
(2)内存顺序
原子类型除提供基本的原子操作之外,还提供了内存顺序参数。为了帮助理解,可以将该参数类比为在餐馆吃饭时,虽然后厨对用户来说是一个“黑盒”,但可以通过给每个菜品额外添加备注来设置少盐、微辣等偏好要求。同样,每个原子类型虽然对开发者而言是一个“黑盒”,但也可以通过提供内存顺序参数来控制底层线程执行顺序的参数。控制内存顺序实际上就是控制底层线程同步,以便消除底层因为编译器优化或指令重排而可能引发的竞态条件。
在std::sync::atomic::Ordering模块中定义了Rust支持的5种内存顺序,如代码清单11-32所示。
代码清单11-32:在std::sync::atomic::Ordering模块中定义的5种内容顺序
pub enum Ordering {
Relaxed,
Release,
Acquire,
AcqRel,
SeqCst,
}在代码清单11-32中展示的这5种内存顺序,实际上可以归为三大类。
- 排序一致性顺序:Ordering::SeqCst。
- 自由顺序:Ordering::Relaxed。
- 获取-释放顺序:Ordering::Release、Ordering::Acquire和Ordering::AcqRel。
Rust支持的5种内存顺序与其底层的LLVM支持的内存顺序是一致的。
排序一致性顺序是最直观、最简单的内存顺序,它规定使用排序一致性顺序,也就是指定 Ordering::SeqCst 的原子操作,都必须是先存储(store)再加载(load)。这就意味着,多线程环境下,所有的原子写操作都必须在读操作之前完成。通过这种规定,就强行指定了底层多线程的执行顺序,从而保证了多线程中所有操作的全局一致性。但是简单是要付出代价的,这种方式需要对所有的线程进行全局同步,这就存在性能损耗。可以使用下餐馆进行类比,每位客人都存在点单和结账两种状态,使用排序一致性顺序相当于强制要求所有需要结账的客人,必须等所有点单的客户完成之后才可以结账。
自由顺序正好是排序一致性顺序的对立面,顾名思义,它完全不会对线程的顺序进行干涉。也就是说,线程只进行原子操作,但线程之间会存在竞态条件。使用这种内存顺序是比较危险的,只有在明确了解当前使用场景且必须使用它的情况下(比如只有读操作),才可使用自由顺序。
获取-释放顺序,是除排序一致性顺序之外的优先选择。这种内存顺序并不会对全部的线程进行统一强制性的执行顺序要求。在该内存顺序中,store代表释放(Release)语义,而load代表获取(Acquire)语义,通过这两种操作的协作实现线程同步。其中,-
- Ordering::Releas表示使用该顺序的store操作,之前所有的操作对于使用Ordering::Acquire顺序的load操作都是可见的;
- 反之亦然,使用Ordering::Acquire顺序的load操作对于使用Ordering::Release的store操作都是可见的;
- Ordering::AcqRel代表读时使用Ordering::Acquire顺序的load操作,写时使用Ordering::Release顺序的store操作。
获取-释放顺序虽然不像排序一致性顺序那样对全局线程统一排序,但是它让每个线程都能按固定的顺序执行。同样使用下餐馆进行类比,每位客人都存在点单和结账两种状态,假定客人A的点单由服务员甲负责,但是结账时由服务员乙来进行,不可能发生在结账时服务员乙过来再重新为其点单的情况,对于客人A来说,在餐馆吃饭的流程遵守固定的顺序即可。
在日常开发过程中,如何选择内存顺序呢?这和底层硬件环境也有关系,一般情况下建议使用Ordering::SeqCst。在需要性能优化的情况下,先调研并发程序运行的硬件环境,再优先选择获取-释放顺序(Ordering::Release、Ordering::Acquire和Ordering::AcqRel按需选择)。除非必要,否则不要使用Ordering::Relaxed。
11.2.6 使用Channel进行线程间通信
坊间流传着一句非常经典的话:不要通过共享内存来通信,而应该使用通信来共享内存。这句话中蕴含着一种古老的编程哲学,那就是消息传递,通过消息传递的手段可以降低由共享内存而产生的耦合。
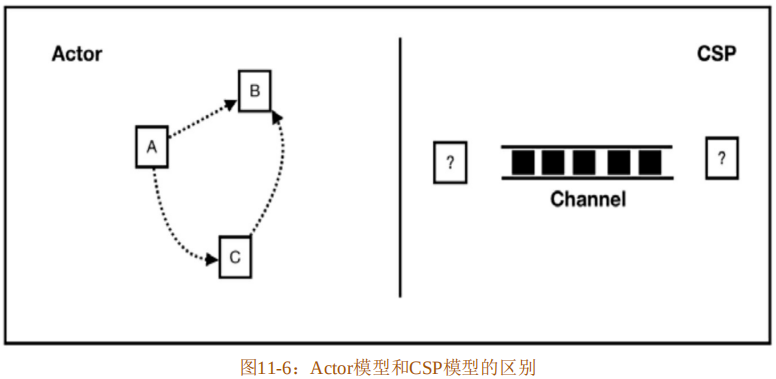
基于消息通信的并发模型主要有两种:Actor 模型和CSP 模型。Actor模型的代表语言是Erlang,而CSP模型的代表语言是Golang。这两种并发模型的区别如下:
- 在Actor模型中,主角是Actor,Actor之间直接发送、接收消息;而在CSP模型中,主角是Channel,其并不关注谁发送消息、谁接收消息。
- 在Actor模型中,Actor之间是直接通信的;而在CSP模型中,依靠Channel来通信。
- Actor模型的耦合程度要高于CSP模型,因为CSP模型不关注消息发送者和接收者。
图11-6展示了Actor模型和CSP模型的区别。
这两种模型都存在了很多年,随着Golang语言的出现,CSP模型再次回到开发者的视线中。Rust标准库也选择实现了CSP并发模型。
(1)CSP并发模型
CSP(Communicating Sequential Processes,通信顺序进程)是一个精确描述并发的数学理论,基于该理论构建的并发程序不会出现常见的问题,并且可以得到数学证明。CSP对程序中每个阶段所包含对象的行为进行精确的指定和验证,它对并发程序的设计影响深远。
CSP模型的基本构造是CSP进程和通信通道。注意,此处CSP进程是并发模型中的概念,不是操作系统中的进程。在CSP中每个事件都是进程,进程之间没有直接交互,只能通过通信通道来交互。CSP进程通常是匿名的,通信通道传递消息通常使用同步方式。
CSP理论在很多语言中得以实现,包括Java、Golang和Rust等。在Rust的实现中,线程就是CSP进程,而通信通道就是Channel。在Rust标准库的std::sync::mpsc模块中为线程提供了 Channel 机制,其具体实现实际上是一个多生产者单消费者(Multi-Producer-Single-Consumer,MPSC)的先进先出(FIFO)队列。线程通过 Channel 进行通信,从而可以实现无锁并发。
(2)生产者消费者模式与Channel
生产者消费者模式是指通过一个中间层来解决数据生产者和消费者之间的耦合问题。生产者和消费者之间不直接通信,而是分别与中间层进行通信。生产者向中间层生产数据,消费者从中间层获取数据进行消费,这样就巧妙地平衡了生产者和消费者对数据的处理能力。
一般情况下,使用一个 FIFO 队列来充当中间层。在多线程环境下,生产者就是生产数据的线程,消费者就是消费数据的线程。Rust 实现的是多生产者单消费者模式,如图 11-7所示。
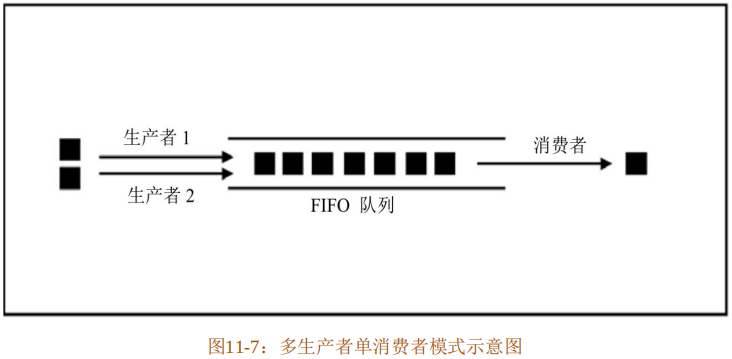
这个FIFO队列就是CSP模型中Channel的具体实现。在标准库std::sync::mpsc模块中定义了以下三种类型的CSP进程:
- Sender,用于发送异步消息。
- SyncSender,用于发送同步消息。
- Receiver,用于接收消息。
Rust中的Channel包括两种类型:
- 异步无界Channel,对应于channel函数,会返回(Sender,Receiver)元组。该Channel发送消息是异步的,并且不会阻塞。无界,是指在理论上缓冲区是无限的。
- 同步有界Channel,对应于sync_channel函数,会返回(SyncSender,Receiver)元组。该Channel可以预分配具有固定大小的缓冲区,并且发送消息是同步的,当缓冲区满时会阻塞消息发送,直到有可用的缓冲空间。当该Channel缓冲区大小为0时,就会变成一个“点”,在这种情况下,Sender和Receiver之间的消息传递是原子操作。
Channel之间的发送或接收操作都会返回一个Result类型用于错误处理。当Channel发生意外时会返回Err,所以通常使用unwrap在线程间传播错误,及早发现问题。
代码清单11-33展示了两个线程之间使用Channel通信的简单示例。
代码清单11-33:两个线程之间使用Channel通信的简单示例
use std::thread;
use std::sync::mpsc::channel;
fn main() {
let (tx, rx) = channel();
thread::spawn(move|| {
tx.send(10).unwrap();
});
assert_eq!(rx.recv().unwrap(), 10);
}在代码清单11-33中,代码第4行,使用channel函数创建了一个用于线程间通信的通道,返回的元组(tx,rx)称作通道的两端(Port)——发送端和接收端。
代码第5~7行,使用spawn生成子线程,并在该子线程中使用tx端口调用send方法向Channel中发送消息。
代码第8行,在main主线程中使用rx端口调用recv方法接收消息。这样就简单地使用Channel实现了线程间通信。
像代码清单11-33这种只有两个线程通信的Channel,叫作流通道(Streaming Channel)。在流通道内部,实际上Rust会默认使用单生产者单消费者队列(SPSC)来提升性能。
代码清单11-34展示了多生产者使用Channel通信的示例。
代码清单11-34:多生产者使用Channel通信示例
use std::thread;
use std::sync::mpsc::channel;
fn main() {
let (tx, rx) = channel();
for i in 0..10 {
let tx = tx.clone();
thread::spawn(move || {
tx.send(i).unwrap();
});
}
for _ in 0..10 {
let j = rx.recv().unwrap();
assert!(0 <= j && j < 10);
}
}在代码清单11-34中,代码第5~10行,在for循环中生成了10个子线程,同时,也将发送端tx拷贝了10次,于是就产生了10个生产者。
代码第11~14行,同样在for循环中,使用接收端rx消费10次数据。
像代码清单11-34这种多生产者单消费者的Channel,叫作共享通道(Sharing Channel)。
上面的示例均为异步Channel,代码清单11-35展示了使用同步Channel通信的示例。
代码清单11-35:使用同步Channel通信示例
use std::sync::mpsc::sync_channel;
use std::thread;
fn main() {
let (tx, rx) = sync_channel(1);
tx.send(1).unwrap();
thread::spawn(move || {
tx.send(2).unwrap();
});
assert_eq!(rx.recv().unwrap(), 1);
assert_eq!(rx.recv().unwrap(), 2);
}在代码清单11-35中,代码第4行,使用sync_channel函数创建了一个同步Channel,并将其缓冲区大小设置为1。
代码第5行,使用发送端tx的send方法往同步Channel中发送消息。
代码第 6~8 行,在 spawn 生成的子线程中再次使用发送端 tx 发送消息。但是因为同步Channel的缓冲区大小只为1,所以这次发送的消息在上一条消息被消费之前会一直阻塞,直到Channel中缓冲区有可用空间才会继续发送。
代码第9行和第10行,使用接收端rx来消费Channel中的数据。如果rx未接收到数据,则会发生恐慌。
(3)Channel死锁
并不是没有锁就不会发生死锁行为。请看代码清单11-36。
代码清单11-36:会发生死锁的Channel示例
use std::thread;
use std::sync::mpsc::channel;
fn main() {
let (tx, rx) = channel();
for i in 0..5 {
let tx = tx.clone();
thread::spawn(move || {
tx.send(i).unwrap();
});
}
// drop(tx);
for j in rx.iter() {
println!("{:?}", j);
}
}在代码清单11-36中,调用了rx的iter方法得到一个迭代器。输出结果如下:
/root/entrypoint.sh: line 7: 5 Killed timeout --signal=KILL ${timeout} "$@"
0
1
4
2
3
4该输出结果是在Playground平台编译执行后得到的,除正常打印从0到4之外,还有一个entrypoint.sh脚本杀掉超时进程的提示。这说明代码清单11-36在执行过程中会发生死锁。
在本地编译该段代码就会发现,在main主线程输出从0到4结果之后,还会一直阻塞main主线程而不退出。这是因为rx的iter方法会阻塞线程,只要tx还没有被析构,该迭代器就会一直等待新的消息,只有tx 被析构之后,迭代器才能返回None,从而结束迭代退出main 主线程。然而,这里 tx 并未被析构,所以迭代器依旧等待,tx 也没有发送新的消息,从而造成了一种死锁状态。要解决此问题也很简单,只需要显式调用drop方法将tx析构就可以,去掉代码清单11-36中第11行的注释即可。
再来看另外一个示例,如代码清单11-37所示。
代码清单11-37:不存在死锁的Channel示例
