语言影响或决定人类的思维方式。
Rust是一门混合范式的编程语言,有机地融合了面向对象、函数式和泛型编程范式。它并非将这些特性进行简单堆砌,而是通过高度一致性的类型系统融合了这三种范式的编程思想。
- 可以通过impl关键字配合结构体和trait来实现面向对象范式中的多态和封装。
- 也可以通过函数、高阶函数、闭包、模式匹配来实现函数式范式中的一些编程工具。
- Rust支持零成本静态分发的泛型编程,并且将它很好地融入了其他两种编程范式中,提供了更高的抽象层次。
通过将这三种编程范式完美融合起来,Rust语言拥有了更高程度的抽象以及更强的表达能力。
函数式语言的历史要比面向对象语言悠久,它源自古老的 LISP 语 言,其后发明的语言或多或少都受到了函数式编程思想的影响,比如Python、Ruby,以及更纯的函数式语言Haskell。随着摩尔定律的失效, CPU性能的提升转为主要依赖核数的增加,多核时代到来后,函数式编程因为其天生对并发友好的特性又逐渐受到了重视。所以近年来很多新诞生的语言也吸收了函数式范式的诸多特性,比如Elixir、Scala、Swift都受到了LISP和Haskell的影响,对代数数据类型(algebraic data type)、模式匹配、高阶函数、闭包等特性各有所支持。甚至一些年代久远的主流语言,比如C++和Java也都开始吸收函数式语言的特性。Rust作为一门在多核时代诞生的现代编程语言,引入函数式编程范式完全是顺势而为的。
本章内容主要从函数和闭包两个方面来探讨Rust对函数式编程范式的支持,还会讲迭代器及其在闭包中的应用。
6.1 函数
对于一些重复执行的代码,可以将其定义为一个函数,方便调用。在第2章我们已经了解到,可以使用fn关键字来定义函数。一个标准的函数定义如代码清单6-1所示。
代码清单6-1:函数定义示例
// 函数定义形式
fn func_name(arg1: u32, arg2: String) -> Vec<u32> {
/* 函数体 */
}
// 利用Raw identifier将语言关键字用作函数名(Rust 2018版本)
fn r#match(nddele: &str, haystack: &str) -> bool {
haystack.contains(needle)
}
fn main() {
assert!(r#match("foo", "foobar"));
}如代码清单 6-1 所示,fn 关键字后面为函数名称,通常以蛇形命名法(snake_case)命名,否则编译器会发出警告。函数参数必须明确地指定类型,如果有返回值也必须指定返回值的类型。需要注意的是,Rust中的函数参数不能指定默认值。函数体被包含于花括号之内,除函数体之外的函数声明被称为函数签名。可以说,一个函数是由函数签名和函数体组合而成的。
一般来说,函数定义时不允许直接使用语言中的保留字和关键字等作为函数名。但是在Rust 2018版本中,通过将原生标识操作符(Raw Identifier)r#作为前缀,即可使用关键字为函数命名,该语法一般用于FFI中,用于避免C函数名和Rust的关键字或保留字重名而引起的冲突,如代码清单6-1的第6行所示。
通过前面的章节我们了解到,函数参数可以按值传递,也可以按引用传递。当参数按值传递时,会转移所有权或者执行复制(Copy)语义。当参数按引用传递时,所有权不会发生变化,但是需要有生命周期参数。当符合生命周期参数省略规则时,编译器可以通过自动推断补齐函数参数的生命周期参数,否则,需要显式地为参数标明生命周期参数。
函数参数也分为可变和不可变。Rust的函数参数默认不可变,当需要可变操作的时候,需要使用mut关键字来修饰。代码清单6-2展示了当参数按值传递时使用mut的情况。
代码清单6-2:按值传递的参数使用mut关键字
fn modify(mut v: Vec<u32>) -> Vec<u32> {
v.push(42);
v
}
fn main() {
let v = vec![1, 2, 3];
let v = modify(v);
println!("{:?}", v);
}代码清单6-2定义了modify函数,以对传入其中的动态数组进行修改,所以需要其参数为可变的。main函数的第6行声明的变量绑定v是Vec<u32>类型,将其传到modify中,它的所有权会被转移。对于第1行的modify函数来说,参数相当于重新声明的另一个变量绑定, mut关键字被放到参数变量前面作为可变修饰。所以,在main函数中,声明v的时候并没有使用mut关键字。
代码清单6-3展示了按引用传递参数时mut的用法。
代码清单6-3:按引用传递参数时的mut用法
fn modify(v: &mut [u32]) {
v.reverse();
}
fn main() {
let mut v = vec![1, 2, 3];
modify(&mut v);
println!("{:?}", v); // [3, 2, 1]
}代码清单6-3中的modify函数参数本身已经是可变引用类型&mut [u32],所以此处的函数参数前面不需要再使用 mut 关键字。在 main 函数中,如果想把第5 行声明的变量绑定v作为可变引用参数,就必须使用mut关键字来将其声明为可变变量。
6.1.1 函数屏蔽
当声明变量绑定之后,如果再次声明同名的变量绑定,则之前的变量绑定会被屏蔽,这叫作变量屏蔽(variable shadow)。变量可以如此,但函数不能被多次定义。假如代码清单6-3中的modify函数被定义多次,编译器会报如下错误:
error[E0428]: the name `modify` is defined multiple times可以通过显式地使用花括号将同名的函数分隔到不同的作用域中,这样编译器就不会报错。也就是说,在同一个作用域中不能定义多个同名函数,因为默认的函数定义只在当前作用域内有效,会屏蔽作用域外的同名函数,如代码清单6-4所示。
代码清单6-4:作用域内的函数会屏蔽掉作用域外的同名函数
fn f() {print!("1");}
fn main() {
f(); // 2
{
f(); // 3
fn f() {print!("3")}
}
f(); // 2
fn f() {print!("2");}
}代码清单6-4的输出结果为232。在main函数第9行定义的函数f屏蔽了main函数外定义的函数f,所以第3行和第8行会输出2。第6行定义的函数f则屏蔽了main函数中定义的函数f,所以第5行会输出3。
6.1.2 函数参数模式匹配
函数中的参数等价于一个隐式的let绑定,而let绑定本身是一个模式匹配的行为。所以函数参数也支持模式匹配,如代码清单6-5所示。
代码清单6-5:函数参数支持模式匹配
#[derive(Debug)]
struct S{i: i32}
fn f(ref _s: S) {
println!("{:p}", _s); // 0x7ffdd1364b80
}
fn main() {
let s = S{i: 42};
f(s);
// println!("{:?}", s);
}代码清单6-5中定义了函数f,其参数使用ref关键字来修饰,这意味着要使用模式匹配来获取参数的不可变引用。与ref相对的是ref mut,ref mut用来匹配可变引用。所以,代码第4行才可以通过"{:p}"来打印指针地址。但是main函数中作为参数传递的变量绑定s的所有权会被转移。
除了ref和ref mut,函数参数也可以使用通配符来忽略参数,如代码清单6-6所示。
代码清单6-6:使用通配符忽略参数
fn foo(_: i32) {
// ...
}
fn main() {
foo(3);
}实现某个trait中的方法时,有时并不会用到其函数签名中声明的所有参数,这时可以使用通配符来进行忽略,这样不会引起编译错误。
Rust 中的 let 语句可以通过模式匹配解构元组(Tuple),函数参数也可以,如代码清单6-7所示。
代码清单6-7:函数参数利用模式匹配来解构元组
fn swap((x, y): (&str, i32)) -> (i32, &str) {
(y, x)
}
fn main() {
let t = ("Alex", 18);
let t = swap(t);
assert_eq!(t, (18, "Alex"));
}在代码清单6-7中,函数swap的参数利用了模式匹配来解构元组。当然,如果只想解构元组中的单个值,则使用通配符将其他值忽略掉即可。
6.1.3 函数返回值
Rust中的函数只能有唯一的返回值,即便是没有显式返回值的函数,其实也相当于返回了一个单元值()。如果需要返回多个值,亦可使用元组类型,如代码清单6-8所示。
代码清单6-8:使用元组类型让函数返回多个值
fn addsub(x: isize, y: isize) -> (isize, isize) {
(x + y, x - y)
}
fn main() {
let (a, b) = addsub(5, 8);
println!("a:{:?}, b: {:?}", a, b);
}代码清单6-8中的addsub函数返回了元组类型,main函数中使用let模式匹配解构了返回的元组,分别声明了变量绑定a和b。
Rust语言提供了return关键字来返回函数中的值。对于只需要返回函数体最后一行表达式所求值的函数,return可以省略,比如addsub函数。在某些控制结构中,比如循环或条件分支,如果需要提前退出函数并返回某些值,则需要显式地使用return关键字来返回,如代码清单6-9所示。
代码清单6-9:使用return提前返回示例
fn gcd(a: u32, b: u32) -> u32 {
if b == 0 {return a;}
return gcd(b, a % b);
}
fn main() {
let g = gcd(60, 40);
assert_eq!(20, g);
}在代码清单 6-9 中,函数 gcd 使用欧几里得算法(辗转相除法)求两数中的最大公约数。如果a%b的余数不为0,则将b和a相互置换,将余数作为b的值,继续递归求值;如果余数为0,则提前返回a。其实此例中如果gcd函数使用if-else条件分支,阅读性会更好一些。
我们在第2章中见到过函数返回值类型为“!”的发散函数(diverging function),这类函数将永远不会有任何返回值。
6.1.4 泛型函数
Rust的函数也支持泛型。通过实现泛型函数,可以节省很多工作量,如代码清单 6-10所示。
代码清单6-10:实现泛型函数示例
use std::ops::Mul;
fn square<T: Mul<T, Output=T>>(x: T, y: T) -> T {
x * y
}
fn main() {
let a: i32 = square(37, 41);
let b: f64 = square(37.2, 41.1);
assert_eq!(a, 1517);
assert_eq!(b, 1528.92); // 浮点数执行结果可能有所差别
}代码清单6-10实现了一个求乘积的函数square,该函数参数并未指定具体的类型,而是用了泛型T,对T只有一个Mul trait限定,即只有实现了Mul的类型才可以作为参数,从而保证了类型安全,这是实现泛型函数需要注意的地方。因为Mul trait有关联类型,所以这里需要显式指定为Output=T。这样,在main函数中可以将其应用于i32或f64等类型,而不需要单独为某个类型实现一遍square函数。
注意,这里调用square函数的时候并未指定具体类型,而是靠编译器来进行自动推断的。此示例使用的都是基本原生类型,编译器推断起来比较简单。但肯定存在编译器无法自动推断的情况,此时就需要显式地指定函数调用的类型,需要用到第3章提到过的turbofish操作符::<>,如代码清单6-11所示。
代码清单6-11:使用turbofish操作符
use std::ops::Mul;
fn square<T: Mul<T, Output=T>>(x: T, y: T) -> T {
x * y
}
fn main() {
let a = square::<u32>(37, 41);
let b = square::<f32>(37.2, 41.1);
assert_eq!(a, 1517);
assert_eq!(b, 1528.9199);
}代码清单6-11的第6行和第7行使用turbofish操作符指定了具体的类型,因而就不需要在变量绑定a和b之后再次显式地指定类型了。
6.1.5 方法与函数
Rust中的方法和函数是有区别的。方法来自面向对象编程范式,在语义上,它代表某个实例对象的行为。函数只是一段简单的代码,它可以通过名字来进行调用。方法也是通过名字来进行调用的,但它必须关联一个方法接收者。
代码清单6-12中为结构体User实现了方法。
代码清单6-12:为结构体User实现方法
#[derive(Debug)]
struct User {
name: &'static str,
avatar_url: &'static str,
}
impl User {
fn show(&self) {
println!("name: {:?}", self.name);
println!("avatar: {:?}", self.avatar_url);
}
}
fn main() {
let user = User {
name: "Alex",
avatar_url: "https://avatar.com/alex"
};
// User::show(&user);
user.show();
}代码清单6-12中定义了结构体User,包含两个成员字段name和avatar_url。我们使用impl关键字为User实现了show方法,其参数为 &self。此处self为结构体User的任意实例,&self则为实例的引用。
这样就可以在main函数中使用点操作来调用show方法了(代码第18行),而结构体实例 user 会被隐式传递给 show 方法,user 就是 show方法的接收者。user.show 等价于User::show(&user)这样的函数调用。在第7章中还会讲到更多关于结构体和方法的内容。
6.1.6 高阶函数