use std::sync::mpsc::channel;
use std::thread;
fn main() {
let (tx, rx) = channel();
thread::spawn(move || {
tx.send(1u8).unwrap();
tx.send(2u8).unwrap();
tx.send(3u8).unwrap();
});
for x in rx.iter() {
println!("receive: {}",x );
}
}在代码清单11-37中,也通过调用rx的iter方法获取迭代器来消费tx发送的消息,但是该段代码会正常编译执行,不会发生死锁。这是为什么呢?注意,在代码清单11-36中创建的是共享通道,而在代码清单 11-37 中创建的是流通道,也就是多个 Sender 和单个 Sender的区别。发送端tx在离开spawn作用域之后会调用析构函数drop,在drop中会调用tx内部的drop_channel方法来断开(DISCONNECT)Channel。当Channel是共享通道时,在for循环中调用tx的clone方法;当Channel是流通道时,tx在离开子线程作用域之后通过析构函数就可以断开 Channel。之所以存在这样的区别,在于共享通道和流通道底层的构造有所不同。流通道底层自动使用 SPSC(单生产者单消费者)队列来优化性能,因为流通道只是用于两个线程之间的通信。但是共享通道底层使用的还是MPSC(多生产者单消费者)队列,在析构行为上比流通道略为复杂。所以在通常的开发过程中,要注意这两类Channel的区别。
在底层不管是SPSC还是MPSC队列,甚至是同步Channel使用的内置独立的队列,都是基于链表实现的。使用链表的好处就是可以提升性能。在生产数据时,只需要在链表头部添加新的元素即可;在消费数据时,只需要从链表尾部取元素即可。
(4)利用Channel模拟工作量证明
接下来,我们使用Channel来解决一个来自数字货币领域的问题。众所周知,比特币开创了数字货币时代,它不仅仅革新了金融领域,更重要的是它带来了区块链的概念。区块链采用密码学的方法来保证已有的数据不可篡改,采用共识算法为新增的数据达成共识,这完全是与生俱来的且去中心化的“公信力”。而信任是人类社会一切交易的前提,于是,这种借助于密码学和算法取得信任的区块链技术,正逐渐成为当前互联网上各种商业信用体的基础设施。
在比特币中,最流行的一个词就是“挖矿”。这个词极具诱惑性,听上去就像是在“挖金矿”一样。但是当了解了其背后的技术机制之后,就不会产生这种幻想了。实际上,“挖矿”就是比特币和以太坊中的一种共识机制,用专业术语来说,就是指工作量证明(Proof of Work,PoW)。
工作量证明机制其实不是比特币专有的,其存在已经很多年了,最早被用于防范拒绝服务攻击等领域。下面简单用一个示例来说明工作量证明机制的基本原理。
- 给定一个字符串或数字,比如42。
- 给定一个工作目标:找到另外一个数字,要求该数字和42相乘后的结果,经过Hash函数处理后,满足得到的加密字串以“00000”开头。可以通过对“00000”增加或减少0的个数来控制查找的难度。
- 为了找到这个数字,需要从数字1开始递增查找,直到找到满足条件的数字。
要找到这个数字,就需要大量的计算。在这个示例中,数学期望的计算次数就是“工作量”,重复多次验证是否满足条件就是“工作量证明”,这是一个符合统计学规律的概率事件。当然,比特币和以太坊中真实的工作量证明算法比这个示例复杂一些,但原理是相似的。
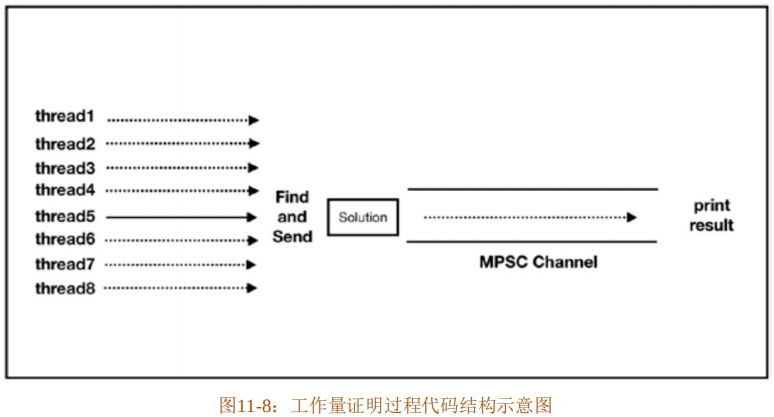
现在,使用Rust来实现上述示例描述的模拟工作量证明过程。代码结构设计如下:
- 使用多线程来加速查找过程。
- 将查找到的符合条件的数字和加密字串通过Channel传递到另外一个线程中并输出。
工作量证明过程代码结构示意图如图11-8所示。
为了简单起见,将整个代码都写到同一个文件中。接下来,使用cargo new–bin pow创建一个新项目。在实现此过程中,需要用到两个第三方包——用来求Hash值的rust-crypto和用来方便迭代的itertools。首先在Cargo.toml文件中添加具体的依赖,如代码清单11-38所示。
代码清单11-38:在Cargo.toml文件中添加rust-crypto和itertools依赖
[dependencies]
itertools = "0.7.8"
rust-crypto = "^0.2"然后在mian.rs文件中引入这两个包,如代码清单11-39所示。
代码清单11-39:在main.rs文件中引入rust-crypto和itertools
// extern crate itertools;
// extern crate crypto;
use itertools::Itertools;
use crypto::digest::Digest;
use crypto::sha2::Sha256;
use std::thread;
use std::sync::{mpsc, Arc};
use std::sync::atomic::{AtomicBool, Ordering};
const BASE: usize = 42;
const THREADS: usize = 8;
static DIFFICULTY: &'static str = "00000";
struct Solution(usize, String);在代码清单11-39中,代码第1~5行,引入了rust-crypto和itertools中所需要的模块,此处使用Sha256算法。在Rust 2018中,代码第1行和第2行可省略。
代码第6~8行,分别引入了线程、MPSC、Arc和原子类型AtomicBool,这些都是编写该并发程序时所需要的基本工具。
代码第9行和第10行,分别定义了常量BASE和THREADS,用来存储工作量证明示例中基础的值42和多线程的线程数,方便修改和复用。
代码第11行,定义了静态全局字符串字面量DIFFICULTY,可以随时通过修改“0”的位数来调整难度,“0”越多难度越高,也就是说,查找过程时间越长。
代码第12行,定义了Solution(usize,String)元组结构体,用来记录最终找到的数字及其加密后的结果。
接下来实现一个验证函数,用于验证所找到的数字是否满足条件,
如代码清单11-40所示。
代码清单11-40:在main.rs中实现验证函数verify
// 接上
fn verify(number: usize) -> Option<Solution> {
let mut hasher = Sha256::new();
hasher.input_str(&(number * BASE).to_string());
let hash: String = hasher.result_str();
if hash.starts_with(DIFFICULTY) {
Some(Solution(number, hash))
} else { None }
}代码清单11-40中的验证函数很简单,它接收一个usize类型的数字number,返回一个Option<Solution>类型的值,因为验证的结果有两种可能:解决和未解决。
代码第3~5 行,使用rust-crypto 包提供的 Sha256 类型来生成number 和BASE 乘积的Hash值hash,并将其转换为String字符串。
代码第6~8行,使用String类型中提供的starts_with方法来判断hash是否以DIFFICULTY中指定的字符串开头。如果是,则返回Some(Solution(number,hash));如果不是,就返回None。
接下来实现查找函数,如代码清单11-41所示。
代码清单11-41:在main.rs中实现查找函数find
// 接上
fn find(
start_at: usize,
sender: mpsc::Sender<Solution>,
is_solution_found: Arc<AtomicBool>
) {
for number in (start_at..).step(THREADS) {
if is_solution_found.load(Ordering::Relaxed) {return;}
if let Some(solution) = verify(number) {
is_solution_found.store(true, Ordering::Relaxed);
sender.send(solution).unwrap();
return;
}
}
}在代码清单11-41中,find函数一共需要三个参数。第一个参数start_at 是计算的起始数字。第二个参数sender是Channel的发送端,其类型是mpsc::Sender<Solution>,因为需要将Solution类型的值通过Channel发送给接收线程。第三个参数is_solution_found用来记录满足条件的Solution是否被找到,它是一个全局性变量,被多个线程操作,应该使用原子类型,所以将其设置为Arc<AtomicBool>。
代码第7行,开启一个无限递增的循环,以start_at为起点,以THREADS为步长,直到找到那个满足条件的数字。以THREADS为步长,是为了将查找的自然数进行分组,以便于平均划分多线程任务。
代码第8行,使用load方法读取原子类型is_solution_found中的值,如果已经设置为true,则从循环中提前返回,否则就继续执行。此处设置内存顺序为自由顺序(Ordering::Relaxed)是安全的,因为底层的线程执行顺序并不会影响到find函数的结果,同时也提升了原子操作的性能。
代码第9~13行,使用verify函数验证循环中每个number的值是否满足条件。如果满足,则使用store方法将is_solution_found的值设置为true,此处内存顺序同样使用自由顺序。然后将查找到的值 solution 通过 Channel 发送出去。如果完成了这些工作,则从当前循环中提前返回,否则继续循环。
对多线程任务的平均划分如图11-9所示。

从图11-9中可以看出,一共8个线程,所以每个线程按8的步长进行迭代,就可以将任务平均划分到这8个线程中。
最后,完善mian函数,如代码清单11-42所示。
代码清单11-42:在main.rs中完善main函数
// 接上
fn main() {
println!("PoW: Find a number,
SHA256(the number * {}) ==\"{}......\"", BASE, DIFFICULTY);
println!("Started{} threads", THREADS);
println!("Please wait... ");
let is_solution_found = Arc::new(AtomicBool::new(false));
let (sender, reveiver) = mpsc::channel();
for i in 0..THREADS {
let sender_n = sender.clone();
let is_solution_found = is_solution_found.clone();
thread::spawn(move || {
find(i, sender_n, is_solution_found);
});
}
match reveiver.recv() {
Ok(Solution(i, hash)) => {
println!("Found the solution: ");
println!("The number is: {},
and hash result is : {}.", i, hash);
},
Err(_) => panic!("Worker threads disconnected"),
}
}在代码清单11-42中,首先打印两条提示信息,包括此次工作量证明示例中的基数、难度字串和线程数,如代码第3~6行所示。
代码第 7 行和第 8 行,分别声明了 is_solution_found 原子类型和Channel,此处is_solution_found默认设置为false。
代码第9~15行,按THREADS指定的线程数生成相应的子线程,并且在子线程中执行find任务。注意此处,在find函数内部已经通过设置循环步长完成了多线程任务的平均划分。
代码第16~23行,通过调用receiver的recv方法来阻塞当前main主线程,等待接收最终满足条件的值。如果接收到了值,则将其打印出来;如果出错,则制造恐慌来报告查找失败。
至此,整个代码实现完毕,只需要在此项目的根目录下执行cargo run命令即可运行。输出结果如代码清单11-43所示。
代码清单11-43:工作量证明示例输出结果
PoW: Find a number, SHA256(the number * 42) == "00000......"
Started 8 threads
Please wait...
Found the solution:
The number is:834312, and hash result is : 00000a31988d8c179097b2753c509b11520f4b5470dc77facedc5734f13d3394.在整个实现过程中需要注意以下几个地方:
- 如何正确地分离生产线程和消费线程?
- 如何正确地划分并发任务?
- 如何正确地识别临界区,以及如何正确地使用原子类型及其内存顺序?
11.2.7 内部可变性探究
在Rust提供的并发编程工具中,基本都支持内部可变性,在行为上与Cell<T>、RefCell<T>比较相似。代码清单11-44展示了Mutex的源码实现。
代码清单11-44:Mutex源码实现
pub struct Mutex<T: ?Sized> {
inner: Box<sys::Mutex>,
poison: poison::Flag,
data: UnsafeCell<T>,
}从代码清单11-44中可以看出,Mutex<T>有三个成员字段,即inner、poison和data。其中 inner 字段包装了用于调用底层操作系统 API的 sys::Mutex;poison 用于标记该锁是否已“中毒”;data 是锁包含的数据,使用了UnsafeCell<T>类型。由此来看,内部可变性是由UnsafeCell<T>提供的。
继续查看 Cell<T>、RefCell<T>、RwLock<T>锁、原子类型以及 mpsc::Sender 等的源码实现,如代码清单11-45所示。
代码清单11-45:Cell<T>、RefCell<T>、RwLock<T>等源码实现
pub struct Cell<T> {
value: UnsafeCell<T>,
}
pub struct RefCell<T: ?Sized> {
borrow: Cell<BorrowFlag>,
value: UnsafeCell<T>,
}
pub struce RwLock<T: ?Sized> {
inner: Box<sys::RWLock>,
poison: poison::Flag,
data: UnsafeCell<T>,
}
pub struct AtomicBool {
v: UnsafeCell<u8>,
}
pub struct Sender<T> {
inner: UnsafeCell<Flavor<T>>,
}
pub struct Receiver<T> {
inner: UnsafeCell<Flavor<T>>,
}从代码清单 11-45 中可以看出,这些拥有内部可变性的结构体都是基于 UnsafeCell<T>实现的。继续查看UnsafeCell<T>的源码实现,
如代码清单11-46所示。
代码清单11-46:UnsafeCell<T>源码实现
#[lang = "unsafe_cell"]
pub struct UnsafeCell<T: ?Sized> {
value: T,
}
impl<T: ?Sized> !Sync for UnsafeCell<T> {}
impl<T: ?Sized> UnsafeCell<T> {
pub fn get(&self) -> *mut T {
&self.value as *const T as *mut T
}
}在代码清单11-46中,UnsafeCell<T>只是一个泛型结构体,它属于语言项(Lang Item),所以编译器会对它进行某种特殊的照顾。
代码第5行,为UnsafeCell<T>实现了!Sync,因为单独使用该类型并不能保证线程安全。
UnsafeCell<T>的特别之处在于第 7 行和第 8 行实现的 get 方法,通过该方法可以将UnsafeCell<T>中T类型的不可变借用转换为可变的原生指针(Raw Pointer)。在get方法内部,通过as将T类型的不可变借用先转换为*counst T,再转换成*mut T。
一般来说,在Rust中将不可变借用转换为可变借用属于未定义行为,编译器不允许开发者随意对这两种引用进行相互转换。但是,UnsafeCell<T>是唯一的例外。这也是UnsafeCell<T>属于语言项的原因,它属于 Rust 中将不可变转换为可变的唯一合法渠道,对于使用了UnsafeCell<T>的类型,编译器会关闭相关的检查。
因此,在上述各种拥有内部可变性的容器内部均使用了 UnsafeCell<T>,不会违反 Rust的编译器安全检查。
11.2.8 线程池
在实际应用中,多线程并发更常用的方式是使用线程池。线程虽然比进程轻量,但如果每次处理任务都要重新创建线程的话,就会导致线程过多,从而带来更多的创建和调度的开销。采用线程池的方式,不仅可以实现对线程的复用,避免多次创建、销毁线程的开销,而且还能保证内核可以被充分利用。
实现一个线程池需要考虑以下几点。
- 工作线程:用于处理具体任务的线程。
- 线程池初始化:即通过设置参数指定线程池的初始栈大小、名称、工作线程数等。
- 待处理任务的存储队列:工作线程数是有限的,对于来不及处理的任务,需要暂时保存到一个队列中。
- 线程池管理:即管理线程池中的任务数和工作线程的状态。比如,在没有空闲工作线程时则需要等待,或者在需要时阻塞主线程等待所有任务执行完毕。
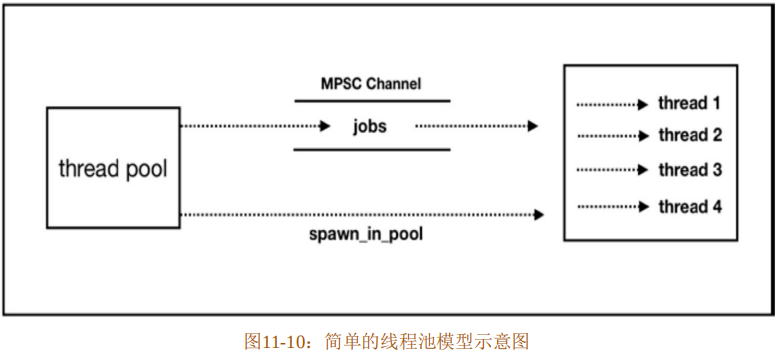
接下来参考第三方包threadpool的实现,来说明如何使用Rust标准库中提供的并发工具来实现一个简单的线程池。
- 线程池:通过创建一个线程池结构体来控制线程池的初始化。为此结构体实现Builder模式,定制初始化参数,并且实现生成工作线程的方法。
- 待处理任务队列:使用无界队列mpsc::channel,缓存待处理的任务。
- 线程池管理:使用原子类型对工作任务状态进行计数,达到管理的目的。
这个简单的线程池模型示意图如图11-10所示。
使用cargo new–bin thread_pool创建一个新项目thread_pool,在Cargo.toml文件中添加第三方包num_cpus的依赖,如代码清单11-47所示。
代码清单11-47:在Cargo.toml中添加num_cpus依赖
[dependencies]
num_cpus = "1.8"在代码清单11-47中添加的num_cpus依赖可以识别当前运行的计算机中CPU的个数,将其作为线程池默认的工作线程数。
在main.rs文件中添加初始化代码,如代码清单11-48所示。
代码清单11-48:在main.rs中添加初始化代码
// extern crate num_cpus;
use std::sync::mpsc::{channel, Sender, Receiver};
use std::sync::{Arc, Mutex, Condvar};
use std::sync::atomic::{AtomicUsize, Ordering};
use std::thread;
trait FnBox {
fn call_box(self: Box<Self>);
}
impl<F: FnOnce()> FnBox for F {
fn call_box(self: Box<F>) {
(*self) ()
}
}
type Thunk<'a> = Box<FnBox + Send + 'a>;在代码清单11-48中引入了num_cpus包。同时,在代码第2行引入了channel、Sender和Receiver,随后会使用它们来管理工作任务。在代码第3行和第4行引入了Arc、Mutex、Condvar和AtomicUsize,随后会用到。在代码第5行引入了thread模块,需要用它来生成具体的工作线程。
值得注意的是代码第6~13行,定义了FnBox trait,并为FnOnce的闭包实现了该trait,在 call_box 方法中执行闭包调用。这样做是为了避免使用#![feature(fnbox)]特性,可以回想一下第6章的内容。
代码第14行,使用type定义了一个类型别名,这是为了简化代码。为了让线程池中维护的线程可以共享相同的数据,还需要一个共享数据的结构体,如代码清单11-49所示。
代码清单11-49:在main.rs中添加ThreadPoolSharedData结构体
// 接上
struct ThreadPoolSharedData {
name: Option<String>,
job_receiver: Mutex<Receiver<Thunk<'static>>>,
empty_trigger: Mutex<()>,
empty_condvar: Condvar,
queued_count: AtomicUsize,
active_count: AtomicUsize,
max_thread_count: AtomicUsize,
panic_count: AtomicUsize,
stack_size: Option<usize>,
}
impl ThreadPoolSharedData {
fn has_work(&self) -> bool {
self.queued_count.load(Ordering::SeqCst) > 0
||
self.active_count.load(Ordering::SeqCst) > 0
}
fn on_work_notify_all(&self) {
if !self.has_work() {
*self.empty_trigger.lock()
.expect("Unable to notify all joining threads");
self.empty_condvar.notify_all();
}
}
}在代码清单11-49中,定义了ThreadPoolSharedData结构体,如代码第2~12行所示,其中字段的含义如下:
- name,用于标记线程的名称,线程池内的线程都用统一的名称。该值可有可无,所以使用Option<String>类型。
- job_receiver,用于存储从 Channel 中接收任务的接收端(rx),此处为Mutex<Receiver<Thunk<'static>>>类型,是因为在多线程环境下,Reveiver<Thunk<'static>>类型不能被安全共享,为了线程安全,必须要加锁。此处Thunk<'static>代表Box<FnBox+Send+'static>,要执行的具体任务均为闭包。
- empty_trigger和empty_condvar,分别是Mutex<()>和Condvar,代表空锁和空的条件变量,用于实现线程池的join方法,条件变量需要配合互斥锁才能使用。
- queued_count和active_count,代表线程池中的总队列数和正在执行任务的工作线程数。因为是多线程操作,所以使用原子类型AtomicUsize来保证原子性。
- max_thread_count,代表线程池允许的最大工作线程数。
- panic_count,用于记录线程池中发生恐慌的工作线程数,同样使用原子类型AtomicUsize来保证原子性。
- stack_size,用于设置工作线程栈大小,可有可无,所以为 Option<usize>类型。如果不设置栈大小,则默认为8MB。
代码第14~18行,为ThreadPoolSharedData实现了has_work方法,当queued_count大于0或active_count大于0时,表示线程池处于正常工作状态。
代码第19~25行,实现了no_work_notify_all方法,通过has_work方法判断线程池的工作状态。如果线程池中的工作线程处于闲置状态,则代表所有任务均以完成,那么通过empty_trigger拿到锁,再调用empty_condvar的notify_all方法来通知所有阻塞的线程解除阻塞状态。该方法用于配合线程池的join方法。
接下来需要一个线程池结构体,如代码清单11-50所示。
代码清单11-50:在main.rs中添加ThreadPool结构体
// 接上
pub struct ThreadPool {
jobs: Sender<Thunk<'static>>,
shared_data: Arc<ThreadPoolSharedData>,
}
impl ThreadPool {
pub fn new(num_threads: usize) -> ThreadPool {
Builder::new().num_threads(num_threads).build()
}
pub fn execute<F>(&self, job: F)
where F: FnOnce() + Send + 'static
{
self.shared_data
.queued_count.fetch_add(1, Ordering::SeqCst);
self.jobs.send(Box::new(job))
.expect("unable to send job into queue.");
}
pub fn join(&self) {
if self.shared_data.has_work() == false {
return ();
}
let mut lock = self.shared_data.empty_trigger.lock().unwrap();
while self.shared_data.has_work() {
lock = self.shared_data
.empty_condvar.wait(lock).unwrap();
}
}
}在代码清单11-50中,定义了ThreadPool结构体,如代码第2~5行所示,其包含如下两个字段:
- jobs,用于存储 Channel 发送端(tx),使用它给工作线程发送具体的任务,为Sender<Thunk<'static>>类型。
- shared_data,记录工作线程共享的数据,为Arc<ThreadPoolSharedData>类型。
代码第7~9行,实现了new方法,用于初始化线程池。在该方法中使用构建者模式来定制生成工作线程。
代码第 10~17 行,实现了 execute 方法,用于将任务添加到Channel 队列中,同时使用AtomicUsize的fetch_add方法将queued_count累加一次。可以通过此方法向队列中多次添加任务。
代码第18~27行,实现了join方法,该方法用于在需要时阻塞主线程等待线程池中的所有任务执行完毕。代码第19~21行,判断线程池如果处于闲置状态,则提前返回。代码第22行,通过shared_data中的empty_trigger来获得互斥锁。在代码第23~26行的while循环中,如果线程池中的工作线程一直处于正常工作状态,则调用empty_condvar的wait方法来阻塞当前线程,直到获得解除阻塞的通知(如notify_all)。
接下来创建初始化线程池需要用到的Builder结构体和build方法,如代码清单11-51所示。
代码清单11-51:在main.rs中添加Builder结构体及其方法
// 接上
#[derive(Clone, Default)]
pub struct Builder {
num_threads: Option<usize>,
thread_name: Option<String>,
thread_stack_size: Option<usize>,
}
impl Builder {
pub fn new() -> Builder {
Builder {
num_threads: None,
thread_name: None,
thread_stack_size: None,
}
}
pub fn num_threads(mut self, num_threads: usize) -> Builder {
assert!(num_threads > 0);
self.num_threads = Some(num_threads);
self
}
pub fn build(self) -> ThreadPool {
let (tx, rx) = channel::<Thunk<'static>>();
let num_threads = self.num_threads
.unwrap_or_else(num_cpus::get);
let shared_data = Arc::new(ThreadPoolSharedData {
name: self.thread_name,
job_receiver: Mutex::new(rx),
empty_condvar: Condvar::new(),
empty_trigger: Mutex::new(()),
queued_count: AtomicUsize::new(0),
active_count: AtomicUsize::new(0),
max_thread_count: AtomicUsize::new(num_threads),
panic_count: AtomicUsize::new(0),
stack_size: self.thread_stack_size,
});
for _ in 0..num_threads {
spawn_in_pool(shared_data.clone());
}
ThreadPool {
jobs: tx,
shared_data: shared_data,
}
}
}在代码清单11-51中,定义了Builder结构体,其包含三个字段:num_threads、thread_name和thread_stack_size,分别表示要创建的工作线程数、线程名称和线程栈大小,均为可选类型,如代码第3~7行所示。
代码第9~15行,为Builder结构体实现了new方法,生成一个字段初始值均为None的Builder实例。
代码第16~20行,实现了num_threads方法,通过参数可以设置工作线程数。