在数学和计算机科学里均有高阶函数的定义。在数学中,高阶函数也叫算子或泛函。比如微积分中的导数就是一个函数到另一个函数的映射。在计算机科学里,高阶函数是指以函数作为参数或返回值的函数,它也是函数式编程语言最基础的特性。Rust语言也支持高阶函数,因为函数在Rust中是一等公民。函数可以作为参数进行传递,如代码清单6-13所示。
代码清单6-13:函数本身作为参数
fn math(op: fn(i32, i32) -> i32, a: i32, b: i32) -> i32 {
op(a, b)
}
fn sum(a: i32, b: i32) -> i32 {
a + b
}
fn product(a: i32, b: i32) -> i32 {
a * b
}
fn main() {
let (a, b) = (2, 3);
assert_eq!(math(sum, a, b), 5);
assert_eq!(math(product, a, b), 6);
}代码清单6-13的第1行代码定义了函数math,其中第一个参数op类型为fn(i32,i32)->i32,代表其为一个函数。第4行到第6行定义了一 个求和函数sum,第7行到第9行定义了一个求积函数product,然后在main函数中将sum和product分别作为参数传到math中进行调用,编译运行之后得到预期的值。函数 math 就是一个高阶函数,注意其在调用的时候传入的只是函数名。
实现这一切的基础在于Rust支持类似C/C++语言中的函数指针。函数指针,顾名思义,是指向函数的指针,其值为函数的地址,如代码清单6-14所示。
代码清单6-14:函数指针
fn hello() {
println!("hello function pointer");
}
fn main() {
let fn_str: fn() = hello;
println!("{:p}", fn_ptr); // 0x562bacfb9f80
let other_fn = hello;
// println!("{:p}", other_fn); // 非函数指针
hello();
other_fn();
fn_ptr();
(fn_ptr)();
}代码清单6-14的第5行声明了一个函数指针。这里需要注意的地方是,let声明必须显式指定函数指针类型fn(),以及赋值使用的是函数名hello而非带括号的函数调用。第6行通过打印fn_ptr的指针地址,证明
其为一个函数指针。
代码第7行的let声明并没有指定函数指针类型,如果取消第8行的注释,那么编译此代码时,打印other_fn指针地址会报如下错误:
error[E0277]: the trait bound `fn() {hello}: std::fmt::Pointer` is not satisfied
8 | println!("{:p}", other_fn);
| ^^^^^^^^ the trait `std::fmt::Pointer` is not implemented for `fn() {hello}`根据此错误信息可以了解到,other_fn的类型实际上是fn(){hello},这其实是函数hello本身的类型,而非函数指针类型,所以 other_fn不是函数指针类型。虽然如此,并不会影响第10行的函数调用。
回到代码清单6-13中,函数math的参数op的类型指定为fn(i32,i32)->i32,就是函数指针类型。当main函数中调用math函数时,传入sum和product函数名之后,会自动通过模式匹配转换为函数指针类型。
对于函数指针类型,可以使用type关键字为其定义别名,便于提升代码可读性,如代码清单6-15所示。
代码清单6-15:使用type关键字定义函数指针类型别名
type MathOp = fn(i32, i32) -> i32;
fn math(op: MathOp, a: i32, b: i32) -> i32 {
println!("{:p}", op);
op(a, b)
}当然,也可以将函数作为返回值,如代码清单6-16所示。
代码清单6-16:将函数作为返回值
type MathOp = fn(i32, i32) -> i32;
fn math(op: &str) -> MathOp {
fn sum(a: i32, b: i32) -> i32 {
a + b
}
fn product(a: i32, b: i32) -> i32 {
a * b
}
match op {
"sum" => sum,
"product" => product,
_=> {
println!(
"Warning: Not Implemented {:?} oprator, Replace with sum",
op
);
sum
}
}
}
fn main() {
let (a, b) = (2, 3);
let sum = math("sum");
let product = math("product");
let div = math("div");
assert_eq!(sum(a, b), 5);
assert_eq!(product(a, b), 6);
assert_eq!(div(a, b), 5);
}代码清单6-16中实现的math函数,接收一个字符串作为参数,函数中使用match进行匹配,如果字符串为sum,则返回sum函数;如果字符串是product,则返回product函数。注意在match匹配中,sum和product函数均只是函数指针(函数名)。该代码可以正确编译执行,注意代码第25行,因为没有实现div函数,所以代码会打印指定的warning提示,并使用sum函数替代div函数。
假设现在想把 math 函数修改一下,让其作为返回值的函数直接和参与计算的值进行绑定,如代码清单6-17所示。
代码清单6-17:将返回的函数和参与计算的参数直接绑定
fn sum(a: i32, b: i32) -> i32 {
a + b
}
fn product(a: i32, b: i32) -> i32 {
a * b
}
type MathOp = fn(i32, i32) -> i32
fn math(op: &str, a: i32, b: i32) -> MathOp {
match op {
"sum" => sum(a, b),
_ => product(a, b)
}
}
fn main() {
let (a, b) = (2, 3);
let sum = math("sum", a, b);
}代码清单6-17编译会报类型不匹配的错误。因为在math函数调用的时候,match匹配中的sum(a,b)和product(a,b)会同时进行求值,得到的是i32类型,而不是MathOp类型。所以,要想返回函数,还必须使用函数指针。
再来看另外一个将函数作为返回值的示例,如代码清单6-18所示。
代码清单6-18:返回默认加1的计数函数
fn counter() -> fn(i32) -> i32 {
fn inc(n: i32) -> i32 {
n + 1
}
inc
}
fn main() {
let f = counter();
assert_eq!(2, f(1));
}代码清单6-18中定义了默认加1的计数函数,现在我们把其改为可以直接指定增长值的函数,如代码清单6-19所示。
代码清单6-19:让counter函数可以直接指定增长值i
fn counter() -> fn(i32) -> i32 {
fn inc(n: i32) -> i32 {
n + i
}
inc
}
fn main() {
let f = counter(2);
assert_eq!(3, f(1));
}
// 编译会报以下错误:
error[E0434]: can't capture dynamic enviroment in a fn item; use the || {...} closure form instead
3 | n + i
| ^Rust不允许fn定义的函数inc捕捉动态环境(函数counter)中的变量绑定i,因为变量绑定i会随着栈帧的释放而释放。如果一定要这么做,需要使用闭包来代替。
6.2 闭包
闭包(Closure)通常是指词法闭包,是一个持有外部环境变量的函数。外部环境是指闭包定义时所在的词法作用域。外部环境变量,在函数式编程范式中也被称为自由变量,是指并不是在闭包内定义的变量。将自由变量和自身绑定的函数就是闭包。
回到代码清单6-19中,如果想在返回的函数中继续使用变量 i,则 需要用到闭包,如代码清单6-20所示。
代码清单6-20:返回闭包
fn counter(i: i32) -> Box<dyn Fn(i32) -> i32> {
Box::new(move |n: i32| n + i)
}
fn main() {
let f = counter(3);
assert_eq!(4, f(1));
}在代码清单6-20中,counter函数返回的是一个闭包,放到了Box<T>中,因为闭包的大小在编译期是未知的。在Rust 2018版本中,返回的闭包也可以使用impl Trait语法写成impl Fn(i32)->i32,这样就不需要使用Box<T>了。
在代码第2行的闭包 |n:i32 | n + i 中,i为自由变量,因为闭包自身的参数只有n。第5章介绍过闭包捕获自由变量的三种方式,因为此时 i 为 复制语义类型,所以它肯定会按引用被捕获。此引用会妨碍闭包作为函数返回值,编译器会报错。所以这里使用 move 关键字来把自由变量 i 的所有权转移到闭包中,当然,因为变量 i 是复制语义,所以这里只会进行按位复制。
注意这里闭包的类型为 Fn(i32)-> i32,以大写字母 F 开头的 Fn 并不是函数指针类型fn(i32)->i32,它是一个trait,本章后面的章节有更详细的介绍。
在main函数中,第5行变量f绑定了counter(3)函数调用返回的闭包。该闭包持有counter函数传入的参数值3,在第6行调用f(1)时参与了计算,得到最终的结果4。
通过此例看得出来,闭包包含以下两种特性:
延迟执行。返回的闭包只有在需要调用的时候才会执行。
捕获环境变量。闭包会获取其定义时所在作用域中的自由变量, 以供之后调用时使用。
现在我们对闭包有了大致的了解,接下来将系统地学习Rust中闭包的具体概念和实现。
6.2.1 闭包的基本语法
Rust的闭包语法形式参考了Ruby语言的lambda表达式,如代码清单 6-21所示。
代码清单6-21:闭包基本语法示例
fn main() {
let add = |a: i32, b: i32| -> i32 {a + b};
assert_eq!(add(1, 2), 3);
}- 闭包由管道符(两个对称的竖线)和花括号(或圆括号)组合而成。管道符里是闭包函数的参数,可以像普通函数参数那样在冒号后面 添加类型标注,也可以省略为以下形式:
let add = |a, b| -> i32{a + b};- 花括号里包含的是闭包函数执行体,花括号和返回值也可以省略:
let add = |a, b| a + b;- 当闭包函数没有参数只有捕获的自由变量时,管道符里的参数也可以省略:
let (a, b) = (1, 2);
let add = || a + b;- 闭包的参数可以是任意类型的,如代码清单6-22所示。
代码清单6-22:闭包参数可以为任意类型
fn val() -> i32 {5}
fn main() {
let add = |a: fn() -> i32, (b, c)| (a)() + b + c;
let r = add(val, (2, 3));
assert_eq!(r, 10);
}代码清单6-22的第3行定义的闭包有两个参数,第一个是函数指针类型,第二个是元组类型。虽然元组类型中的参数没有显式地标注类型,但是Rust编译器会通过函数指针类型的信息来推断其为i32类型,所以代码可以正常编译运行。
需要注意的是,两个定义一模一样的闭包也并不一定属于同一种类型,如代码清单6-23所示。
代码清单6-23:两个相同定义的闭包却不属于同一种类型
fn main() {
let c1 = || {};
let c2 = || {};
let v = [c1, c2];
}代码清单6-23声明了两个形式一样的闭包,将它们保存到一个数组中。因为数组只能保存相同类型的元素,所以编译会报如下错误:
error[E0308]: mismatched types
5 | let v = [c1, c2];
| ^^ expected closure, found a different closure这表示两个相同定义的闭包完全不属于同一种类型。
6.2.2 闭包的实现
假如现在想显式地指定闭包的类型,该如何操作?可以通过代码清单6-24所示的方法来查看一个闭包的类型。
代码清单6-24:查看闭包类型
fn main() {
let c1: () = || {println!("i'm a closure")};
}代码清单6-24编译会报如下错误:
error[E0308]: mismatched types
3 | let c1: () = || {println!("i'm a closure")};
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ expected (), found closure
= note: expected type `()` found type `[closure@src/main.rs:3:19 3:49]`错误信息提示,期望得到的类型是单元类型,但是实际得到的类型是[closure@src/main.rs:3:19:3:49]。这个闭包类型与 Rust 类型系统提供的常规类型不同,它是一个由编译器制造的临时存在的闭包实例类型。
其实在Rust中,闭包是一种语法糖。也就是说,闭包不属于Rust语言提供的基本语法要素,而是在基本语法功能之上又提供的一层方便开发者编程的语法。闭包和普通函数的差别就是闭包可以捕获环境中的自由变量。如果用现在已经学过的知识来实现一个自己的闭包,该如何做?
能想到的第一个办法是使用指针。如图6-1所示,闭包||{a+b}的实现可以通过函数指针和捕获变量指针组合来实现。指针放栈上,捕获变量放到堆上。实际上,早期的Rust版本实现闭包就采用了类似的方式,因 为要把闭包捕获变量放到堆上,所以称其为装箱(Boxed)闭包。这种方式带来的问题就是影响性能。Rust是基于LLVM的语言,这种闭包实现方式使得LLVM难以对其进行内联和优化。
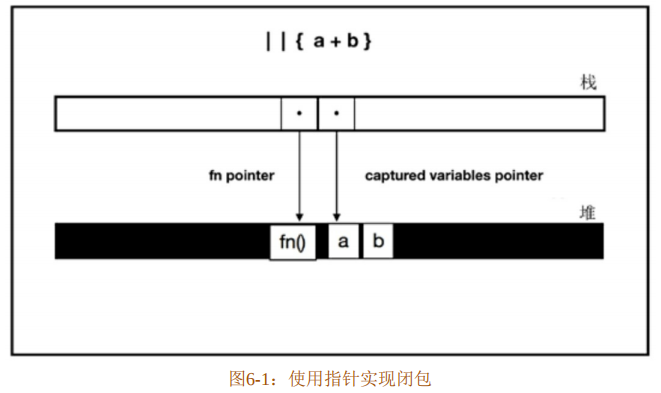
所以,Rust团队又对闭包的实现做了重大改进,也就是当前版本中的闭包实现方式。改进方案称为非装箱(Unboxed)闭包,此方案是Rust语言一致性的再一次体现。
非装箱闭包方案有三个目标:
- 可以让用户更好地控制优化。
- 支持闭包按值和按引用绑定环境变量。
- 支持三种不同的闭包访问,对应self、&self和&mut self三种方法。
实现这三个目标的核心思想是,通过增加trait将函数调用变为可重载的操作符。比如,将a(b,c,d)这种函数调用变为如下形式:
Fn::call(&a, (b, c, d))
FnMut::call_mut(&mut a, (b, c, d))
FnOnce::call_once(a, (b, c, d))Rust增加的这三个trait分别就是Fn、FnMut和FnOnce。它们在Rust源码中的定义如代码清单6-25所示。
代码清单6-25:Fn、FnMu、FnOnce在源码中的定义示例
#[lang = "fn_once"]
#[rustc_paren_sugar]
#[fundamental]
pub trait FnOnce<Args> {
type Output;
extern "rust-call" fn call_once(self, args: Args) -> Self::Output;
}
#[lang = "fn_mut"]
#[rustc_paren_sugar]
#[fundamental]
pub trait FnMut<Args>: FnOnce<Args> {
extern "rust-call" fn call_mut(&mut self, args: Args) -> Self::Output;
}
#[lang = "fn"]
#[rustc_paren_sugar]
#[fundamental]
pub trait Fn<Args>: FnMut<Args> {
extern "rust-call" fn call(&self, args: Args) -> Self::Output;
}从代码清单6-25中看得出来,这三个trait都标记了三个相同的属性。
第一个属性是#[lang="fn/fn_mut/fn_once"],表示其属于语言项(Lang Item),分别以fn、fn_mut、fn_once名称来查找这三个trait。
第二个属性是#[rustc_paren_sugar],表示这三个trait是对括号调用语法的特殊处理,在编译器内部进行类型检查的时候,仅会将最外层为圆括号的情况识别为方法调用。在类型签名或方法签名中有时候有尖括号,比如<F:Fn(u8,u8)->u8>,而此时尖括号里面的括号就不会被识别为方法调用。
第三个属性为#[fundamental],在第3章介绍过,这是为了支持trait一致性而增加的属性,加上此属性则被允许为Box<T>实现指定的trait,在此例中是这三个Fn系列的trait。
函数调用为什么要分成三个trait?这和所有权系统有关。
- FnOnce调用参数为self,这意味着它会转移方法接收者的所有权。换句话说,就是这种方法调用只能被调用一次。
- FnMut调用参数为&mut self,这意味着它会对方法接收者进行可 变借用。
- Fn调用参数为&self,这意味着它会对方法接收者进行不可变借用,也就是说,这种方法调用可以被调用多次。
现在函数调用被抽象成为了三个 trait,实现闭包就简单了,只需要用结构体代替闭包表达式,然后按具体的需求为此结构体实现对应的 trait即可。这样的话,每个闭包表达式实际上就是该闭包结构体的具体实例,该结构体内部成员可以存储闭包捕获的变量,然后在调用的时候使用即可,如代码清单6-26所示。
代码清单6-26:模拟编译器对闭包的实现
#![feature(unboxed_closures, fn_traits)]
struct Closure {
env_var: u32,
}
impl FnOnce<()> for Closure {
type Output = u32;
extern "rust-call" fn call_once(self, args: ()) -> u32 {
println!("call it FnOnce()");
self.env_var + 2
}
}
impl FnMut<()> for Closure {
extern "rust-call" fn call_mut(&mut self, args: ()) -> u32 {
println!("call it FnMut()");
self.env_var + 2
}
}
impl Fn<()> for Closure {
extern "rust-call" fn call(&self, args: ()) -> u32 {
println!("call it Fn()");
self.env_var + 2
}
}
fn call_it<F: Fn() -> u32>(f: &F) -> u32 {
f()
}
fn call_it_mut<F: FnMut() -> u32>(f: &mut F) -> u32 {
f()
}
fn call_it_once<F: FnOnce() -> u32>(f: F) -> u32 {
f()
}
fn main() {
let env_var = 1;
let mut c = Closure {env_var: env_var};
c();
c.call(());
c.call_mut(());
c.call_once(());
let mut c = Closure {env_var: env_var};
{
assert_eq!(3, call_it(&c));
}
{
assert_eq!(3, call_it_mut(&mut c));
}
{
assert_eq!(3, call_it_once(c));
}
}代码清单6-26的第1行使用了feature特性#! [feature(unboxed_closures,fn_traits)],注意此特性只能应用于Nightly版本下。
第2行定义了结构体Closure,有一个成员字段代表从环境中捕获的自由变量。然后分别为其实现了FnOnce、FnMut、Fn这三个trait。
第24行到第32行定义了call_it、call_it_mut、call_it_once三个泛型函数,它们分别使用FnOnce、FnMut、Fn这三个trait来做泛型参数的限定,用来测试Closure结构体实例调用。在main函数中,第35行定义了Closure结构体实例,将环境变量env_var保存在其成员字段中。因为该结构体实现了指定的trait,所以在第36行其实例c可以像函数那样被调用。
最终的执行结果如代码清单6-27所示。
代码清单6-27:自定义闭包实现的输出结果
call it Fn()
call it Fn()
call it FnMut()
call it FnOnce()
call it Fn()
call it FnMut()
call it FnOnce()代码清单6-27第1行是代码清单6-26中第36行的输出结果。它说明,默认的函数调用c()是Fn trait中实现的call方法。此处结构体实例可以像函数那样被调用,这看起来像“魔法”,实际上是由下面的代码实现的。
extern "rust-call" fn call(&self, args: ()) -> u32此处extern关键字用于fn前面,表示使用指定的ABI(Application Binary Interface,程序二进制接口),此处代表指定使用Rust语言的rust-call ABI,它的作用是将函数参数中的元组类型做动态扩展,以便支持可变长参数。因为在 Fn、FnMut、FnOnce 这三个 trait 里的方法要接收闭包的参数,而编译器本身并不可能知道开发者给闭包设定的参数个数,所以这里只能传元组,然后由rust-call ABI在底层做动态扩展。
但是需要注意的是,如果想使用 rust-call ABI,必须像代码清单 6-26 第 1 行那样声明unboxed_closures特性。 代码清单6-26第37行至第39行分别显式地调用了相应的call、call_mut、call_once方法,但是注意必须显式地指定一个单元值为参数,这里为了演示,指定了args参数为单元类型。分别输出代码清单6-27的第2行至第4行的结果。
代码清单6-26的第40行重新声明了Closure结构体实例,这是因为在第39行call_once调用之后,之前的实例c的所有权被转移,无法再次被 使用。要注意call_once方法中的参数是self。代码清单6-26的第41行到第49行使用了call_it、call_it_mut、call_it_once函数来测试相应的trait限定,对应的trait限定如下。
F: Fn() -> u32
F: FnMut() -> u32
F: FnOnce() -> u32输出的结果为代码清单6-27的第5行至第7行,和预期相符。
代码清单6-26等价于下面的闭包代码,如代码清单6-28所示。
代码清单6-28:与代码清单6-26等价的闭包示例
fn main() {
let env_var = 1;
let c = || env_var + 2;
assert_eq!(3, c());
}代码清单 6-28 中定义的闭包 c 相当于代码清单 6-26 中已经实现了相应 trait 的结构体Closure的实例c。
代码清单6-26模拟的闭包实现并不等同于Rust编译器源码中真正的闭包实现。这里只是做一个思路的演示。
现在我们知道了闭包是基于trait的语法糖,那么就可以通过使用trait对象来显式地指定其类型,如代码清单6-29所示。
代码清单6-29:显式指定闭包类型
fn main() {
let env_var = 1;
let c: Box<Fn() -> i32> = Box::new(||{env_var + 2});
assert_eq!(3, c());
}代码清单6-29的第3行显式地指定了闭包的类型为Box<Fn()-> i32>,该类型为trait对象,此处必须使用trait对象。
6.2.3 闭包与所有权
闭包表达式会由编译器自动翻译为结构体实例,并为其实现Fn、FnMut、FnOnce三个trait中的一个。但是对于开发者来说,如何才能知道某个闭包表达式由编译器默认实现了哪种trait呢?