代码第21~43行,实现了build方法,用于初始化最终的线程池。代码第22行,使用channel函数创建一个无界队列。代码第23行和第24行,通过num_threads得到工作线程数,如果没有设置,则默认使用num_cpus::get方法返回当前计算机的CPU核心数。代码第25~35行,初始化了一个ThreadPoolSharedData实例,并将其放到Arc中。代码第36~38行,通过迭代num_threads次来生成相应的工作线程,其中spawn_in_pool函数用于生成工作线程。代码第39~42行,返回最终初始化完成的ThreadPool实例。
代码清单11-52展示了spawn_in_pool函数的具体实现。
代码清单11-52:spawn_in_pool函数的具体实现
// 接上
fn spawn in_pool(shared_data: Arc<ThreadPoolSharedData>) {
let mut builder = thread::Builder::new();
if let Some(ref name) = shared_data.name {
builder = builder.name(name.clone());
}
if let Some(ref stack_size) = shared_data.stack_size {
builder = builder.stack_size(stack_size.to_owned());
}
builder.spawn(move|| {
let sentinel = Sentinel::new(&shared_data);
loop {
let thread_counter_val = shared_data
.active_count.load(Ordering::Acquire);
let max_thread_count_val = shared_data
.max_thread_count.load(Ordering::Relaxed);
if thread_counter_val >= max_thread_count_val {
break;
}
let message = {
let lock = shared_data.job_receiver.lock()
.expect("unable to lock job_receiver");
lock,recv()
};
let job = match message {
Ok(job) => job,
Err(..) => break,
};
shared_data.queued_count.fetch_sub(1, Ordering::SeqCst);
shared_data.active_count.fetch_add(1, Ordering::SeqCst);
job.call_box();
shared_data.active_count.fetch_sub(1, Ordering::SeqCst);
shared_data.no_work_notify_all();
}
sentinel.cancel();
}).unwrap();
}在代码清单11-52中,第3~9行,通过shared_data中存储的name和stack_size来定制生成线程。注意此处使用的是thread模块的Builder::new 方法,而非当前 main.rs 中定义的Builder。
代码第10~36行,使用builder.spawn方法来创建工作线程。
代码第11行中的Sentinel结构体用来对具体的工作线程进行监控。
代码第12~34行为一个loop循环,用于阻塞当前工作线程从任务队列中取具体的任务来执行。代码第13行和第14行,得到当前任务队列中的active_count,注意这里load方法使用的内存顺序为Ordering::Acquire,代表load方法能看到之前所有线程对active_count所做的修改。而代码第 15 行和第 16 行,获取 max_thread_count 数目使用的内存顺序为Ordering::Relaxed,这是因为max_thread_count的值不会被底层线程读取顺序影响到,使用自由顺序可以提升性能。
代码第17~19行,如果工作队列数大于最大的线程数,则退出此循环。
代码第20~24行,先得到job_receiver的锁,然后调用recv方法从队列中获取任务。但此时并未执行任务。
代码第25~28行,通过match匹配从message中得到具体的闭包任务,当message是错误类型时则跳出循环。
代码第29行和第30行,将shared_data中的queued_count减1,因为已经从任务队列中取到了一个任务,那么任务队列中的任务数就会减1。将active_count通过fetch_add加1,因为当前工作线程即将对该任务进行处理,那么正在执行任务的工作线程数就应该加1 。
代码第31行,通过调用job的call_box方法来执行具体的任务。
代码第32行,在执行完任务之后,将active_count减1,表示该工作线程随时可以接受下一个任务。
代码第 33 行,通过调用 shared_data 的 no_work_notify_all 方法,来通知使用条件变量wait方法阻塞的线程在线程池中的任务执行完毕后解除阻塞。
代码第35行,使用cancel方法设置sentinel实例的状态,表示该线程正常执行完所有任务。
代码清单11-53展示了Sentinel的具体定义。
代码清单11-53:Sentinel的具体定义
// 接上
struct Sentinel<'a> {
shared_data: &'a Arc<ThreadPoolSharedData>,
active: bool,
}
impl<'a> Sentinel<'a> {
fn new(shared_data: &'a Arc<ThreadPoolSharedData>)
-> Sentinel<'a> {
Sentinel {
shared_data: shared_data,
active: true,
}
}
fn cancel(mut self) {
self.active = false;
}
}
impl<'a> Drop for Sentinel<'a> {
fn drop(&mut self) {
if self.active {
self.shared_data.active_count
.fetch_sub(1, Ordering::SeqCst);
if thread::panicking() {
self.shared_data.panic_count
.fetch_add(1, Ordering::SeqCst);
}
self.shared_data.no_work_notify_all();
spawn_in_pool(self.shared_data.clone())
}
}
}在代码清单 11-53 中,代码第 2~5 行定义了 Sentinel<'a>结构体,其中包含shared_data和active字段,分别是&'a Arc<ThreadPoolSharedData>和bool类型。该结构体用于监控当前工作线程的工作状态,shared_data字段用来包装线程池共享数据;而active字段如果为true,则代表当前工作线程正在工作,如果为false,则代表当前工作线程正常执行完毕。
代码第6~17行,实现了new和cancel方法,分别用于创建Sentinel<'a>实例和设置active状态为false。
代码第18~30 行,为Sentinel<'a>实现了Drop,用于处理处于非正常工作状态的工作线程。当工作线程(见代码清单11-52)中的Sentinel<'a>实例离开作用域时会调用析构函数drop。在该函数中,会判断当前Sentinel<'a>实例的状态,如果是true,则证明该工作线程并未正常退出,所以会依次执行第21~28行代码。
代码第21行和第22行将active_count减1,将当前工作线程正常归还到线程池中。代码第 23~26 行,通过 thread::panicking 函数来判断当前工作线程是否由于发生恐慌而退出,如果是,则将panic_count加1。代码第27行,同样调用shared_data的no_work_notify_all方法,来通知使用条件变量的wait方法阻塞的线程在线程池中的任务执行完毕后解除阻塞。代码第28行,重新调用spawn_in_pool函数来生成工作线程。
至此,线程池实现完毕。在main函数中来使用线程池,如代码清单11-54所示。
代码清单11-54:在main函数中使用线程池
fn main() {
let pool = ThreadPool::new(8);
let test_count = Arc::new(AtomicUsize::new(0));
for _ in 0..42 {
let test_count = test_count.clone();
pool.execute(move || {
test_count.fetch_add(1, Ordering::Relaxed);
});
}
pool.join();
assert_eq!(42, test_count.load(Ordering::Relaxed));
}在代码清单11-54中,通过ThreadPool::new(8)创建了拥有8个工作线程的线程池,如代码第2行所示。
代码第3行,创建了一个原子类型的变量test_count,用于计数测试。
代码第4~9行,在迭代42次的for循环中,使用pool.execute将test_count加1的任务放到线程池中进行计算。
代码第10行,使用pool的join方法阻塞main主线程等待线程池中的任务执行完毕。
代码第11行,通过断言判断test_count的值最终为42。
最后在项目根目录下执行cargo run命令,代码正常编译运行。通过此示例,我们了解到如何创建一个简单的线程池,同同时也对Rust标准库中提供的多线程并发工具有了进一步的深入了解。
11.2.9 使用Rayon执行并行任务
Rayon是一个第三方包,使用它可以轻松地将顺序计算转换为安全的并行计算,并且保证无数据竞争。Rayon提供了两种使用方法:
- 并行迭代器,即可以并行执行的迭代器。
- join方法,可以并行处理递归或分治风格的问题。
代码清单11-55展示了使用Rayon的并行迭代器。
代码清单11-55:使用Rayon的并行迭代器
extern crate rayon;
use rayon::prelude::*;
fn sum_of_squares(input: &[i32]) -> i32 {
input.par_iter().map(|&i| i * i).sum()
}
fn increment_all(input: &mut [i32]) {
input.par_iter_mut().for_each(|p| *p += 1);
}
fn main() {
let v = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
let r = sum_of_squares(&v);
println!("{}", r);
let mut v = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
increment_all(&mut v);
println!("{:?}", v);
}在代码清单11-55中,代码第1行和第2行,分别引入了rayon包和prelude模块。代码第3~5行,定义了sum_of_squares函数,其中用到了par_iter迭代器,该迭代器就是Rayon提供的并行迭代器,它会返回一个不可变的并行迭代器类型。
代码第6~8行,定义了increment_all函数,其中使用了par_iter_mut迭代器,这是Rayon提供的可变并行迭代器。
在main函数中,分别调用了sum_of_squares和increment_all函数,最终输出结果如代码清单11-56所示。
代码清单11-56:并行迭代器输出结果
385
[2, 3, 4, 5, 6, 7, 8, 9, 10, 11]代码清单11-57展示了使用join方法进行并行迭代。
代码清单11-57:使用join方法进行并行迭代
extern crate rayon;
fn fib(n: u32) -> u32 {
if n < 2 { return n; }
let (a, b) = rayon::join(
|| fib(m - 1), || fib(n - 2)
);
a + b
}
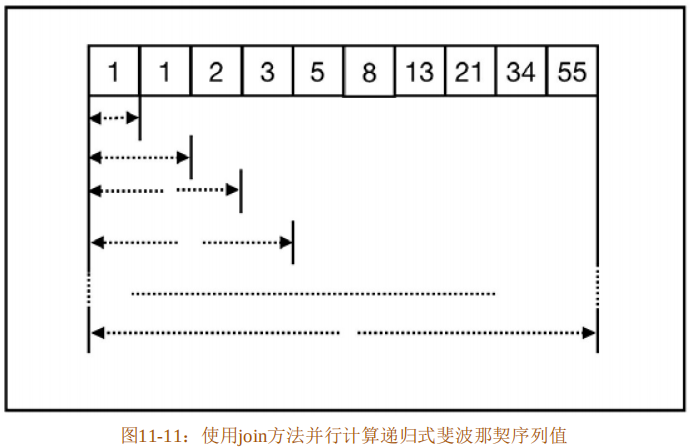
fn main() {
let r = fib(32);
assert_eq!(r, 2178309);
}在代码清单11-57中,代码第2~8行实现的fib函数用来计算指定位置的斐波那契序列值,在该函数中使用rayon::join方法接收两个闭包并行执行,迭代过程如图11-11所示。
使用join方法并不一定会保证并行执行闭包,Rayon底层使用线程池来执行任务,如果工作线程被占用,Rayon 会选择顺序执行。Rayon 的并行能力基于一种叫作工作窃取(Work-Stealing)的技术,线程池中的每个线程都有一个互不影响的任务队列(双端队列),线程每次都从当前任务队列的头部取出一个任务来执行。如果某个线程对应的队列已空并且处于空闲状态,而其他线程的队列中还有任务需要处理,但是该线程处于工作状态,那么空闲的线程就可以从其他线程的队列尾部取一个任务来执行。这种行为表现就像空闲的线程去偷工作中的线程任务一样,所以叫作“工作窃取”。
关于Rayon的更多细节,可以参考其源码中rayon-demo目录下的示例。
11.2.10 使用Crossbeam
Crossbeam 是比较常用的第三方并发库,在实际开发中通常用它来代替标准库。它是对标准库的扩展和包装,一共包含四大模块。
- 用于增强 std::sync 的原子类型。提供了 C++11 风格的Consume内存顺序原子类型AtomicConsume和用于存储和检索Arc的ArcCell。
- 对标准库thread和各种同步原语的扩展,提供了很多实用的工具。比如Scoped线程、支持缓存行填充的CachePadded等。
- 提供了MPMC的Channel,以及各种无锁并发数据结构。包括:并发工作窃取双端队列、并发无锁队列(MS-Queue)和无锁栈(Treiber Stack)。
- 提供了并发数据结构中需要的内存管理组件crossbeam-epoch。因为在多线程并发情况下,如果线程从并发数据结构中删除某个节点,但是该节点还有可能被其他线程使用,则无法立即销毁该节点。Epoch GC允许推迟销毁,直到它变得安全。在不久的将来,其还将支持险象指针(Hazard Pointer,HP)和QSBR(Quiescent-State-Based Reclamation)回收算法。
(1)扩展原子类型
Crossbeam的crossbeam-utils子包中提供了AtomicConsume trait,是对标准库中原子类型内存顺序的增强。该trait允许原子类型以“Consume”内存顺序进行读取。“Consume”内存顺序是C++中支持的一种内存顺序,可以称为消耗-释放顺序。相对于获取-释放顺序而言,消耗-释放顺序的性能更好。因为获取-释放顺序会同步所有写操作之前的读操作,而消耗-释放顺序则只会同步数据之间有相互依赖的操作,粒度更细,所以性能更好。目前仅 ARM和AArch64架构支持,在其他架构上还是要回归到获取-释放顺序。
通过crossbeam-utils包,已经为标准库std::sync::atomic中的AtomicBool、AtomicUsize等原子类型实现了该trait,只需要调用load_consume方法就可以使用该内存顺序。
在最新的crossbeam-utils包中,还增加了一个原子类型AtomicCell,其等价于一个具有原子操作的Cell<T>类型。
(2)使用Scoped线程
在标准库线程生成的子线程中,无法安全地使用父线程中的引用,如代码清单11-58所示。
代码清单11-58:父线程中的引用无法在子线程中安全地使用
fn main() {
let array = [1, 2, 3];
let mut guards = vec![];
for &i in &array {
let guard = std::thread::spawn(move || {
println!("element: {}", i);
});
guards.push(guard);
}
for guard in guards {
guard.join().unwrap();
}
}在代码清单11-58中,在for循环中需要使用&i来解构引用得到数组中的值,才能在子线程中被安全地使用。也就是说,在子线程中无法完全地使用父线程中的引用。
Crossbeam提供了一种Scoped线程,允许子线程可以安全地使用父线程中的引用,如代码清单11-59所示。
代码清单11-59:使用Crossbeam提供的Scoped线程
// extern crate corssbeam;
use crossbeam::thread::scope;
fn main() {
let array = [1, 2, 3];
scope(|scope| {
for i in &array {
scope.spawn(move || { println!("element: {}", i)});
}
});
}在代码清单 11-59 中,代码第 1 行在 Rust 2018 版本中可以省略。使用crossbeam::thread::scope函数允许传入一个以scope为参数的闭包,在该闭包中由scope参数来生成子线程,其可以安全地使用父线程(main主线程)中array数组的元素引用。实际上,闭包中的scope参数是一个内部使用的Scope结构体,该结构体会负责子线程的创建、join父线程和析构等工作,以便保证引用的安全。
(3)使用缓存行填充提升并发性能
在并发编程中,有一个号称“无声性能杀手”的概念叫作伪共享(False Sharing)。为了提升性能,现代CPU都有自己的多级缓存。而在缓存系统中,都是以缓存行(Cache Line)为基本单位进行存储的,其长度通常是 64 字节。当程序中的数据存储在彼此相邻的连续内存中时,可以被 L1 级缓存一次加载完成,享受缓存带来的性能极致。当数据结构中的数据存储在非连续内存中时,则会出现缓存未命中的情况。
将数据存储在连续紧凑的内存中虽然可以带来高性能,但是将其置于多线程下就会发生问题。多线程操作同一个缓存行的不同字节,将会产生竞争,导致线程彼此牵连,相互影响,最终变成串行的程序,降低了并发性,这就是所谓的伪共享。因此,为了避免伪共享,就需要将多线程之间的数据进行隔离,使得它们不在同一个缓存行,从而提升多线程的并发性能。
避免伪共享的方案有很多,其中一种方案就是刻意增大元素间的间隔,使得不同线程的存取单元位于不同的缓存行。Crossbeam提供了CachePadded<T>类型,可以进行缓存行填充(Padding),从而避免伪共享。
在Crossbeam提供的并发数据结构中就用到了缓存行填充。比如并发的工作窃取双端队列crossbeam-deque,就用到了缓存行填充来避免伪共享,提升并发性能。
(4)使用MPMC Channel
Crossbeam还提供了一个std::sync::mpsc的替代品MPMC Channel,也就是多生产者多消费者通道。标准库 mpsc 中的Sender 和Receiver都没有实现Sync,但是Crossbeam提供的MPMC Channel的Sender和Receiver都实现了Sync。
所以,可以通过引用来共享Sender和Receiver。代码清单11-60展示了使用Crossbeam提供的MPMC Channel。
代码清单11-60:使用Crossbeam提供的MPMC Channel
use crossbeam::channel as channel;
fn main() {
let (s, r) = channel::unbounded();
crossbeam::scope(|scope| {
scopea.spawn(|| {
s.send(1);
r.recv().unwrap();
});
scope.spawn(|| {
s.send(2);
r.recv().unwrap();
});
});
}代码清单11-60基于Rust 2018,所以省略了extern crate crossbeam。代码第3行,使用unbounded函数来创建无界通道。Crossbeam提供的MPMC Channel和标准库的Channel类似,也提供了无界通道和有界通道两种类型。
接下来,使用scope函数创建了两个Scoped子线程,并通过获取通道发送端s和接收端r的引用来共享使用Channel。当然,也可以通过clone方法来共享通道两端。
在Crossbeam中还提供了select!宏,用于方便地处理一组通道中的消息,如代码清单11-61所示。
代码清单11-61:使用Crossbeam提供的select!宏
use crossbeam_chanel::select;
use crossbeam_channel as channel;
use std::thread;
fn fibonacci(
fib: channel::Sender<u64>, quit: channel::Receiver<()>
) {
let (mut x, mut y) = (0, 1);
loop {
select! {
send(fib, x) => {
let tmp = x;
x = y;
y = tmp + y;
}
recv(quit) => {
println!("quit");
return;
}
}
}
}
fn main() {
let (fib_s, fib_r) = channel::bounded(0);
let (quie_s, quit_r) = channel::bounded(0);
thread::spawn(move || {
for _ in 0..10 {
println!("{}", fib_r.recv().unwrap());
}
quit_s.send(());
});
fibonacci(fib_s, quit_r);
}代码清单11-61基于Rust 2018,所以不需要显式使用#[macro_use]来导入select!宏。在代码清单11-61中定义了fibonacci函数,用于从fib通道中计算斐波那契数列,并从quit通道中退出计算。
代码第8~20行,将select!宏置于loop循环中,是因为select!宏每次只会执行一个操作。对于 select!宏来说,如果同时有多个操作已经准备就绪,则会随机选择一个执行;否则,只选择最先准备就绪的那个操作来执行。
在main函数中,创建了两个有界通道,如代码第23行和第24行所示。但这两个有界通道是一种比较特殊的通道,在Crossbeam中叫作零容量通道。这种通道会一直阻塞,除非接收端可以对其进行操作。
代码第25行,使用标准库线程生成一个子线程。
代码第26~28行,在子线程中通过for循环来接收fib_r收到的前10个斐波那契数列。代码第29行,在for循环执行完毕后,就通过quit_s发送消息让fibonacci函数退出。所以,在 for 循环过程中,在 fibonacci 函数的 select!宏中只有 send 操作准备就绪,所以 fibonacci函数不需要担心突然收到quit消息而意外退出。只有当for循环结束以后,select!宏中的recv操作才会执行。
其实在标准库 std::sync::mpsc 模块中也提供了 Select 类型,但目前还是实验特性。Crossbeam提供的select!宏还有很多其他功能,具体可以查看相关文档。
11.3 异步并发
在本章开头的“通用概念”中已经介绍了异步并发相关背景,了解到异步编程的发展一共经历了三个阶段。
- 第一个阶段,直接使用回调函数,随之带来的问题是“回调地狱”;
- 第二个阶段,使用 Promise/Future并发模型,解决了回调函数的问题,但是代码依旧有很多冗余;
- 第三个阶段,利用协程实现async/await解决方案,也号称“异步的终极解决方案”。
目前,很多编程语言都支持异步并发,但并非都支持到第三个阶段。比如异步开发大放异彩的JavaScript语言,也只是在ES 7中刚刚支持。虽然各种语言对异步编程的支持参差不齐,但异步编程解决方案async/await几乎已经成为业界的事实标准。然而,在Rust 1.0正式发布时,Rust并没有包含任何异步开发的支持。这是因为Rust有自己的发展路线,它的首要目标是解决并发安全的问题。
在经过一系列版本迭代之后,Rust才确定了新的发展路线,即:成为能开发出高性能网络服务的首选语言。因此,Rust 引入了生成器,随之又先后引入了 Future 并发模型和async/await方案。然而,引入异步并发模型的过程并非一帆风顺,本来计划在Rust 2018稳定版中包含 async/await语法,但最后因为这样那样的问题不得不延期。主要原因是想要更好地提升Rust的异步开发的人体工程学。过程虽然曲折,但也体现了Rust追求安全、性能和并发三连击的决心。
11.3.1 生成器
如果要支持 async/await 异步开发,最好是能有协程的支持。所以,Rust 的第一步是需要引进协程(Coroutine)。
协程的实现一般分为两种,其中一种是有栈协程(Stackful);另一种是无栈协程(Stackless)。
- 对于有栈协程的实现,一般每个协程都自带独立的栈,功能强大,但是比较耗内存,性能不如无栈协程。
- 而无栈协程一般是基于状态机(State Machine)来实现的,不使用独立的栈,具体的应用形式叫生成器(Generator)。
常见的有ES 6和Python语言中支持的生成器。这种形式的协程性能更好,而功能要弱于有栈协程,但也够用了。在Rust标准库中支持的协程功能,就属于无栈协程。
(1)什么是生成器
我们先通过一个示例来了解Rust中生成器的用法,如代码清单11-62所示。
代码清单11-62:Rust生成器的用法
#![feature(generators, generator_trait)]
use std::ops::Generator;
fn main() {
let mut gen = || {
yield 1;
yield 2;
yield 3;
yield 4;
};
unsafe {
for _ in 0..4 {
let c = gen.resume();
println!("{:?}", c);
}
}
}在代码清单11-62中,代码第1行使用了#![feature(generators, generator_trait)]特性,这是因为Rust中提供的生成器功能目前属于实验性功能,还未稳定。
代码第2行,引入了std::ops模块中的Generator trait。该trait定义了生成器的行为。
代码第4~9行,创建了一个Generator,从形式上看像闭包,但它不是闭包,而是生成器。其中的yield是专门为生成器引入的关键字。需要注意,生成器不能像闭包那样接收参数。
代码第10行,使用了unsafe块,因为接下来需要调用unsafe的resume方法。在for循环中,调用4次resume方法。该方法会让程序的执行流程跳回到生成器中执行代码,并且在遇到yield关键字时跳出生成器,返回给调用者。生成器的执行流程如图11-12所示。
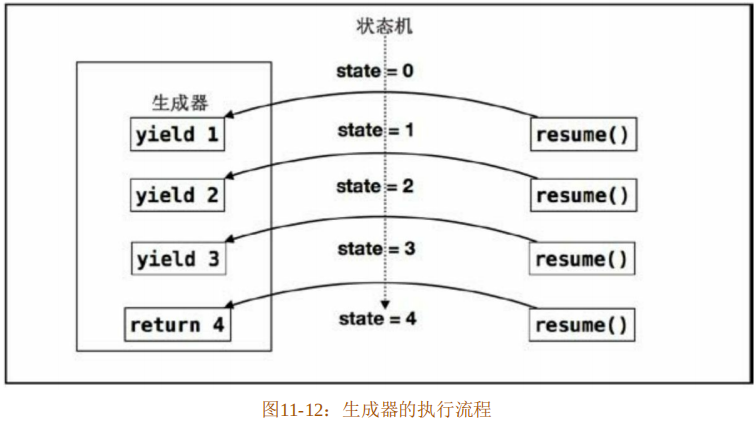
在图11-12中展示了yield和resume的跳转过程。第一次调用resume方法,跳到生成器中,执行到“yield 1”,跳回到调用者。第二次调用resume方法,同样会跳到生成器中,然后继续从上次的“yield 1”位置开始执行代码,直到遇到“yield 2”,再跳回到调用者。依此类推,直到生成器代码执行完毕,到达return那里。
生成器使用yield来设置状态,然后通过调用resume方法来达到状态的流转。在代码清单11-62中,状态从初始状态0一直流转到状态4。整个生成器实际上就是一个状态机。输出结果如代码清单11-63所示。
代码清单11-63:输出结果
Yielded(1)
Yielded(2)
Yielded(3)
Complete(4)该输出结果并非像图11-12 所示那样用简单的数字来表示状态。返回的结果实际上是一种枚举类型 GeneratorState<Y,R>,该类型只包括 Yielded(Y)和 Complete(R)两种值。其中Yielded(Y)表示在生成器执行过程中产生的各种状态,也就是程序在生成器代码中挂起的位置;而Complete(R)表示生成器执行完成后最终返回的值。
(2) 生成器的实现原理
在Rust中Generator被定义为一个trait,如代码清单11-64所示。
代码清单11-64:Generator trait源码
pub trait Generator {
type Yield;
type Return;
unsafe fn resume(&mut self) -> GeneratorState<Self::Yield, Self::Return>;
}在代码清单11-64中,Generator包含了两种关联类型,即Yield和Return,分别对应于yield的状态类型和生成器执行完成后最终返回的类型。
生成器语法像闭包,其实现原理也和闭包类似。比如在代码清单11-62中定义的生成器gen,将会由编译器自动生成一个匿名的枚举体,然后为该枚举体自动实现 Generator。等价代码如代码清单11-65所示。
代码清单11-65:代码清单11-62中生成器实例gen的等价生成代码
#![feature(generators, generator_trait)]
use std::ops::{Generator, GeneratorState};
enum _Gen {
Start,
State1(State1),
State2(State2),
State3(State3),
Done
}
struct State1 { x: u64 }
struct State2 { x: u64 }
struct State3 { x: u64 }
impl Genrator for _Gen {
type Yield = u64;
type Return = u64;
unsafe fn resume(&mut self) -> GeneratorState<u64, u64> {
match std::mem::replace(self, _Gen::Done) {
_Gen::Start => {
*self = _Gen::State1(State1{x: 1});
GeneratorState::Yielded(1)
}
_Gen::State1(State1{x: 1}) => {
*self = _Gen::State2(State2{x: 2});
GeneratorState::Yielded(2)
}
_Gen::State2(State2{x: 2}) => {
*self = _Gen::State3(State3{x: 3});
GeneratorState::Yielded(3)
}
_Gen::State3(State3{x: 3}) => {
*self = _Gen::Done;
GeneratorState::Complete(4)
}
_ => {
panic!("generator rsumed after completion")
}
}
}
}
fn main() {
let mut gen = _Gen::Start;
for _ in 0..4 {
println!("{:?}", unsafe{ gen.resume()});
}
}在代码清单 11-65 中,使用了#![feature(generators, generator_trait)]特性,这是因为Generator目前是未稳定的特性,所以必须在Nightly版本下执行该代码。
首先,编译器会生成一个匿名的枚举体,这里用Gen 来表示。因为在代码清单 11-62中,在生成器实例gen中使用yield和return关键字一 共定义了4种状态,所以在Gen中也包含了4个枚举值,即State1(State1)、State2(State2)、State1(State3)、Done,但还必须包含一个初始状态Start,如代码第3~9行所示。
除Start和Done之外,中间的三种状态需要存储状态值,分别用三个结构体State1、State2和State3表示,如代码第10~12行所示。
从代码第13行开始,为__Gen实现Generator。代码第14行和第15行,分别指定关联类型Yield和Return为u64类型。
代码第16行,实现unsafe的resume方法。在resume方法中调用std::mem::replace方法,传入&mut self和_Gen::Done。每次调用replace方法,都会将self的值替换为__Gen::Done,然后返回替换前的self的值。接下来使用match匹配replace的结果,达到状态转移的目的。
代码第18行的match分支_Gen::Start,代表replace调用返回了 _Gen::Start。那么就将状态转移到 State1,也就是将 self 的值修改为__Gen::State1(State1{x:1}),并返回GeneratorState::Yielded(1)。依此类推,调用一次resume方法,其内部的self的状态就会转移一次,直到结束。
在main函数中,展示了调用过程。定义了可变绑定gen,将__Gen::Start作为初始状态,然后循环4次,分别调用4次resume方法。最终的输出结果和代码清单11-63相同。
当然,代码清单11-65只是一个简单的生成器模拟代码,目的在于阐述生成器的执行原理。实际编译器生成的代码要比这个复杂。
(3) 生成器与迭代器
生成器是非常有用的一个功能。如果只关注计算的过程,而不关心计算的结果,则可以将Return设置为单元类型,只保留Yield的类型,也就是Generator<Yield=T,Return=()>,那么生成器就可以化身为迭代器,如代码清单11-66所示。
代码清单11-66:将生成器用作迭代器
#![feature(generators, generator_trait)]
use std::ops::{Generator, GeneratorState};
pub fn up_to() -> impl Generator<Yield = u64, Return = ()> {
|| {
let mut x = 0;