前面提到过,这三个trait和所有权有关系。更准确地说,这三个trait的作用如下。
- Fn,表示闭包以不可变借用的方式来捕获环境中的自由变量,同时也表示该闭包没有改变环境的能力,并且可以多次调用。对应&self。
- FnMut,表示闭包以可变借用的方式来捕获环境中的自由变量,同时意味着该闭包有改变环境的能力,也可以多次调用。对应&mut self。
- FnOnce,表示闭包通过转移所有权来捕获环境中的自由变量,同时意味着该闭包没有改变环境的能力,只能调用一次,因为该闭包会消耗自身。对应self。
第5章讲所有权系统时,对不同环境变量类型介绍过闭包捕获其环境变量的方式:
- 对于复制语义类型,以不可变引用(&T)来进行捕获。
- 对于移动语义类型,执行移动语义,转移所有权来进行捕获。
- 对于可变绑定,并且在闭包中包含对其进行修改的操作,则以可变引用(&mut T)来进行捕获。
也就是说,闭包会根据环境变量的类型来决定实现哪种trait。这三个trait的关系如图6-2所示。
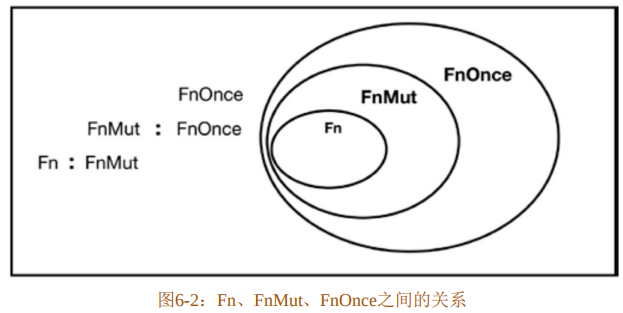
图6-2展示了Fn、FnMut、FnOnce三个trait之间的关系。FnMut继承了FnOnce,Fn又继承了FnMut。这意味着,如果要实现Fn,就必须实现FnMut和FnOnce;如果要实现FnMut,就必须实现FnOnce;如果只需要实现FnOnce,就不需要实现FnMut和Fn。
复制语义类型自动实现Fn 相关代码如代码清单6-30所示。
代码清单6-30:复制语义类型自动实现Fn
fn main() {
let s = "hello";
let c = ||{println!("{:?}", s)};
c();
c();
println!("{:?}", s);
}在代码清单6-30中,声明了变量绑定s为字符串字面量,其为复制语义类型。闭包c会按照不可变引用来捕获s。第4行和第5行代码两次调用闭包c,第6行的println!打印s,均可以正常编译运行,因此就可以做出这样的推理:闭包c可以两次调用,说明编译器自动为闭包表达式实现的结构体实例并未失去所有权。第6行的println!语句会对s进行一次不可变借用,这就证明第3行闭包对s进行了不可变借用,只有不可变借用才可以借用多次。
综上所述,闭包c默认自动实现了Fn这个trait,并且该闭包以不可变借用捕获环境中的自由变量。
要实现Fn就必须实现FnMut和FnOnce,所以,代码清单6-30中的闭包如果被编译器翻译为匿名结构体和trait,那么Fn、FnMut、FnOnce都 会被实现,如代码清单6-31所示。
代码清单6-31:代码清单6-30中的闭包被翻译为匿名结构体和trait的情况
#![feature(unboxed_closures, fn_traits)]
struct Closure<'a> {
env_var: &'a u32
}
impl<'a> FnOnce<()> for Closure<'a> {
type Output = ();
extern "rust-call" fn call_once(self, args: ()) -> () {
println!("{:?}", self.env_var);
}
}
impl<'a> FnMut<()> for Closure<'a> {
extern "rust-call" fn call_mut(&mut self, args: ()) -> () {
println!("{:?}", self.env_var);
}
}
impl<'a> Fn<()> for Closure<'a> {
extern "rust-call" fn call(&self, args: ()) -> () {
println!("{:?}", self.env_var);
}
}
fn main() {
let env_var = 42;
let mut c = Closure(env_var: &env_var);
c(); // 42
c.call_mut(()); // 42
c.call_once(()); // 42
}在代码清单6-31中,闭包被翻译为结构体Closure<'a >,因为环境变量是按不可变借用进行捕获的,所以其成员字段是引用类型,注意这里需要明确指定生命周期参数。在 main函数的第24行,闭包结构体实例c的调用操作默认是执行Fn实现中的call方法。因为这里要实现Fn,必须同时实现 FnMut 和 FnOnce,所以第 25 行和第 26 行可以显式地直接调用call_mut和call_once方法。因此,在代码清单6-30的闭包调用中也可以显式地调用call_mut和call_once方法,如代码清单6-32所示。
代码清单6-32:实现了Fn的闭包也可以显式调用call_mut和call_once方法
#![feature(fn_tarits)]
fn main() {
let s = "hello";
let mut c = ||{println!("{:?}", s)};
c(); // "hello"
c(); // "hello"
c.call_mut(); // "hello"
c.call_once(); // "hello"
c; // "hello"
println!("{:?}", s); // "hello"
}代码清单6-32的第1行使用了#![feature(fn_traits)]特性,是为了显式调用trait实现中的call、call_mut、call_once方法,如果是默认的闭包调用,并不需要此特性(比如代码清单6-30)。
代码第4行使用了mut关键字改变了闭包的可变性,这是为了调用call_mut方法,此方法需要可变闭包。
代码第5行默认的闭包调用是Fn实现的call方法。第6行依然可以再次调用闭包c。
代码第7行显式地调用了call_mut方法,正常输出结果。
代码第8行显式地调用了call_once方法,正常输出结果。此时闭包c捕获的变量s默认实现了Copy,因此默认实现的FnOnce也会自动实现Copy。此处调用call_once方法并不会导致闭包c的所有权被转移。第9行再次调用闭包c,正常输出。但是如果闭包c的捕获变量是移动语义,那么调用call_once就会转移所有权。
第10行正常打印变量绑定s,证明闭包c并没有被后面的call_mut和 call_once调用所影响,闭包依旧是按不可变借用捕获的。这也证明闭包被编译器翻译为的结构体是一种固定的结构体。
移动语义类型自动实现FnOnce,相关代码如代码清单6-33所示。
代码清单6-33:移动语义类型自动实现FnOnce
fn main() {
let s = "hello".to_string();
let c = || s;
c();
// c(); // error: use of moved value: `c`
//println!("{:?}", s); // error: use of moved value: `c`
}在代码清单6-33中,变量绑定s为String,是典型的移动语义类型。第5行第二次调用闭包c的时候,编译出错,提示c已经被转移了所有权,因而无法使用。而第6行在第4行闭包c调用之后,也会编译出错,提示s已经被转移了所有权而无法使用。综上所述,可以做出这样的推理:闭包c在第一次调用时转移了其所有权,导致第二次调用失效,证明其实现的闭包结构体实例所实现的trait方法参数必然是self。足以证明该闭包实现的是FnOnce。第6行的s因为失去所有权而失效,也足以证明闭包c夺走了s的所有权。
既然闭包的默认调用是FnOnce,这也说明,编译器翻译的闭包结构体中记录捕获变量的成员字段不是引用类型,并且只实现 FnOnce,所以,肯定无法显式地调用 call 或 call_mut方法,如代码清单6-34所示。
代码清单6-34:闭包只实现了FnOnce,所以无法显式地调用call和call_mut方法
#![feature(fn_traits)]
fn main() {
let mut s = "hello".to_string();
let c = || s;
c();
// error: expected a closure that implements the `FnMut` trait, but this
// closure only implements `FnOnce`
// c.call(());
// error: expected a closure that implements the `FnMut` trait, but this
// closure only implements `FnOnce`
// c.call_mut(());
// c.(); // error: use of moved value: `c`
// println!("{:?}", s); // error: use of moved value: `c`
}代码清单6-34的第3行声明闭包时使用了mut关键字来设置闭包的可变性,同样是为了显式调用call_mut。
闭包c默认实现了FnOnce,所以代码第8行和第11行分别显式地调用call和call_mut方法时,编译器都报错了,并且提示闭包只实现了FnOnce。
注意代码中已被注释掉的第12行,再次调用闭包c将报所有权转移的错误。这是因为闭包c的捕获变量是String类型,它是移动语义,所以在上面第一次调用闭包c之后,它的所有权已被转移。
使用move关键字自动实现Fn
Rust 针对闭包提供了一个关键字 move,使用此关键字的作用是强制让闭包所定义环境中的自由变量转移到闭包中,如代码清单6-35所示。
代码清单6-35:环境变量为复制语义类型时使用move关键字
fn main() {
let s = "hello";
let c = move || {println!("{:?}", s)};
c();
c();
println!("{:?}", s);
}代码清单6-35中的变量绑定s为复制语义类型,虽然move关键字强制执行,但闭包捕获的s执行的对象是复制语义后获取的新变量。原始的s并未失去所有权。所以整个代码可以正常通过编译。由此,可以做出这样的推理:闭包c可以连续两次被调用,说明编译器自动生成的闭包结构体实例并未失去所有权,所以肯定是&self和&mut self中的一种。又因为闭包c本身是不可变的,所以只存在&self。因为要进行不可变借用,所以必须使用mut关键字将c本身修改为可变。因此,该闭包实现的一定是Fn。
代码清单6-36展示的是环境变量为移动语义类型的情况。
代码清单6-36:环境变量为移动语义类型时使用move关键字
fn main() {
let s = "hello".to_string();
let c = move ||{println!("{:?}", s)};
c();
c();
// println!("{:?}", s); // error: use of moved value: `s`
}代码清单6-36中的变量绑定s为移动语义类型String。在使用move关键字强制转移所有权之后,变量s已经无法再次被使用了,所以第6行会出错。而闭包c依然是默认不可变的,并且可以进行多次调用。同理,该闭包实现的一定是Fn。那么,move关键字是否只影响捕获自由变量的所有权的转移情况,而不影响闭包本身呢?我们来看一下代码清单6-37。
代码清单6-37:move关键字是否影响闭包本身
fn call<F: FnOnce()>(f: F) {f()}
fn main() {
// 未使用move
let mut x = 0;
let incr_x = || x += 1;
call(incr_x);
// call(incr_x); // ERROR: `incr_x` moved in the call above.