loop {
x += 1;
yield x;
}
return ();
}
}
fn main() {
let mut gen = up_to();
unsafe {
for _ in 0..10 {
match gen.resume() {
GeneratorState::Yielded(i) => println!("{:?}", i),
_ => println!("Completed"),
}
}
}
}在代码清单11-66中定义了up_to函数,返回一个impl Generator<Yield=64,Return=()>类型。注意,该代码要选择在Rust 2018或者最新的Nightly Rust中执行,因为impl Trait语法是在Rust 2018 中加入的。
在up_to函数中,定义了一个生成器实例,在该生成器中利用loop循环,从0开始,逐渐加1,生成自然数序列。
在main函数中,调用up_to函数,返回了生成器实例绑定给b,注意这里是可变绑定。然后在unsafe中循环调用b的resume方法,并使用match对其结果进行匹配,从而产生了迭代的效果。
但生成器的性能比迭代器更高。因为生成器是一种延迟计算或惰性计算,它避免了不必要的计算,只有在每次需要时才通过yield来产生相关的值。
(4) 用生成器模拟Future
只关注生成器的计算过程而忽略结果,生成器会化身为迭代器。如果反过来,不关心过程,只关注结果,则可以将 Yield 设置为单元类型,只保留Return的类型,也就是Generator<Yield=(),Return=Result<T,E>>,生成器就可以化身为Future,如代码清单11-67所示。
代码清单11-67:用生成器模拟Future
#![feature(generators, generator_trait)]
use std::ops::{Generator, GeneratorState};
fn up_to(limit: u64) ->
impl Generator<Yield = (), Return = Result<u64, ()>>
{
move || {
for x in 0..limit {
yield ();
}
return Ok(limit);
}
}
fn main() {
let limit = 2;
let mut gen = up_to(limit);
unsafe {
for i in 0..=limit {
match gen.resume() {
GeneratorState::Yielded(v) =>
println!("resume {:?}: Pending", i),
GeneratorState::Complete(v) =>
println!("resume {:?} : Ready", i),
}
}
}
}在代码清单11-67中定义的up_to函数返回了impl Generator<Yield=(),Return=Result<u64,()>>类型。同样,在up_to函数中,对应地,修改了yield和return的值。
然后在main函数中,对生成器实例gen进行resume循环调用,对得到的值进行匹配,最终得到的输出结果如代码清单11-68所示。
代码清单11-68:代码清单11-67的输出结果
resume 0 : Pending
resume 1 : Pending
resume 2 : Ready因为不关心生成器执行过程中的状态,所以只要还在计算过程中,就返回 Pending。一旦计算完成,就返回Ready。
Future是一种异步并发模式,它实际上是代理模式和异步开发的混合产物。Future是对“未来”的一种代理凭证,凭借这个凭证可以异步地在未来某个时刻得到确定的结果,而不需要同步等待。比如网购一件商品,你下的订单就可以被看作是一种Future。此时对你来说,订单的
状态是 Pending,你下单后就可以去做其他事情,并不需要花时间关注商品从下单到发货的整个流程。商家看见订单,自然会按流程进行发货,在未来某个时刻,商品就会被快递到你手里,订单的状态就会变成Ready。所以,整个网购过程是异步的,丝毫没有耽误你的日常生活。
然而,严格来说,生成器属于一种半协程(Semi-Coroutine)。半协程是一种特殊的且能力较弱的协程,它只能在生成器和调用者之间进行跳转,而不能在生成器之间进行跳转。所以,要想支持完整的异步编程,还需要在生成器的基础上进一步完善Future并发模式。
11.3.2 Future并发模式
在实际的异步开发中,需要将一个完整的功能切分为一个个独立的异步任务,并且这些任务之间还可能彼此依赖,一个任务的输出也许是另一个任务的输入。比如服务器端处理基本的HTTP请求,就可以分解为建立连接、处理请求、返回响应这三步。如果将每一步都抽象为一个异步计算单元,那么一共就有三个异步计算单元,并且后两步的计算都依赖于前一步的计算结果。而且,每一个异步计算单元还可以细分为更小的异步计算组合。如果想要合理地调度和高效地计算这些异步任务,就需要一个完善的异步系统。
因此,Rust对Future异步并发模式做了一个完整的抽象,包含在第三方库futures-rs中。该抽象主要包含三个部件:
- Future,基本的异步计算抽象单元。
- Executor,异步计算调度层。
- Task,异步计算执行层。
当然,futures-rs库还包含其他部件,但这三个部件属于核心部件。
(1) Future
在Rust中,Future是一个trait,其源码如代码清单11-69所示。
代码清单11-69:Future trait源码
pub trait Future {
type Output;
fn poll(self: Pin<&mut Self>, lw: &LocalWaker)
-> Poll<Self::Output>;
}代码清单11-69展示的是std::future模块中Future trait的源码,它包含了用于指定返回类型的关联类型Output和poll方法。
其中poll方法是Future的核心,它是对轮询行为的一种抽象。先不用管参数中的Pin和LocalWaker类型,后面会详细介绍。在Rust中,每个Future都需要使用poll方法来轮询所要计算值的状态。该方法返回的Poll是一个枚举类型,其源码如代码清单11-70所示。
代码清单11-70:Poll<T>类型源码
pub enum Poll<T> {
Ready(T),
Pending,
}从代码清单 11-70 中可以看出,Poll<T>枚举类型包含了两个枚举值,即 Ready(T)和Pending。该类型和 Option<T>、Result<T,E>相似,都属于和类型。它是对准备好和未完成两种状态的统一抽象,以此来表达Future的结果。对于每个Future来说,无非就是这两种结果。
(2) Executor和Task
Future只是一个基本的异步计算抽象单元,具体的计算工作还需要由Executor和Task共同完成。
在实际的异步开发中,会遇到纷繁复杂的异步任务,还需要一个专门的调度器来对具体的任务进行管理统筹,这个工具就是Executor。具体的异步任务就是Task。拿futures-rs来说,Executor是基于线程池实现的,其工作机制如图11-13所示。
第三方库futures-rs是由很多小的crate组合而成的,其中futures-executor库专门基于线程池实现了一套Executor。
图11-13上半部分,展示了几个关键的复合类型:ThreadPool、PoolState、Message和Task。注意,此处复合类型中的字段或枚举值涉及的具体类型,为演示而做了简化,和实际代码中的有所差异。
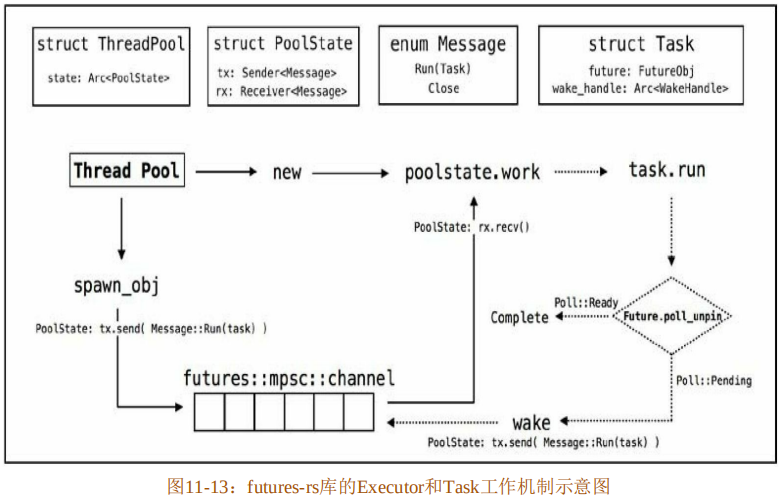
- ThreadPool是一个结构体,包含了一个字段state,设置为Arc<PoolState>类型,是为了共享线程池内的线程信息。
- PoolState 同样是一个结构体,包含了 tx 和 rx 两个字段,分别是Sender<Message>和Receiver<Message>类型。这两个类型看起来与std::sync::mpsc模块中定义的用于Channel通信的发送端和接收端类型相似,但实际上是futures-channel中定义的类型。而tx和rx的作用是类似的,同样用于Channel通信。
- Message是一个枚举类型,包含了两个枚举值,其中最重要的就是Run(Task)。该Message用作发送到Channel中的消息。这样的消息包含两种可能,其中一种是运行Task;另一种是关闭线程池。
- Task 是一个结构体,包含了 future 和 wake_handle 两个字段,分别为 FutureObj 和Arc<WeakHandle>类型。顾名思义,FutureObj就是Future对象,它实际上是futures-executor中实现的自定义Future对象,它是对一个Future trait对象的一种包装;而WeakHandle则是用来唤醒任务的句柄。
图11-13下半部分,展示了Executor完整执行流程的简单示意图。
Executor 提供了一个 Channel,实际上就是一个任务队列。开发者可以通过 ThreadPool提供的spawn_obj方法将一个异步任务(Task)发送(send)到Channel中。实际上,在spawn_obj内部是通过PoolState结构体中存储的发送端tx将Message::Run(task)发送到Channel中的。
通过ThreadPool::new方法,可以从线程池中调用一个线程来执行具体的任务。同时,在该线程中也调用了PoolState结构体的work方法来消费Channel中的消息。实际上,work方法是通过PoolState结构体中存储的接收端rx接收并消费Message::Run(task)的。
就这样,由spawn_obj往Channel中发送消息,由work来接收并消费消息,构成一个完整的工作流程。
当work方法接收到Message::Run(task)之后,会调用Task中定义的run方法来执行具体的task。在run方法中,调用存储于task实例中的FutureObj类型值的poll_unpin方法,将会执行具体的poll方法,返回Pending和Ready两种状态。如果是Pending状态,则通过task实例存储的WakeHandle句柄将此任务再次唤醒,也就是重新将该任务发送到Channel中,等待下一次轮询;如果是Ready状态,则计算任务完成,返回到上层进行处理。
以上就是整个futures-rs核心工作机制的简要概括。通过图11-13,我们可以从整体上把握并建立Rust中Future异步开发的心智模型。
11.3.3 async/await
迄今为止,第三方库futures-rs经历了三个阶段的迭代。在0.1版本中,开发者可以通过then和and_then方法来安排Future异步计算的执行顺序。但是经过一段时间的用户反馈之后,发现这种方式会导致很多混乱的嵌套和回调链,不利于人体工程学。于是就引入了async/await解决方案。又经过两个阶段的重构,目前为0.3版本。
代码清单11-71展示了futures-rs先后提供的两种写法对比。
代码清单11-71:futures-rs两种写法对比
// futures-rs 0.1
fn download_and_write_tweets(
user: String,
socket: Socket,
) -> impl Future<Output = io::Result<()>> {
pull_down_tweets(user)
.and_then(move |tweets|write_tweets(socket))
}
// futures-rs 0.3
async fn download_and_write_tweets {
user: &str,
socket: &Socket,
} -> io::Result<()> {
let tweets = await!(pull_down_tweets(user))?;
await!(write_tweets(socket))
}在代码清单 11-71 中,用两种写法定义了异步函数download_and_write_tweets,执行该函数,需要先执行pull_down_tweets异步函数,再执行write_tweets异步函数。可以看出,第一种写法使用and_then构成了很长的调用链;而第二种写法使用async关键字和await!宏,在语义上要比使用and_then更加直观和精简。
Rust当前以async关键字配合await!宏来提供async/await异步开发方案。在不久的将来,await也会变成关键字。
async/await实际上是一种语法糖。async fn会自动为开发者生成返回值是impl Future类型的函数。就像代码清单11-71中第二种写法生成的代码,实际上等价于第一种写法。
(1) async/await实现原理
Rust不仅仅支持使用async fn定义异步函数,还支持async块,如代码清单11-72所示。
代码清单11-72:async 块示意
let my_future = async {
await!(prev_async_func);
println!("Hello from an async block");
}在代码清单11-72中,直接使用async块来创建一个Future。实际上,使用async fn定义函数在底层也是由async块来生成Future的。图11-14展示了这个过程。
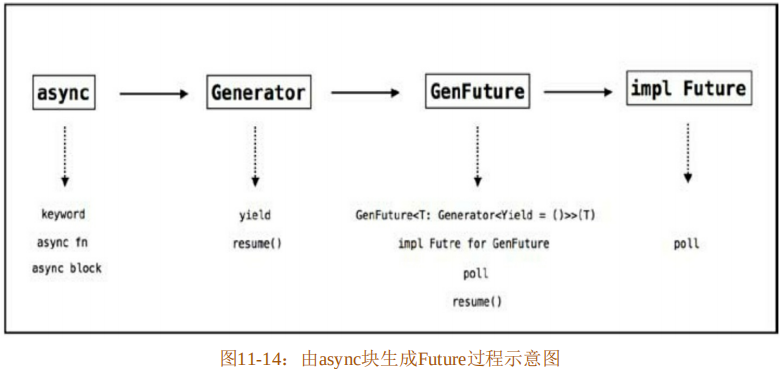
如图11-14所示,async关键字无论是用来定义异步函数,还是定义异步块,在Rust将代码解析为 AST 之后,在 HIR 层都会转换为 async 块的形式。再将 async 块生成一个Generator<Yield=()>类型的生成器来使用。然后将该生成器通过单元结构体GenFuture进行包装,得到一个GenFuture<T:Generator<Yield=()>>(T)类型,最后为该GenFuture实现Future,如代码清单11-73所示。
代码清单11-73:为GenFuture实现Future源码
impl<T: Generator<Yield = ()>> Future for GenFuture<T> {
type Output = T::Return;
fn poll(self: Pin<&mut self>, lw: &LocalWaker)
-> Poll<Self::Output>
{
set_task_waker(lw, ||
match unsafe {Pin::get_mut_unchecked(self).0.resume()}
{
GeneratorState::Yielded(()) => Poll::Pending,
GeneratorState::Complete(x) => Poll::Ready(x),
}
)
}
}代码清单11-73展示了在std::future模块中为GenFuture实现Future的源码。关键在于,在poll方法中调用了resume函数。此处的Pin::get_mut_unchecked(self)会返回一个&mut self,所以这里等价于“&mut self.0.resume()”。通过匹配resume方法的调用结果,来轮询Future的计算结果。这和在代码清单11-67中用生成器模拟Future很相似。
接下来,通过std::future模块中的from_generator函数,将实现了Future的GenFuture作为返回值插入编译器生成的代码中。
以上就是 async 语法糖在编译器内部转化作为返回类型 GenFuture的整个过程。当然,还需要await!宏相互配合才可以。await!宏原理示意图如图11-15所示。
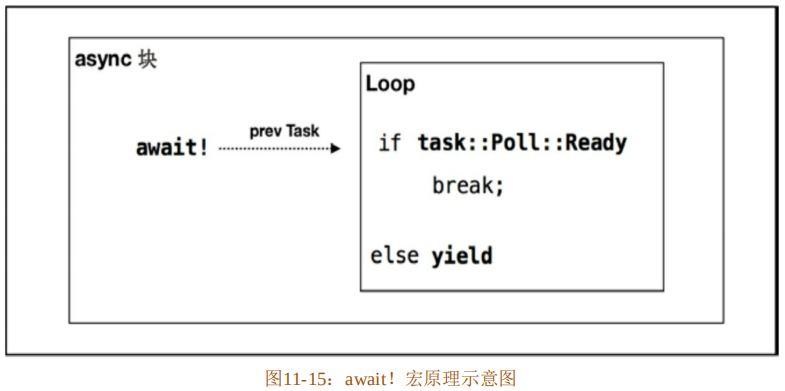
await!宏必须在async块中使用,不能单独使用。因为await!宏实际展开的代码要在loop循环中对轮询结果进行判断。如果是Ready状态,则跳出loop循环;如果是Pending状态,则生成yield。正因为这个yield,才允许async块生成一个Generator<Yield=()>类型的生成器。
(2) Pin与UnPin
在前面的示例中,多次出现Pin类型,这是什么意思呢?Pin<T>实际上是一个被定义于std::pin 模块中的智能指针。它是在 Rust 2018版本中新增的语法,经过多次迭代之后,在Rust 1.30版本中定型为Pin<T>。
那么,为什么需要它呢?回顾代码清单11-62中的生成器实例gen,如果换种写法看看会有什么问题,如代码清单11-74所示。
代码清单11-74:修改代码清单11-62中的生成器实例
let mut gen = || {
let x = 1u64;
let ref_x = &x;
yield 1;
yield 2;
yield 3;
yield 4;
};在代码清单11-74中,为生成器实例增加了两个新的本地变量绑定:x和ref_x,其中ref_x是对x的引用。修改成这样,编译代码时会报错:
error[E0626]: borrow may still be in use when generator yields
| let ref_x = &x;
| ^
| ...