// 使用move
let mut x = 0;
let incr_x = move || x += 1;
call(incr_x);
call(incr_x);
// 对移动语义类型使用move
let mut x = vec![];
let expend_x = move || x.push(42);
call(expend_x);
// call(expend_x); // ERROR: use of moved value; `expend_x`
}代码清单6-37定义了call函数,以FnOnce()闭包作为参数,在函数体内执行闭包,该函数主要用于判断闭包自身的所有权是否转移。
代码第4行到第7行定义了闭包incr_x,并未使用move关键字,其捕获变量x为复制语义。将此闭包作为参数传给call函数调用两次,在第二次调用的时候会报错,提示incr_x所有权已经被转移。
代码第9行到第12行再次定义了闭包incr_x,但是这次使用了move关键字。将其作为参数传给call函数调用两次,均可正常编译执行。
代码第14行到第17行定义了闭包expend_x,使用了move关键字,其捕获变量x现在为移动语义类型。将其作为参数传给call函数调用两次,第二次调用报错,提示expend_x的所有权已经被转移。
通过代码清单6-37看得出来,闭包在使用move关键字的时候,如果捕获变量是复制语义类型的,则闭包会自动实现Copy/Clone;如果捕获变量是移动语义类型的,则闭包不会自动实现Copy/Clone,这也是出于保证内存安全的考虑。
修改环境变量以自动实现FnMut,很多时候需要通过修改环境变量的闭包来自动实现FnMut,如代码清单6-38所示。
代码清单6-38:修改环境变量的闭包来自动实现FnMut
fn main() {
let mut s = "rust".to_string();
{
let mut c = ||{s += " rust"};
c();
c();
// error: cannot borrow `s` as immutable
// because it is also borrowed as mutable
// println!("{:?}", s);
}
println!("{:?}", s);
}代码清单6-36中的变量绑定s使用mut关键字修改了其可变性,成为了可变绑定。变量s通过第4行的闭包c进行了自我修改,所以闭包c在声明时也使用了mut关键字。如果想修改环境变量,必须实现FnMut。由编译器生成的闭包结构体实例在调用fn_mut方法时,需要&mut self。
闭包c同样可以调用两次。但是如果在和闭包c同样的作用域中使用s的不可变借用,编译器就会报错,因为s已经被闭包c按可变借用进行了捕获。所以在第9行的println!语句中使用s就会报错。但是在第11行,s依旧可以作为不可变借用,因为之前s的可变借用在离开第10行作用域之后就已经归还了所有权。
实现了FnMut的闭包,必然会实现FnOnce,但不会实现Fn,如代码清单6-39所示。
代码清单6-39:实现了FnMut的闭包的情况
#![feature(fn_tarits)]
fn main() {
let mut s = "rust".to_string();
{
let mut c = || s += " rust";
c();
// error: expencted a closure that implements the `Fn` trait,
// but this closure only implements `FnMut`
// c.call(());
c.call_once(());
// error: cannot borrow `s` as immutable
// because it is also borrowed as mutable
// println!("{:?}", s);
}
println!("{:?}", s); // "rust rust rust"
}在代码清单6-39中,第9行显式地调用call方法时,编译器会报错,并提示该闭包只实现了FnMut。而第10行则可以显式地调用call_once方法。
未捕获任何环境变量的闭包会自动实现Fn
没有捕获任何自由变量的闭包,会自动实现Fn,如代码清单6-40所示。
代码清单6-40:没有捕获任何环境变量的闭包自动实现Fn
fn main() {
let c = ||{println!("hhh")};
c();
c();
}代码清单6-40定义的闭包c没有捕获任何环境变量,并且也没有使用mut关键字改变其可变性,然而可以被多次调用。这足以证明编译器为其自动实现的结构体实例并未失去所有权,只可能是&self。所以,该闭包一定实现了Fn。规则总结
综合上面的几种情况,可以得出如下规则:
- 如果闭包中没有捕获任何环境变量,则默认自动实现Fn。
- 如果闭包中捕获了复制语义类型的环境变量,则:
- ➢ 如果不需要修改环境变量,无论是否使用move关键字,均会自动实现Fn。
- ➢ 如果需要修改环境变量,则自动实现FnMut。
- 如果闭包中捕获了移动语义类型的环境变量,则:
- ➢ 如果不需要修改环境变量,且没有使用move关键字,则自动实现FnOnce。
- ➢ 如果不需要修改环境变量,且使用了move关键字,则自动实现Fn。
- ➢ 如果需要修改环境变量,则自动实现FnMut。
- 使用 move 关键字,如果捕获的变量是复制语义类型的,则闭包会自动实现Copy/Clone,否则不会自动实现Copy/Clone。
在日常的开发中,基本可以根据上面的规则对闭包会实现哪个trait做出正确的判断。
6.2.4 闭包作为函数参数和返回值
闭包存在于很多语言中,尤其是动态语言,诸如JavaScript、Python和Ruby之类,闭包的使用范围非常广泛。但是在这些动态语言中,闭包捕获的环境变量基本都是对象(此处指面向对象编程语言中的对象,属于引用类型),使用不当容易造成内存泄漏。并且在这些语言中,闭包是在堆中分配的,运行时动态分发,由GC来回收内存,调用和回收闭包都会消耗多余的CPU时间,更不用说使用内联技术来优化这些闭包了。而Rust使用trait和匿名结构体提供的闭包机制是非常强大的。Rust的闭包实现受到了现代C++的启发,将捕获的变量放到结构体中,这样的好处就是不会占用堆内存,拥有更高的性能,可以使用内联技术来消除函数调用开销并实现其他关键的优化,比如对编译器自动实现的闭包结构体进行优化等。从而允许在任何环境(包括裸机)中使用闭包。
Rust的闭包实现机制使得每个闭包表达式都是一个独立的类型,这样可能有一些不便,比如无法将不同的闭包保存到一个数组中,但是可以通过把闭包当作trait对象来解决这个问题,如代码清单6-41所示。
代码清单6-41:把闭包作为trait对象
fn boxed_closure(c: &mut Vec<Box<Fn()>>) {
let s = "second";
c.push(Box::new(|| println!("first")));
c.push(Box::new(move|| println!("{}", s)));
c.push(Box::new(|| println!("third")));
}
fn main() {
let mut c: Vec<Box<Fn()>> = vec![];
boxed_closure(&mut c);
for f in c {
f(); // first / second / third
}
}代码清单6-41第8行声明了一个可变闭包,指定类型为Vec<Box<Fn()>>,这表示该动态数组中存储的元素类型为Box<Fn()>类型。Box<Fn()>是一个trait对象,把闭包放到Box<T>中就可以构建一个闭包的trait对象,然后就可以当作类型来使用。通过第3章的学习可以知道,trait对象是动态分发的,在运行时通过查找虚表(vtable)来确定调用哪个闭包。这里需要注意的是,第 4 行代码中的闭包默认以不可变借用方式捕获了环境变量s,但是这里需要将闭包装箱,稍后在iter_call函数中调用,所以这里必须使用move关键字将s的所有权转移到闭包中,因为变量s是复制语义类型,所以该闭包捕获的是原始变量s的副本。
像这种在函数boxed_closure调用之后才会使用的闭包,叫作逃逸闭包(escape closure)。因为该闭包捕获的环境变量“逃离”了boxed_closure函数的栈帧,所以在函数栈帧销毁之后依然可用。与之相对应,如果是跟随函数一起调用的闭包,则是非逃逸闭包(non-escape closure)。
(1) 闭包作为函数参数
闭包可以作为函数参数,这一点直接提升了Rust语言的抽象表达能力,令其有了完全不弱于Ruby、Python这类动态语言的抽象表达能力。下面比较了Rust和Ruby两种语言中的any方法,该方法用于按指定条件确认数组中的元素是否存在。
Rust语言:
v.any(|&x| x == 3);Ruby语言:
v.any?{i| i == 3}看得出来,Rust语言和Ruby语言中对闭包的用法基本相似。
因为闭包属于trait语法糖,所以当它被当作参数传递时,它可以被用作泛型的trait限定,也可以直接作为trait对象来使用。代码清单6-42首先以trait限定的方式实现了一个any方法。
代码清单6-42:以trait限定的方式实现any方法
use std::ops::Fn;
trait Any {
fn any<F>(&self, f: F) -> bool where
Self: Sized,
F: Fn(u32) -> bool;
}
impl Any for Vec<u32> {
fn any<F>(&self, f: F) -> bool where
Self: Sized,
F: Fn(u32) -> bool
{
for &x in self {
if f(x) {
return true;
}
}
false
}
}
fn main() {
let v = vec![1, 2, 3];
let b = v.any(|x| x == 3);
println!("{:?}", b);
}在代码清单6-42中,第1行的use语句是可有可无的,因为Fn并不受trait孤儿规则的限制。从第 2 行开始定义了一个 trait,将其命名为 Any。需要注意的是,此处自定义的Any不同于标准库提供的Any。该trait中声明了泛型函数any,该函数泛型F的trait限定为Fn(u32)->bool,这种形式更像函数指针类型,有别于一般的泛型限定<F:Fn< u32,bool>>。其实函数指针也是默认实现了Fn、FnMut、FnOnce这三个triat的,比如代码清单6-43就展示了函数指针作为闭包参数的情况。
代码清单6-43:函数指针也可以作为闭包参数
fn call<F>(closure: F) -> i32
where F: Fn(i32) -> i32
{
closure(1)
}
fn counter(i: i32) -> i32 {i + 1}
fn main() {
let result = call(counter);
assert_eq!(2, result);
}在代码清单6-43第8行中,函数指针当作闭包参数传入了call函数,代码正常编译运行。这是因为此函数指针counter也实现了Fn。
回到代码清单6-42,第3行的where从句对Self做了Sized限定,这意味着,当Any被作为trait对象使用时,该方法不能被动态调用,这属于一种优化策略。
代码清单6-42的第7行使用impl关键字为Vec<u32>类型实现了any方法。该方法会迭代传入的闭包,依次调用,如果满足闭包表达式中指定的条件,则返回true,否则返回false。
在main函数中,则可以使用形如代码清单6-42第22行那样的形式来调用any方法,以查找动态数组v中是否存在满足条件的元素。像这样通过将闭包作为参数,可以把一段动态的逻辑按需传入指定方法中进行计算,这极大地提高了程序的灵活性和抽象能力。最重要的是,在Rust中使用闭包,完全不需要担心性能问题。
除了上述静态分发的形式,也可以将闭包作为trait对象动态分发,如代码清单6-44所示。代码清单6-44:将闭包作为trait对象进行动态分发
trait Any {
fn any(&self, f: &(Fn(u32) -> bool)) -> bool;
}
impl Any for Vec<u32> {
fn any(&self, f: &(Fn(u32) -> bool)) -> bool {
for &x in self.iter() {
if f(x) {
return true;
}
}
false
}
}
fn main() {
let v = vec![1, 2, 3];
let b = v.any(&|x| x == 3);
println!("{:?}", b);
}代码清单6-44将闭包作为了trait对象,这样代码更加简练。动态分发比静态分发的性能低一些,但还是完全可以和 C++媲美的。动态分发闭包在实际中更加常用于回调函数(callback)。
比如Rust的Web开发框架Rocket的中间件实现,就利用了闭包作为回调函数,其实现如代码清单6-45所示。
代码清单6-45:Rocket框架中间件代码示意
pub struct AdHoc {
name: &'static str,
kind: AdHocKind,
}
pub enum AdHocKind {
...
#[doc(hidden)]
Request(Box<Fn(&mut Request, &Data) + Send + Sync + 'static>),
...
}
impl AdHoc {
...
pub fn on_request<F>(name: &'static str, f: F) -> AdHoc
where F: Fn(&mut Request, &Data) + Send + Sync + 'static
{
AdHoc{name, kind: AdHocKind::Request(Box::new(f))}
}
}
impl Fairing for AdHoc {
...
fn on_request(&self, request: &mut Request, data: &Data) {
if let AdHocKind::Request(ref callback) = self.kind {
callback(request, data)
}
}
...