| ------- possible yield occurs here该错误表示Rust不允许在生成器中使用对本地变量的引用,这个问题与生成器实现原理有关。
回顾代码清单 11-65。生成器会由编译器生成相应的结构体来记录状态,当生成器包含对本地变量的引用时,该结构体会生成一种自引用结构体(Self-referential Struct)。代码清单11-75展示了代码清单11-74中生成器实例生成代码。
代码清单11-75:代码清单11-74中生成器实例生成代码
enum _Gen<'a> {
Start,
State1(State1<'a>),
State2(State2),
State3(State3),
Done
}
struct State1<'a> {x: u64, ref_x: &'a su64}
impl<'a> Generator for _Gen<'a> {
type Yield = u64;
type Return = u64;
unsafe fn resume(&mut self) -> GeneratorState<u64, u64> {
match std::mem::replace(self, _Gen::Done) {
_Gen::Start => {
let x = 1;
let state1 = State1{x: x, ref_x: &x};
*self = _Gen::State1(state1);
GeneratorState::Yielded(1)
}
_Gen::State1(State1{x: 1, ref_x: &1}) => {
*self = _Gen::State2(State2{x: 2});
GeneratorState;:Yielded(2)
}
// ...省略
}
}
}在代码清单11-75中,由State1结构体来存储生成器实例中对本地变量的引用,会生成一个自引用结构体,如代码第8行所示,该结构体中字段ref_x的值是对字段x的引用。
在resume函数中,代码第15~17行生成一个自引用结构体的实例在resume函数被调用时,当内部状态从State1转移到State2,也就是代码第20行所示的match分支执行时,说明replace方法已经将State1替换掉了。
replace方法本质上是移动指针的内存位置,将State1替换为State2。这就意味着,实际上State1的所有权已经发生了转移。State1内存位置的改变会影响到字段x的位置,而这时其内部的字段ref_x还在引用字段x的值,这就造成了悬垂指针。这是Rust绝对不允许发生的事情。同时,这也是生成器的resume函数被标记为unsafe的原因。
所以,为了避免这种情况,开发者不得不使用Box<T>或Arc<T>等手段来解决此问题,这就造成了性能上的损耗。而生成器是为异步编程服务的,Rust引入异步编程的目的是为了打造高性能服务开发的首选语言。现在因为自引用结构体的问题而无法让生成器的性能发挥到最大化,这是无法容忍的。所以,Rust 团队必须要解决这个问题。而 Pin<T>类型就是解决方案。
Pin<T>实际上是一个包装了指针类型的结构体,其中指针类型是指实现了Deref的类型。下面我们通过一个示例来了解Pin<T>的用法,如代码清单11-76所示。
代码清单11-76:Pin<T>用法示例
#![feature(pin)]
use std::pin::{Pin, Unpin};
use std::marker::Pinned;
use std::ptr::NonNull;
struct Unmovable {
data: String,
slice: NonNull<String>,
_pin: Pinned,
}
impl Unpin for Unmovable {}
impl Unmovable {
fn new(data: String) -> Pin<Box<Self>> {
let res = Unmovable {
data,
slice: NonNull::dangling(),
_pin: Pinned,
};
let mut boxed = Box::pinned(res);
let slice = NonNull::from(&boxed.data);
unsafe {
let mut_ref: Pin<&mut Self> = Pin::as_mut(&mut boxed);
Pin::get_mut_unchecked(mut_ref).slice = slice;
}
boxed
}
}
fn main() {
let unmoved = Unmovable::new("hello".to_string());
let mut still_unmoved = unmoved;
assert_eq!(still_unmoved.slice,
NonNull::from(&still_unmoved.data));
let mut new_unmoved = Unmovable::new("world".to_string());
std::mem::swap(&mut *still_unmoved, &mut *new_unmoved);
}在代码清单11-76中,代码第1行使用了#![feature(pin)]特性,这是因为目前Pin<T>还是实验性特性。
代码第2行,引入了Pin和Unpin。顾名思义,Pin有“钉”之意。在Rust中,使用Pin<T>则代表将数据的内存位置牢牢地“钉”在原地,不让它移动。Unpin 则正好和 Pin 相对应,代表被“钉”住的数据,可以安全地移动。大多数类型都自动实现了Unpin。
代码第3行,引入了Pinned,这是一个用于标记的结构体,被定义于std::marker模块中。如果一个类型中包含了Pinned,则意味着该类型将不会默认实现Unpin,但不影响手动实现。
代码第4行,引入了NonNull<T>,这是为了创建自引用结构体而使用的。
代码第5~9行,定义了一个自引用结构体Unmovable,它包含的字段slice很可能会引用data字段。另外,Unmovable还包含了Pinned字段,表示它将不会默认实现Unpin。
代码第10行,手动为Unmovable实现Unpin。
代码第11~26行,为Unmovable实现了new方法,它返回一个Pin<Box<Self>>类型的值。在new方法中,首先创建了一个Unmovable实例res,然后使用Box::pinned方法将res生成Pin<Box<Unmovable>>类型的值boxed,再利用NonNull::from函数将boxed实例的data字段转换为NonNull指针绑定给slice变量。接下来,在unsafe块中,通过Pin::as_mut函数从&mut boxed 得到一个 Pin<&mut Self>类型的值mut_ref,在当前代码中具体类型为 Pin<&mut Unmovable>。最后通过Pin::get_mut_unchecked 函数引用 Pin<&mut Unmovable>中的&mut Unmovable,并将其slice字段的值赋值为slice变量。这就创建了一个自引用结构体的实例。
在main函数中,使用new方法创建了Unmovable实例unmoved,然后将其赋值给新的变量still_unmoved,目的是想要转移unmoved的所有权。从第30行和第31行的断言代码中得知,该结构体实例在所有权转移之后,字段的地址并没有改变。slice字段引用的data字段最初的地址,现在断言相等,就证明data字段的地址没有变。Pin<T>类型起作用了。
代码第 32 行和第 33 行,创建了一个新的 Unmovable 实例new_unmoved,使用std::mem::swap 来交换它和 still_unmoved 的引用地址,正常通过。这是因为代码第 10行为Unmovable实现了Unpin。如果将代码第10行注释掉,swap代码将编译失败。如果此时继续将Unmovable的Pinned类型字段注释掉,则该结构体会默认实现Unpin,swap代码将正常编译。
现在回顾在代码清单11-73中GenFuture实现poll方法时,使用了Pin<&mut Self>,就确保该类型最终生成的生成器不会出现因为自引用结构体而产生未定义行为的情况。然后在需要时使用Pin::get_mut_unchecked 函数获取其包含的可变借用。Pin<T>结构体也包含了很多其他函数,读者可以到标准库文档中自行查看。
(3) async/await异步开发示例
当前,要想使用Rust进行异步开发,需要配合使用标准库和第三方futures-rs库。这是因为标准库中引入了Future和Task两种类型,是为了配合实现async/await关键字。而Future的大部分功能都由futures-rs来提供,未来标准库和futures-rs库可能会有所变化,但是大体的原理和机制基本不会改变,要变的也只能是API。
接下来通过一个具体的示例来回顾 Rust 异步开发。使用 cargo new命令创建一个新的crate,命名为“futures-demo”。在Cargo.toml文件中引入第三方库futures-preview,本书代码使用的是0.3.0-alpha.7版本,然后修改main.rs文件,如代码清单11-77所示。
代码清单11-77:async/await异步开发示例
#![feature(arbitrary_self_types, futures_api)]
#![feature(async_await, await_macro, pin)]
use futures::{
executor::ThreadPool,
task::SpawnExt,
};
use std::future::{Future};
use std::pin::Pin;
use std::task::*;
pub struct AlmostReady {
ready: bool,
value: i32,
}
pub fn almost_ready(value: i32) -> AlmostReady {
AlmostReady{ ready: false, value }
}
impl Future for AlmostReady {
type Output = i32;
fn poll(self: Pin<&mut Self>, lw: &LocalWaker) ->
Poll<Self::Output>
{
if self.ready {
Poll::Ready(self.value + 1)
} else {
unsafe { Pin::get_mut_unchecked(self).ready = true; }
lw.wake();
Poll::Pending
}
}
}
fn main() {
let mut executor = ThreadPool::new().unwrap();
let future = async {
println!("howdy!");
let x = await!(almost_ready(5));
println!("done: {:?}", x);
};
executor.run(future);
}在代码清单11-77中使用了很多特性,包括#![feature(arbitrary_self_types,futures_api)]和#![feature(async_await,await_macro,pin)]。这些都是异步开发需要的未稳定特性。
代码第3~6行,引入了futures-rs库中的executor::ThreadPool和task::SpawnExt。回想一下Future系统,这里需要executor和task模块来调度和执行具体的异步任务。
代码第7~9行,引入了标准库中的Future、Pin和task相关类型。它们是为async/await异步语法服务的。
代码第10~13行,创建了AlmostReady结构体,包含bool类型的ready和i32类型的value两个字段。
代码第14~16行,创建了almost_ready函数,它接收一个i32类型的值,返回一个ready默认为false的AlmostReady结构体实例。
代码第 17~30 行,为 AlmostReady 结构体实现 Future。其中 poll方法的参数需要是Pin<&mut Self>类型,以及一个可以唤醒任务的句柄 lw,它是一个引用类型&LocalWaker,如果任务已经准备好轮询,则由它来通知Executor进行调度。在poll方法的实现中,会判断当前任务,也就是 AlmostReady 实例的 ready 字段是否为 true。如果为 true,则返回Poll::Ready(self.value+1),表示异步计算的最终结果;如果为false,则继续进行计算,直到将ready字段设置为true,代表此时计算已完成。同时,通过lw句柄调用wake方法,将任务再次唤醒,等待下一次轮询。所谓唤醒,实际上就是将该异步任务重新加入任务队列中。可以回顾图11-13展示的Executor和Task工作机制。最后返回Poll::Pending,代表本次轮询的结果。
接下来,在main函数中定义和执行异步任务。
代码第32行,通过ThreadPool::new方法创建一个调度器实例executor。
代码第33~37行,通过async块创建Future实例future。在async块中将almost_ready函数返回的初始AlmostReady实例置于await!宏中,等待异步任务执行的结果。
代码第38行,调用executor的run方法将future传入,异步任务将执行。继续回顾图11-13展示的Executor和Task工作机制。在run方法中,会将传入的future打包成一个FutureObj对象,并将其通过内置的spawn_obj方法发送到Channel队列中,等待work方法执行该任务。
对于该示例代码,可以到随书源码中本章目录下的futures-demo项目中进行查看。最后,编译运行该示例代码,输出结果如代码清单11-78所示。
代码清单11-78:async/await异步开发示例的输出结果
howdy!