}代码清单6-45展示了Rocket框架中间件Fairing实现的简单示意,为了突出重点,这里省略了很多代码。
代码第1行定义了AdHoc结构体,接下来定义AdHocKind枚举体,其中包含了四种枚举值(Attach、Launch、Request、Response),本示例中只显示出Request一种,它包含的值类型是一个trait对象的闭包,Box<Fn(&mut Request,&Data)+Send+Sync+'static>。
代码第13行为AdHoc结构体实现了on_request方法,其参数为一个闭包F,该闭包的trait限定为Fn(&mut Request,&Data)+Send+Sync+'static,表明该闭包接收两个参数,第一个是可变引用,第二个是不可变引用,并且是可以在线程中安全传递的,'static 生命周期用来约束该闭包必须是一个逃逸闭包,只有逃逸闭包才能装箱,代码清单6-46的示例展示了这一点。
代码清单6-46:测试'static约束
fn main() {
let s = "hello";
let c: Box<Fn() + 'static> = Box::new(move||{s;})
}如果对代码清单6-46第3行的闭包去掉move关键字,则变为Fn闭包,会以不可变引用方式来捕获变量绑定s,因为有了'static约束,编译器会报错。现在使用了move关键字,会强制执行复制语义,则编译通过。
回到代码清单 6-45 中,从第 21 行代码开始,为 AdHoc 实现了 Fairing trait 中定义的on_request方法,该方法内部使用了if let,如果匹配到相关的闭包,则调用该闭包。这是动态分发的闭包在实际中作为回调函数的示例。
(2) 闭包作为函数返回值
因为闭包是trait语法糖,所以无法直接作为函数的返回值,如果要把闭包作为返回值,必须使用trait对象,如代码清单6-47所示。
代码清单6-47:将闭包作为函数返回值
fn square() -> Box<Fn(i32)> -> i32 {
Box::new(|i| i * i)
}
fn main() {
let square = square();
assert_eq!(4, square(2));
assert_eq!(9, square(3));
}代码清单6-47返回一个闭包来计算平方。返回的闭包为trait对象Box<Fn(i32)->i32>,在main函数中可以直接调用它。代码清单 6-47 中的闭包指定为 Fn,可以多次调用,但是如果希望只调用一次,那么是不是就可以直接指定FnOnce呢?如代码清单6-48所示。
代码清单6-48:指定返回闭包为FnOnce
fn square() -> Box<FnOnce(i32) -> i32> {
Box::new(|i| {i * i})
}
fn main() {
let square = square();
assert_eq!(4, square(2));
}
// 编译会报如下错误:
error[E0161]: cannot move a value of type std::ops::FnOnce(i32) -> i32 the size of std::ops::FnOnce(i32) -> i32 cannot be statically determined该错误的含义是:对于编译期无法确定大小的值,不能移动其所有权。在代码清单6-48中,如果要调用闭包Box<FnOnce(i32)->i32>,就必须先把FnOnce(i32)->i32从Box<T>中移出来。而此时Box <T>中的T无法在编译期确定大小,不能移动所有权,所以就报出了上述错误。
FnOnce 装箱为 Box<FnOnce>之后,其对应的由编译器生成的闭包结构体实例就是Box<ClosureStruct>类型(假如闭包结构体名为ClosureStruct),该闭包结构体实现FnOnce的call_once方法的接收者本来是self,也就是闭包结构体实例,现在变成了Box<self>,也就是装箱的闭包结构体实例。现在想从Box<self>里移出self这个闭包结构体实例来进行调用,因为编译期无法确定其大小,所以无法获取self。而对于Fn和FnMut来说,装箱以后分别对应的是&Box<self>和&mut Box<self>,所以不会报错。对于此问题,Rust给出了一个解决方案,如代码清单6-49所示。
代码清单6-49:使用FnBox代替FnOnce
#![feature(fnbox)]
use std::boxed::FnBox;
fn square() -> Box<FnBox(i32) -> i32> {
Box::new(|i| {i * i})
}
fn main() {
let square = square();
assert_eq!(4, square(2));
}代码清单6-49第1行使用了#![feature(fnbox)]特性,同时也需要使用use来引入定义于标准库的boxed模块中的FnBox trait。只需要简单地把FnOnce替换为FnBox,即可解决上面编译错误的问题。这是因为FnBox施加了一点小小的“魔法”,代码清单6-50展示了FnBox的源码。
代码清单6-50:FnBox源码示意
#[rustc_paren_sugar]
pub trait FnBox<A> {
type Output;
fn call_box(self: Box<Self>, args: A) -> Self::Output;
}
impl<A, F> FnBox<A> for F
where F: FnOnce<A>
{
type Output = F::Output;
fn call_box(self: Box<F>, args: A) -> F::Output {
self.call_once(args)
}
}
impl<'a, A, R> FnOnce<A> for Box<FnBox<A, Output = R> + 'a> {
type Output = R;
extern "rust-call" fn call_once(self, args: A) -> R {
self.call_box(args)
}
}由于篇幅限制,代码清单6-50只展示了部分FnBox源码。看得出来,FnBox也是一个调用语法糖,因为使用了#[rustc_paren_sugar]属性,该trait实现了call_box方法,第一个参数和之前的Fn、FnMut、FnOnce定义的方法有很大不同,该方法的第一个参数self是Box<Self>类型。其实之前trait中的self、&self、&mut self参数都是一种省略形式,其完整形式如下所示。
- Self对应self:Self。
- &self 对应 self:&Self。
- &mut self对应 self:&mut Self。
理论上,self:SomeType<Self>这种形式应该适用于任意类型(SomeType),但实际上,这里只支持Box<T>。所以,self:Box<Self>这种类型指定会自动解引用并移动Self的所有权,因为Box<T>支持DerefMove(参见第5章)。
Self:Box<self>是通过调用 call_box 来间接调用 call_once 的,因为 Box<FnBox>实现了FnOnce。这看上去完全是一个“曲线救国”的方案,所以,在装箱时使用FnBox来替代FnOnce只是临时的解决方案,在未来的Rust版本中,FnBox会被弃用。
出现这种问题的根本原因在于,Rust中的函数返回值里只能出现类型。虽然有trait对象可用,但是性能上也会有所消耗。为了解决此问题,Rust团队提出了一个新的方案,叫impl Trait语法,该方案可以让函数直接返回一个trait,如代码清单6-51所示。
代码清单6-51:impl Trait示例
fn square() -> impl FnOnce(i32) -> i32 {
|i| {i * i}
}
fn main() {
let square = square();
assert_eq!(4, square(2));
}代码清单6-51中用到的impl Trait语法是Rust 2018版本中引入的。impl Trait代表的是实现了指定trait的那些类型,相当于泛型,属于静态分发。
代码第2行直接返回一个impl FnOnce(u8,u8)->u8。在impl关键字后面加上了闭包trait,这样就可以直接返回一个FnOnce trait。
6.2.5 高阶生命周期
闭包可以作为函数的参数和返回值,那么闭包参数中如果含有引用的话,其生命周期参数该如何标注?先来思考代码清单6-52。
代码清单6-52:泛型trait作为trait对象时的生命周期参数
use std::fmt::Debug;
trait DoSomething<T> {
fn do_sth(&self, valut: T);
}
impl<'a, T: Debug> DoSomething<T> for &'a usize {
fn do_sth(&self, value: T) {
println!("{:?}", value);
}
}
fn foo<'a>(b: Box<DoSomething<&'a usize>>) {
let s: usize = 10;
b.do_sth(&s)
}
fn main() {
let x = Box::new(&2usize);
foo(x);
}代码清单6-52定义了DoSomething<T>,它是一个泛型trait,其中定义了方法签名do_sth,然后为&usize类型实现了该trait。
代码第 10 行到第 13 行定义了一个函数 foo,其参数 b 以 trait 对象Box<DoSomething<&usize>>为类型。在该函数内,参数b调用do_sth方法,并把局部变量绑定s的不可变借用作为do_sth方法的参数。整个函数foo也被标注了生命周期参数。在main函数中声明了一个Box<&usize>变量绑定x,并调用foo(x)。整段代码在编译时会报如下错误:
error[E0597]: `s` does not live long enough
12 | b.do_sth(&s)
| ^ does not live long enough
13 | }
| - borrowed value only lives untill here该错误表明,s的生命周期不够长,在foo函数调用结束后就会被析构,从而&s就会变成悬垂指针,这是Rust绝不可能允许出现的情况,如图6-3所示。
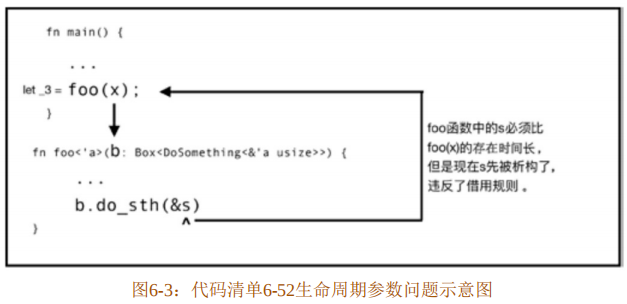
代码清单6-52第10行的foo函数签名中的生命周期参数有什么问题呢?现在这样的生命周期参数的意义是,把foo函数自身的生命周期和其内部的局部变量绑定s的生命周期关联了起来,这就要求,foo函数内b.do_sth(&s)方法调用参数s的生命周期必须长于main函数中foo(x)函数调用的生命周期。在main函数中会自动产生临时变量绑定,代码第16行相当于let_3=foo(x)。这违反了第5章学过的借用规则,有产生悬垂指针的风险。
然而,foo函数中传入的trait对象Box<DoSomething<&usize>>包含的&usize引用是从外部引入的,如代码清单6-52第15行所示,是在main函数中直接定义好,然后才传给foo函数的。所以,该引用的生命周期和foo函数没有直接关系。目前代码清单6-52的生命周期参数标记则完全无法正确表达这一层意思,那么对于这种情况该如何定义生命周期参数呢?
Rust为此专门提供了一个方案,叫作高阶生命周期(Higher-Ranked Lifetime),也叫高阶trait限定(Higher-Ranked Trait Bound,HRTB)。该方案提供了一个for<>语法,具体使用方式如代码清单6-53所示。
代码清单6-53:使用for<>语法
use std::fmt::Debug;
trait DoSomething<T> {
fn do_sth(&self, value: T);
}
impl<'a, T: Debug> DoSomething<T> for &'a usize {
fn do_sth(&self, value: T) {
println!("{:?}". value);
}
}
fn bar(b: Box<for<'f> DoSomething<&'f unsize>>) {
let s: usize = 10;
b.do_sth(&s);
}
fn main() {
let x = Box::new(&2usize);
bar(x);
}代码清单6-53第10行定义了bar函数,其函数签名中的生命周期参数使用了高阶生命周期参数for<'f>DoSomething<&'f usize>,这样就修复了生命周期的问题,正常编译运行。
for<>语法整体表示此生命周期参数只针对其后面所跟着的“对象”,在本例中是DoSomething<&'f usize>,生命周期参数'f是在for<'f >中声明的。使用for<'f >语法,就代表bar函数的生命周期和DoSomething<&'f usize>没有直接关系,所以编译正常。
实际开发中会经常用闭包,而闭包实现的三个trait本身也是泛型trait,所以肯定也存在闭包参数和返回值都是引用类型的情况,如代码清单6-54所示。
代码清单6-54:闭包参数和返回值都是引用类型的情况
struct Pick<F> {
data: (u32, u32),
func: F,
}
impl<F> Pick<F>
where F: Fn(&(u32, u32)) -> &u32
{
fn call(&self) -> &u32 {
(self.func)(&self.data)
}
}
fn max(data: &(u32, u32)) -> &u32 {
if data.0 > data.1 {
&data.0
} else {
&data.1
}
}
fn main() {
let elm = Pick {data: (3, 1), func: max};
println!("{}", elm.call());
}在代码清单6-54中,泛型结构体Pick模拟了闭包的行为,字段data使用元组类型存储模拟闭包的参数,字段func用来存储一个可执行的闭包。
代码第5行到第11行为结构体Pick实现了一个call方法,泛型F使用Fn(&(u32,u32))->&u32作为trait限定。整段代码编译正常运行。
值得注意的是,此处的trait限定中使用了引用类型,但是并没有显式地标记生命周期参数,为什么可以正常编译呢?这是因为编译器自动为其补齐了生命周期参数。
代码第9行会调用存储于结构体Pick中的闭包,并且会把call方法中的&self作为参数进行传递。这个调用与代码清单6-52和6-53中所示的情况很相似,如果要显式地添加生命周期参数,则不能让call方法自身的生命周期和self.func方法的生命周期相关联,因为闭包的捕获引用是从外部环境获取的,和call方法没有关系。否则编译肯定无法通过,比如像下面这种写法就会产生编译错误:
fn call<'a>(&'a self) -> &'a u32 {
(self.func)(&self.data)
}所以这里正确地使用生命周期参数的方式就是用高阶生命周期,如代码清单6-55所示。
代码清单6-55:编译器按高阶生命周期来自动补齐闭包参数中的生命周期参数
struct Pick<F> {
data: (u32, u32),
func: F,
}
impl<F> Pick<F>
where F: for<'F> Fn(&'f (u32, u32)) -> &'f u32, // 显示指定
{
fn call(&self) -> &u32 {
(self.func)(&self.data)
}
}
fn max(data: &(u32, u32)) -> &u32 {
if data.0 > data.1 {
&data.0
} else {
&data.1
}
}
fn main() {
let elm = Pick {data: (3, 1), func: max};
println!("{}", elm.call());
}代码清单6-55第6行使用了高阶生命周期,代码正常编译运行。但需要注意的是,高阶生命周期的这种for<>语法只能用于标注生命周期参数,而不能用于其他泛型类型。
6.3 迭代器
在Rust语言中,闭包最常见的应用场景是,在遍历集合容器中的元素的同时,按闭包内指定的逻辑进行操作。比如代码清单6-42中实现的any方法,就利用了for循环来迭代动态数组,依次查找符合闭包指定条件的元素。
用循环语句迭代数据时,必须使用一个变量来记录数据集合中每一次迭代所在的位置,而在许多编程语言中,已经开始通过模式化的方式来返回迭代过程中集合的每一个元素。这种模式化的方式就叫迭代器(Iterator)模式,使用迭代器可以极大地简化数据操作。迭代器设计模式也被称为游标(Cursor)模式,它提供了一种方法,可以顺序访问一个集合容器中的元素,而又不需要暴露该容器的内部结构和实现细节。
6.3.1 外部迭代器和内部迭代器
迭代器分为两种,外部迭代器(External Iterator)和内部迭代器(Internal Iterator)。
外部迭代器也叫主动迭代器(Active Iterator),它独立于容器之外,通过容器提供的方法(比如,next方法就是所谓的游标)来迭代下一个元素,并需要考虑容器内可迭代的剩余数量来进行迭代。外部迭代器的一个重要特点是,外部可以控制整个遍历进程。比如Python、Java和C++语言中的迭代器,就是外部迭代器。
内部迭代器则通过迭代器自身来控制迭代下一个元素,外部无法干预。这意味着,只要调用了内部迭代器,并通过闭包传入了相关操作,就必须等待迭代器依次为其中的每个元素执行完相关操作以后才可以停止遍历。比如Ruby语言中的each迭代器就是典型的内部迭代器。
早期的(1.0版本之前)Rust提供的是内部迭代器,而内部迭代器无法通过外部控制迭代进程,再加上Rust的所有权系统,导致使用起来很复杂。
代码清单6-56展示了一个自定义的内部迭代器。
代码清单6-56:自定义的内部迭代器
trait InIterator<T: Copy> {
fn each<F: Fn(T) -> T>(&mut self, f: F);
}
impl<T: Copy> InIterator<T> for Vec<T> {
fn each<F: Fn(T) -> T>(&mut self, f: F) {
let mut i = 0;
while i < self.len() {
self[i] = f(self[i]);
i += 1;
}
}
}
fn main() {
let mut v = vec![1, 2, 3];
v.each(|i| i * 3);
assert_eq!([3, 6, 9], &v[..3]);
}代码清单6-56创建了一个自定义的内部迭代器each。看得出来,内部迭代器与容器的绑定较紧密,并且无法从外部来控制其遍历进程。更重要的是,对于开发者来说,扩展性较差。Rust官方和社区经过很长时间的论证,决定改为外部迭代器,也就是for循环,如代码清单6-57所示。
代码清单6-57:for循环示例
fn main() {
let v = vec![1, 2, 3, 4, 5];
for i in v {
println!("{}", i);
}
}代码清单6-57是一个简单的for循环示例。for循环是一个典型的外部迭代器,通过它可以遍历动态数组v中的元素,并且此遍历过程完全可以在动态数组v之外进行控制。Rust中的for循环其实是一个语法糖。代码清单6-58展示了for循环展开后的等价代码。
代码清单6-58:for循环展开后的等价代码
fn main() {
let v = vec![1, 2, 3, 4, 5];
{ // 等价于for循环的scope
let mut _iterator = v.into_iter();
loop {
match _iterator.next() {
Some(i) => {
println!("{}", i);
}
None => break,
}
}
}
}代码清单6-58从第3行开始,创造了一个内部作用域,等价于for循环的作用域。代码第4行通过调用v的into_iter方法声明了一个可变迭代器_iterator。在第5行的loop循环中,通过match匹配此迭代器的next方法,遍历v中的元素,直到next方法返回None,退出循环,遍历结束。
6.3.2 Iterator trait
简单来说,for循环就是利用迭代器模式实现的一个语法糖,它属于外部迭代器。迭代器也是Rust一致性的典型表现之一。不出所料,Rust 中依然使用了trait来抽象迭代器模式。代码清单6-59展示了Rust中迭代器Iterator trait的源码。
代码清单6-59:Iterator trait源码示意
trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
}代码清单6-59展示了Iterator trait是Rust中对迭代器模式的抽象接口。其中next方法是实现一个迭代器时必须实现的方法。事实上,该trait中包含了很多其他方法,基本都包含了默认实现。该trait中还包含了一个关联类型Item,并且next方法会返回Option<Self::Item>类型。Item和Self可以看作占位类型,它们表示实现该trait的具体类型的相关信息。
通过实现该trait,可以创建自定义的迭代器,如代码清单6-60所示。
代码清单6-60:通过实现Iterator trait创建自定义迭代器
struct Counter {
count: usize,
}
impl Iterator for Counter {
type Item = usize;
fn next(&mut self) -> Option<usize> {
self.count += 1;
if self.count < 6 {
Some(self.count)
} else {
None
}
}
}
fn main() {
let mut counter = Counter {count: 0};
assert_eq!(Some(1), counter.next());
assert_eq!(Some(2), counter.next());
assert_eq!(Some(3), counter.next());
assert_eq!(Some(4), counter.next());
assert_eq!(Some(5), counter.next());
assert_eq!(None, counter.next());
}代码清单6-60中定义了一个结构体Counter,为其实现Iterator之后,它就成为了一个迭代器。通过调用next方法来迭代其内部元素。
值得注意的是,在为Counter实现next方法时,指定了关联类型Item为usize类型,因为Counter中字段count是usize类型,next方法要返回的是Option<usize>类型。
代码第8行,next方法的if表达式中的条件被硬编码为小于6,这只是为了演示。对于一个真正的迭代器,除了需要使用next方法获取下一个元素,还需要知道迭代器的长度信息,这对于优化迭代器很有帮助。
在Iterator trait中还提供了一个方法叫size_hint,代码清单6-61展示了其默认实现。
代码清单6-61:Iterator trait提供的size_hint方法源码示意
pub trait Iterator {
type Item;
...
fn size_hint(&self) -> (usize, Option<usize>) {
(0, None)
}
...
}代码清单 6-61 展示了 size_hint 方法的默认实现,其返回类型是一个元组(usize,Option<usize>),此元组表示迭代器剩余长度的边界信息。元组中第一个元素表示下限(lower bound),第二个元素表示上限(upper bound)。第二个元素是Option<usize>类型,代表已知上限 或者上限超过usize的最大取值范围,比如无穷迭代。此方法的默认返回 值(0,None)适用于任何迭代器。
代码清单6-62展示了将数组转换为迭代器的size_hint方法。
代码清单6-62:将数组转换为迭代器的size_hint
fn main() {
let a: [i32; 3] = [1, 2, 3];
let mut iter = a.iter();
assert_eq!((3, Some(3)), iter.size_hint());
iter.next();
assert_eq!((2, Some(2)), iter.size_hint());
}代码清单6-62中的数组通过iter方法转换成为一个迭代器,每次调用next方法,迭代器的剩余长度就会减少,直到减为0为止。方法size_hint返回的元组上限和下限是一致的。第3行方法调用a.iter()使用了数组a的不可变借用,其类型为&'a [i32;3]。对于&'a [T]和&'a mut [T] 类型,size_hint方法实际返回的是迭代器起点指针到终点指针的距离值,如图6-4所示。
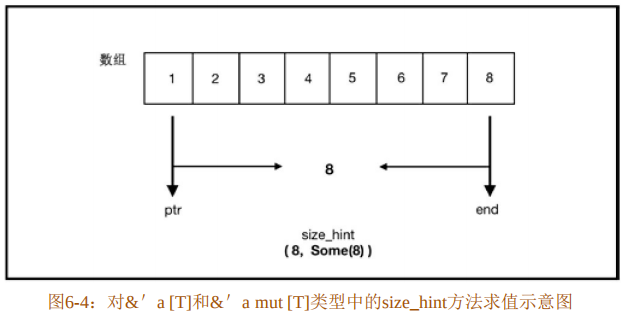
第3行方法调用a.iter()返回的迭代器是一个结构体,其成员包含了起始指针ptr和终点指针end,它们之间的距离就是size_hint方法返回的 值。
方法size_hint的目的就是优化迭代器,不要忘记Rust是一门系统级编程语言,性能永远是一项重要的指标。迭代器和集合容器几乎形影不离,实际开发中经常有使用迭代器来扩展集合容器的需求,此时方法size_hint就派上用场了。如果事先知道准确的迭代器长度,就可以做到精准地扩展容器容量,从而避免不必要的容量检查,提高性能。代码清单6-63展示了如何使用迭代器来追加字符串。
代码清单6-63:使用迭代器来追加字符串
fn main() {
let mut message = "Hello".to_string();
message.extend(&[' ', 'R', 'u', 's', 't']);
assert_eq!("Hello Rust", &message);
}代码清单6-63中声明了String类型的字符串message,通过调用extend方法为其追加字符。事实上,extend方法是被定义于Extend trait中的。代码清单6-64展示了Extend和String中实现extend方法的源码。
代码清单6-64:Extend和String类型实现extend方法的源码示意
pub trait Extend<A> {
fn extend<T>(&mut self, iter: T)
where
T: IntoIterator<Item = A>;
}
...