done: 6回顾整个异步开发机制,实际上可以总结为两点:
- 实现Future,构造异步任务。
- 生成Task,计算异步任务。
其中Task就像是在线程基础上又抽象出来的一层“轻量级线程”,其使用语法也和线程差不多,比如在futures-rs库中内置了spawn_obj和spawn等函数来方便开发者将Future放入其中,生成异步任务。正因为如此,也有人将Future异步开发体系称为用户级线程。
在futures-rs库中还提供了很多方便组合或嵌套Future异步任务的各种组合函数,限于篇幅,这里就不一一介绍了,读者可以自行查看其文档。
11.4 数据并行
在过去的几十年里,人类不停地提升计算机的算力。计算机在许多领域的发展十分迅猛,随着人类前进的步伐,越来越多的领域对计算的要求越来越高,待解决问题的规模也在不断增加。因此,对并行计算的要求就越来越强烈。
对于这个问题大致有两种解决方案:任务并行(Task Parallelism)和数据并行(Data Parallelism)。任务并行是指将所需要执行的任务分配到多个核上;数据并行是指将需要处理的数据分配到多个核上。因为数据并行处理起来比任务并行更加简单和实用,所以得到重点关注。
按Flynn分类法,将计算机系统结构分为四类,如图11-16所示。

- SISD是指单指令单数据的单CPU机器,它在单一的数据流上执行指令。可以说,任何单CPU的计算机都是SISD系统。
- MISD则是指有N个CPU的机器。在这种架构下,底层的并行实际上是指令级的并行,也就是说,有多个指令来操作同一组数据。但是MISD在实际中很少被用到。
- SIMD 是指包含了多个独立的 CPU,每一个 CPU 都有自己的存储单元,可以用来存储数据。所有的CPU可以同时在不同的数据上执行同一个指令,也就是数据并行。这种架构非常实用,便于算法的设计和实现。
- MIMD是应用最广泛的一类计算机体系。该架构比SIMD架构更强,通常用来解决SIMD无法解决的问题。
11.4.1 什么是SIMD
SIMD的思想其实很容易理解。以加法指令为例,如果采用SISD架构来计算,则需要先访问内存,取得第一个操作数,然后再访问内存,取得第二个操作数,最后才能进行求和运算。但是如果采用SIMD架构,则可以一次性从内存中获得两个操作数,然后执行求和运算。
更专业的描述是,SIMD是一种采用一个控制器控制多个CPU,同时对一组数据(向量数据)中的每一个数据分别执行相同的操作而实现空间上数据并行的技术。
(1) 起源和历史
SIMD起源于美国首批超级计算机之一的ILLIAC IV大型机中,它拥有64个处理器单元,可以同时进行64个计算。随着现代多媒体技术的发展,各大CPU生产商陆续扩展了多媒体指令集,允许这些指令一次处理多个数据。最早是Intel的MMX(MultiMedia eXtensions)指令集,包含了57个多媒体指令、8个64位寄存器。然后是SSE(Streaming SIMD Extensions)指令集,它弥补了MMX浮点数支持不足的问题,并将寄存器的宽度扩展到128位,引入了70个新指令。接下来陆续出现了SSE2、SSE3、SSE4和SSE5指令集。指令集的不断扩展,其实背后暗含了CPU巨头之间的市场战争。但是对于开发者来说,就比较麻烦了。
2011年Intel发布了全新的处理器微架构,其中增加了新的指令集AVX(Advanced Vector Extensions),进一步把寄存器的宽带扩展到256位,并且革新了指令格式,支持三目运算。我国“天河二号”超级计算机的核心技术便是AVX-512的SIMD,该技术将寄存器的宽度扩展到512位。AVX具有256位寄存器,可同时进行4个64位计算,或8个32位计算,或16个16位计算,甚至32个8位计算。
(2) 术语介绍
按寄存器的宽度可以将SIMD看作不同的并行通道。拿AVX-256来说,如果按4个64位进行计算,就可以看成是4个并行计算通道。而在SIMD中并行计算可以分为多种计算模式,其中有垂直计算和水平计算,如图11-17所示。
在垂直计算中,每个并行通道都包含的待计算值称为标量值,通道按水平方向进行组织。将加法运算中X和Y的数据在垂直方向上进行求和。在垂直计算中,每组计算的标量值都来自不同的源。水平计算则是将并行通道垂直组织,依次对两个相邻通道的标量值进行求和。在水平计算中,每组计算的标量值都来自同一个源。
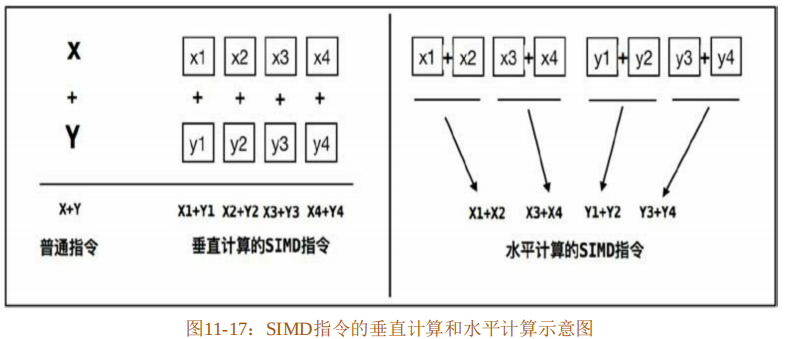
这种并行计算也是有限制的。对于不同的指令集,一次数据并行能接受的长度是固定的,比如AVX-256,能接受的长度为256字节。
编写SIMD数据并行的代码称为向量化(Vectorization)。这是因为向量(Vector)是一个指令操作数,包含一组打包到一维数组的数据元素。大多数SIMD指令都是对向量操作数进行操作的,所以向量也被称为SIMD操作数或打包操作数。数据并行意味着可以同时对向量的所有数据元素执行变换操作。所以,将编写程序使用向量处理器的过程,称为向量化、矢量化或SIMD化。向量化可以由编译器自动优化,也可以由程序员手动指定。
11.4.2 在Rust中使用SIMD
Rust从1.27版本开始支持SIMD,并且默认为x86和x86_64目标启用SSE和SSE2优化。Rust基本支持市面上90%的SIMD指令集,从SSE到AVX-256。不过,目前还不支持AVX-512,在不久的将来会支持。
Rust 通过标准库std::arch 和第三方库 stdsimd 结合的方式来支持SIMD。Rust对SIMD的支持是属于比较底层的,在标准库中支持多种CPU平台架构,比如x86、x86_64、ARM、AArch64等。每种架构都有相应的模块,比如std::arch::x86模块定义的就是与x86平台相关的SIMD指令。并且在平台模块中所有的函数都是unsafe的,因为调用不支持的平台指令可能会导致未定义行为。
SIMD使用示例
现在我们来看一个简单的示例。使用 cargo new 命令创建一个新的crate,命名为“simd-demo”。在Cargo.toml文件中加入依赖的第三方库stdsimd,本书示例使用0.1.0版本,然后编写src/main.rs文件,如代码清单11-79所示。
代码清单11-79:SIMD使用示例
#![feature(stdsimd)]
use ::std as real_std;
use stdsimd as std;
#[cfg(target_arch = "x86")]
use ::std::arch::x86::*;
#[cfg(target_arch = "x86_64")]
use ::std::arch::x86_64::*;
fn main() {
if is_x86_feature_detected!("see4.2") {
#[target_feature(enable = "see4.2")]
unsafe fn worker() {
let needle = b"\r\n\t ignore this ";
let haystack = b"Split a \r\n\t line ";
let a = _mm_loadu_si128(needle.as_ptr() as *const _);
let b = _mm_loadu_si128(haystack.as_ptr() as *const _);
let idx = _mm_cmpestri(
a, 3, b, 20, _SIDD_CMP_EQUAL_ORDERED
);
assert_eq!(idx, 8);
}
unsafe {worker();}
}
}在代码清单11-79 中,首先使用了#![feature(stdsimd)]特性,这意味着目前使用 stdsimd库需要Nightly环境。
代码第2行,使用了use的别名功能,将标准库std的库名换成了另外一个名字“real_std”。因为这里想把std这个名称指代为stdsimd库,如代码第3行所示。
代码第4行,使用了#[cfg(target_arch="x86")]条件编译属性,相当于静态检测CPU平台架构,如果是x86平台,则编译该属性下方的代码,也就是引入在std::arch::x86模块中定义的函数。
代码第6行,同理,静态检测CPU平台为x86_64,然后进行条件编译。
在main函数中,代码第9行的if条件使用了is_x86_feature_detected!("sse4.2")宏,它是一种动态检测CPU平台的技术,因为有时需要在运行时来检测CPU平台。这里是判断当前代码执行的CPU平台是否支持SSE4.2指令集。
代码第11~20行,定义了一个unsafe函数worker,该函数将使用SIMD指令来执行字符串搜索任务。因为要用到SIMD指令,所以该函数被标记为unsafe的。
代码第12行和第13行,分别定义了搜索用到的两个字符串,即needle和haystack。这里是想要在haystack中查找匹配needle的子串位置。
代码第14行,调用了_mm_loadu_si128函数,该函数接收一个_m128i类型的原生指针,它会从内存中将长度为 128 位的整数数据加载到向量寄存器中。它实际调用的是 Intel 的_mm_loadu_si128指令。这里是将needle字符串加载到向量寄存器中。
代码第 15 行,同理,将 haystack 字符串加载到向量寄存器中,这个过程也称为打包字符串。
代码第16行,调用了_mm_cmpestri函数。该函数的第一个参数a是指打包好的needle字符串;第二个参数是想要检索的长度,这里指定为3;第三个参数是打包好的haystack字符串b;第四个参数是其长度,这里指定为20;第五个参数_SIDD_CMP_EQUAL_ORDERED是指定比较模式说明符,它代表字符串相等检测模式。所以,整个_mm_cmpestri函数要做的就是在haystack字符串中查找匹配needle前三位的索引位置。
代码第19行,通过断言说明,满足匹配条件的字符串索引位置是8。
最后执行cargo run命令,该段代码可以正常编译运行。请注意运行该段代码的具体CPU架构,如果其不支持SSE4.2,则无法运行。
以上是手动使用内置的平台函数向量化代码,其实Rust还可以利用LLVM自动向量化。在src目录下新增auto_vector.rs文件,并编写新代码,如代码清单11-80所示。
代码清单11-80:利用LLVM自动向量化为AVX2指令集
fn add_quickly_fallback(a: &[u8], b: &[u8], c: &mut [u8]) {
for ((a, b), c) in a.iter().zip(b).zip(c) {
*c = *a + *b;
}
}
#[cfg(any(target_arch = "x86", target_arch = "x86_64"))]
#[target_feature(enable = "avx2")]
unsafe fn add_quickly_avx2(a: &[u8], b: &[u8], c: &mut [u8]) {
add_quickly_fallback(a, b, c)
}
fn add_quickly(a: &[u8], b: &[u8], c: &mut [u8]) {
#[cfg(any(target_arch = "x86", target_arch = "x86_64"))]
{
if is_x86_feature_detected!("avx2") {
println!("support avx2");
return unsafe {add_quickly_avx2(a, b, c)}
}
}
add_quickly_fallback(a, b, c)
}
fn main() {
let mut dst = [0, 2];
add_quickly(&[1, 2], &[2, 3], &mut dst);
assert_eq!(dst, [3, 5])
}在代码清单11-80中,代码第1~5行,首先定义了add_quickly_fallback函数,可以将传入的第三位参数切片中的元素替换为前两位参数切片的元素之和。
代码第6~10行,对add_quickly_avx2函数使用了#[cfg(any(target_arch="x86",target_arch="x86_64"))]和#[target_feature(enable="avx2")]属性修饰,目的就是为了让LLVM自动向量化该函数,限定平台范围为x86和x86_64,并且向量化为AVX2指令集。在该函数内部调用了add_quickly_fallback函数。
代码第11~20行,定义了add_quickly函数。在该函数内部同样使用了#[cfg(any(target_arch="x86",target_arch="x86_64"))]属性限定平台范围为x86和x86_64。在此限定下,又使用动态检测宏is_x86_feature_detected!("avx2")判断当前执行平台是否支持AVX2指令集,只有在支持的情况下,才可以使用add_quickly_avx2函数。如果当前执行平台支持AVX2,则代码第15行的打印语句会有相应的输出。
如果不是x86或x86_64平台,则继续使用add_quickly_fallback函数进行计算。这是一种平台兼容性策略。最后,在main函数中调用add_quickly函数。
接下来,还需要修改Cargo.toml文件,才能执行该段代码。因为在当前src目录下出现了main.rs和auto_vector.rs两个带有main函数的文件。打开Cargo.toml文件,进行bin相关配置,如代码清单11-81所示。
代码清单11-81:在Cargo.toml文件中进行bin相关配置
[[bin]]
path = "src/auto_vector.rs"
name = "auto_vector"
[[bin]]
path = "src/main.rs"
name = "main"通过这样的配置就可以让crate支持多个main函数文件。
最后,只要执行cargo run–bin auto_vector命令,就可以执行auto_vector.rs中的代码。同理,如果想执行main.rs中的代码,则需要使用cargo run–bin main命令。
SIMD命名说明
在代码清单11-79中,调用SIMD函数的命名乍一看会感觉非常奇怪,但实际上它们的命名遵循一定的规则。就拿x86平台来说,其主要支持以下几种类型:
- __m128i,代表128位宽度的整数向量类型。
- __m128,代表128位宽度的4组f32类型。
- __m128d,代表128位宽度的2组f64类型。
- __m256i,代表256位宽度的整数向量类型。
- __m256,代表256位宽度的8组f32类型。
- __m256d,代表256位宽度的4组f64类型。
也有其他类型,这里不再赘述。像ARM平台支持的类型命名就比较直观,比如:
- float32x2_t,代表64位宽度的2组打包f32向量类型。
- float32x4_t,代表128位宽度的2组打包f32向量类型。
- int32x2_t,代表64位宽度的2组打包i32向量类型。
- int32x4_t,代表128位宽度的2组打包i32向量类型。
虽然各个平台的命名格式不同,但是其内部还是有规则可循的。同理,函数命名也有规则。就拿函数std::arch::x86::_mm256_add_epi64来说,以_mm256_开头的代表AVX指令,然后跟随的是对应的指令操作,比如add、mul或abs之类的,最后是使用的类型,如_pd用于双精度或64位浮点数,_ps用于32位浮点数,_epi32用于32位整数。在不同的平台架构下,基本的函数命名也遵循类似的组合规则。
第三方库介绍
除了官方提供的第三方库stdsimd,Rust社区中还有很多simd库,其中比较突出的是faster和simdeez。这两个库的特色是,相比于stdsimd做了更进一步的抽象,对开发者友好。
就拿 faster 来说,它封装了很多函数,开发者就不需要记忆标准库中各个平台下函数的命名规则了,如代码清单11-80所示。
代码清单11-82:第三方库faster提供的函数示例
use faster::*;
fn main() {
let two_hundred = (&[2.0f32; 100][..]).simd_iter()
.simd_reduce(f32s(0.0), f32s(0.0), |acc, v| acc + v)
.sum();
assert_eq!(two_hundred, 200.0f32);
}从代码清单11-82中可以看出,faster库提供了很多可读性很高的函数来方便开发者开发SIMD代码。
11.5 小结
随着多核CPU的普及,多线程并发编程正逐渐成为主流的编程范式。但是多线程并发编程与生俱来的问题十分严重,使得开发者极难编写出正确的多线程并发程序。Rust语言为安全而生,它不仅能保证内存安全,还能保证并发安全。Rust依靠严谨的类型系统和所有权系统,帮助开发者在编译时就能发现多线程并发程序中出现的数据竞争问题,从而保证线程安全。
在 Rust 标准库中提供了保证线程同步的互斥锁和读写锁,以及屏障和条件变量。Rust也从 C++11 那里继承了多线程内存模型,实现了原子类型。基于“使用通信来共享内存”的理念,提供了多生产者单消费者通信队列,可以实现跨线程通信,从而实现无锁编程。
通过本章中提供的大量多线程编程示例,可以使读者对使用Rust编写正确的多线程并发程序有更深入的了解。
除了多线程安全并发,Rust的另一个目标是成为高性能网络服务开发的首选语言。所以,Rust 语言开始逐步支持 async/await 异步开发。通过本章的学习,我们了解到 Rust 支持async/await的曲折过程,同时也感受到了Rust异步开发的方便和强大之处。虽然目前异步开发还未稳定,但也用不了多久就会稳定的。
作为现代化系统编程语言,Rust还支持SIMD数据并行。数据并行和异步开发类似,还未完全稳定,如果想使用它,则需要准备Nightly环境。
相信在不远的将来,Rust在并发编程和数据并行领域将大放异彩。