impl Extend<char> for String {
fn extend<I: IntoIterator<Item = char>>(&mut self, iter: I) {
let iterator = iter.into_iter();
let (lower_bound, _) = iterator.size_hint();
self.reserve(lower_bound);
for ch in iterator {
self.push(ch)
}
}
}Extend trait是一个泛型trait,其中定义了extend方法,这是一个泛型方法,其泛型参数T使用了trait限定IntoIterator<Item=A>,这表示该泛型方法只接受实现了IntoIterator的类型。而String类型正好针对char类型实现了该泛型trait。
在代码第9行String类型实现的extend方法中,首先使用into_iter方法获取了一个迭代器,然后通过迭代器的size_hint方法获取其长度,代码第10 行取的是迭代器的下限。对于数组来说,上限和下限的值是一样的,所以这里取哪个都可以。
代码第11行调用了字符串的reserve方法,该方法可以确保扩展的字节长度大于或等于给定的值。这样做是为了避免频繁分配。代码清单6-63中给定的迭代器长度应该是5,那么为字符串分配的额外空间至少应该是20个字节(因为每个字符占4字节),也可能是100个字节。reserve方法只是提供了一种保证,它并不做出分配空间的行为。
代码第12行用for循环遍历该字符迭代器,之后通过String类型的push方法逐个添加给字符串。
现在可以看得出来size_hint方法的重要性了。为了确保该方法可以获得迭代器长度的准确信息,Rust又引入了两个trait,分别是ExactSizeIterator和TrustedLen,它们均是Iterator的子trait,均被定义于std::iter模块中。
- ExactSizeIterator提供了两个额外的方法len和is_empty,要实现len必须先实现Iterator,这就要求size_hint方法必须提供准确的迭代器长度信息。
- TrustedLen是实验性trait,还未正式公开,但是在Rust源码内部,它就像一个标签trait,只要实现了 TrustedLen 的迭代器,其 size_hint 获取的长度信息均是可信任的,有了该 trait就完全避免了容器的容量检查,从而提升了性能。
ExactSizeIterator和TrustedLen的区别在于,后者应用于没有实现ExactSizeIterator的大多数情况。开发者可以根据具体的情况自定义实现ExactSizeIterator,但是对于某些迭代器,开发者并不能为其实现ExactSizeIterator,所以需要TrustedLen做进一步的限定。
6.3.3 IntoIterator trait和迭代器
上一节介绍了Iterator trait,我们了解到,如果想迭代某个集合容器中的元素,必须将其转换为迭代器才可以使用。并且在 for 循环语法糖中,也使用了 into_iter 之类的方法来获取一个迭代器。那么迭代器到底是什么?要寻找答案,必须先从IntoIterator trait开始。
第3章讲过类型转换用到的From和Into两个trait,它们定义了两个方法,分别是from和 into,这两个方法互为反操作。对于迭代器来说,并没有用到这两个 trait,但是这里值得注意的是,Rust中对于trait的命名也是具有高度一致性的。
Rust也提供了FromIterator和IntoIterator两个trait,它们也互为反操作。FromIterator可以从迭代器转换为指定类型,而 IntoIterator 可以从指定类型转换为迭代器。关于FromIterator的细节在6.3.5节会着重介绍,这里先介绍IntoIterator。
代码清单6-65展示了IntoIterator的源码。
代码清单6-65:IntoIterator源码示意
pub trait IntoIterator {
type Item;
type IntoIter: Iterator<Item = Self::Item>;
fn into_iter(self) -> Self::IntoIter;
}从代码清单6-65中可以看出,方法into_iter是在该trait中定义的。into_iter的参数是self,代表该方法会转移方法接收者的所有权。同时,该方法会返回Self::IntoIter类型。Self::IntoIter是关联类型,并且指定了trait限定Iterator<Item=Self::Item>,意味着必须是实现了Iterator的类型才能作为迭代器。
最常用的集合容器就是Vec<T>类型,它实现了IntoIterator,可以通过into_iter方法转换为迭代器。代码清单6-66展示了Vec<T>类型实现IntoIterator的源码。
代码清单6-66:Vec<T>实现IntoIterator源码示意
impl<T> IntoIterator for Vec<T> {
type Item = T;
type IntoIter = IntoIter<T>;
fn into_iter(mut self) -> IntoIter<T> {
unsafe {
...
IntoIter {
buf: Shared::new_unchecked(begin),
cap,
ptr: begin,
end,
}
}
}
}代码清单 6-66 为了演示方便只展示了部分源码。看得出来,最终返回的是一个定义于std::vec模块中的IntoIter结构体。该结构体包含下列四个成员字段。
- Buf,通过Vec<T>类型的动态数组起始地址begin生成一个内部使用的Shared指针,指向该动态数组中实际存储的数据。
- Cap,获得该动态数组的容量大小,也就是内存占用大小。
- Ptr,指定了begin的值,代表迭代器的起始指针。
- End,代表迭代器的终点指针,根据Vec<T>动态数组的长度len和起始地址begin计算offset获得。
IntoIter结构体也实现了Iterator trait,拥有了next、size_hint和count三个方法,它是一个名副其实的迭代器。
简单而言,就是Vec<T>实现了IntoIterator,因此可以通过into_iter方法将一个Vec<T>类型的动态数组转换为一个IntoIter结构体。IntoIter结构体拥有该动态数组的全部信息,并且获得了该动态数组的所有权。同时,IntoIter结构体实现了Iterator trait,允许其通过next、size_hint和count方法对其进行迭代处理。所以,IntoIter就是Vec<T>转换而成的迭代器。整个过程如图6-5所示。
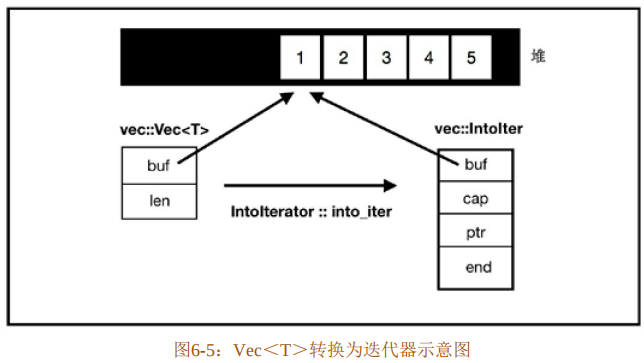
转换 IntoIter 迭代器的代价是要转移容器的所有权,在实际开发中,有很多情况是不能转移所有权的。因此,Rust 还提供了另外两个迭代器专门处理这种情况,分别是 Iter 和IterMut。这三种迭代器类型和所有权有如下对应关系。
- IntoIter,转移所有权,对应self。
- Iter,获得不可变借用,对应&self。
- IterMut,获得可变借用,对应&mut self。
Iter和IterMut迭代器的典型应用就是slice类型,代码清单6-67展示了slice类型数组的循环示例。
代码清单6-67:slice类型数组循环示例
fn main() {
let arr = [1, 2, 3, 4, 5];
for i in arr.iter() {
println!("{:?}", i);
}
println!("{:?}", arr);
}代码清单6-67中声明了slice类型的数组,该类型的数组使用for循环时,并不能自动转换为迭代器,因为并没有为[T]类型实现IntoIterator, 而只是为&'a [T]和&'a mut [T]类型实现了IntoIterator,相应的into_iter方法内部实际也分别调用了iter和iter_mut方法。也就是说,在for循环中使用&arr可以自动转换为迭代器,而无须显式地调用iter方法。用iter或iter_mut方法可以将slice类型的数组转换为Iter或IterMut迭代器。
代码清单6-68展示了迭代器Iter的源码。
代码清单6-68:Iter迭代器的源码示意
pub struct Iter<'a, T: 'a> {
ptr: *const T,
end: *const T,
_marker: marker::PhantomData<&'a T>,
}可以看得出来,迭代器Iter中只包含ptr和end指针,均为不可变的裸指针*const T,用于计算迭代器的长度,而_marker字段只是编译期标记,是为了让生命周期参数'a有用武之地,通过编译。关于PhantomData的更多内容会在第13章中详细介绍。
Iter 迭代器也被称为不可变迭代器,因为它不能改变原来容器中的数据。代码清单 6-69展示了可变迭代器IterMut的源码。
代码清单6-69:IterMut迭代器源码示意
pub struct IterMut<'a, T: 'a> {
ptr: *mut T,
end: *mut T,
_marker: marker::PhantomData<&'a mut T>,
}迭代器IterMut中包含的ptr和end指针均为可变裸指针,意味着此迭代器可以改变容器内的值。代码清单6-70展示了如何使用iter_mut方法获得一个可变迭代器,然后使用它在for循环中遍历并修改slice类型数组中的每个元素。
代码清单6-70:使用可变迭代器
fn main() {
let mut arr = [1, 2, 3, 4, 5];
for i in arr.iter_mut() {
*i += 1;
}
println!("{:?}", arr); // [2, 3, 4, 5, 6]
}Rust中的迭代器其实不仅有IntoIter、Iter和IterMut三种。比如,String类型和HashMap类型均有Drain迭代器,可以迭代删除指定范围内的值,为字符串和HashMap的处理提供方便。不管Rust中的迭代器有多少种,重要的是,这些迭代器的实现都遵循上述规律,这也是Rust高度一致性的设计所带来的好处。反过来,不管是Slice类型的数组,还是Vec<T>类型的动态数组,亦或是HashMap等容器,迭代器模式都将其统一抽象地看待成一种数据流容器,通过对迭代器提供的“游标”进行增减就可以遍历流中的每一个元素。
6.3.4 迭代器适配器
迭代器将数据容器的操作抽象为了统一的数据流,这就好比现实世界中,每家每户的自来水管都是标准化的接口,只需要打开水龙头就可以按需用水。但是不同的场景有不同的需求,厨房用水需要对水进行加热;而洗澡间则不只需要加热,还需要让冷热水混合,甚至还需要将水流分解为更细小的水流,这样洗澡才够舒服。要满足这些不同的需求,所要做的不是让自来水厂按需铺设专门的管道,而只需要在自来水接口上安装不同的设备。厨房只需要安装厨宝,将流经的水加热后再输出;洗澡间需要安装热水器,另外铺设冷热管道和花洒即可满足需求。这些不同的设备虽然功能不同,但是它们都遵循自来水管道的标准规范,这样才能适配各种各样的场景。
在软件世界中,通过适配器模式同样可以将一个接口转换成所需的另一个接口。适配器模式能够使得接口不兼容的类型在一起工作。适配器也有一个别名,叫包装器(Wrapper)。Rust在迭代器基础上增加了适配器模式,这就极大地增强了迭代器的表现力。
Map适配器Map是Rust里最常见的一个迭代器适配器,如代码清单6-71所示。
代码清单6-71:map方法示例
fn main() {
let a = [1, 2, 3];
let mut iter = a.into_iter().map(|x| 2 * x);
assert_eq!(iter.next(), Some(2));
assert_eq!(iter.next(), Some(4));
assert_eq!(iter.next(), Some(6));
assert_eq!(iter.next(), None);
}代码清单6-71的第3行通过into_iter方法将数组转换为迭代器,然后调用迭代器的map方法创建了一个新的迭代器iter。然后依次调用iter的next方法迭代数组中的每个元素,同时,对每个元素执行闭包中指定的 逻辑,最后输出相应结果。
map 方法创建的新迭代器就是一个迭代器适配器。代码清单 6-72展示了定义于std::iter::Iterator中的map方法源码。
代码清单6-72:迭代器map方法源码示意
pub trait Iterator {
type Item;
...
fn map<B, F>(self, f: F) -> Map<Self, F>
where
Self: Sized,
F: FnMut(Self::Item) -> B,
{
Map {iter: self, f: f}
}
}map是Iterator trait中实现的方法,第一个参数self代表实现Iterator的具体类型,第二个参数f是一个FnMut闭包。该闭包trait限定为 FnMut(Self::Item)->B,其中的Self::Item是指为实现Iterator具体类型设置的关联类型Item。最终,该方法返回了一个结构体Map<Self,F>,值得注意的是,这里Self被限定为Sized,否则Self在编译期无法确定大小就会报错。这个结构体Map就是一个迭代器适配器。
代码清单6-73展示了定义Map的源码。
代码清单6-73:迭代器适配器Map源码示意
#[must_use="iterator adaptors are lazy ......"]
#[derive(Clone)]
pub struct Map<I, F> {
iter: I,
f: F,
}
impl<B, I: Iterator, F> Iterator for Map<I, F>
where F: FnMut(I::Item) -> B
{
type Item = B;
fn next(&mut self) -> Option<B> {
self.iter.next().map(&mut self.f)
}
fn size_hint(&self) -> (usize, Option<usize>) {
self.iter.size_hint()
}
...
}看得出来,Map是一个泛型结构体,它只有两个成员字段,一个是iter,一个f,分别存储的是迭代器和传入的闭包。然后为其实现了Iterator trait,Map就成为了一个地道的迭代器。与一般迭代器不同的地方在于,其核心方法next和size_hint都是调用其内部存储的原始迭代器的相应方法。值得注意的是,第12行调用的map方法是next方法返回的Option<T>中实现的另一个 map 方法,后面的章节中会介绍该方法。 通过第 12 行代码中的 map 方法传入Map中存储的闭包,就可以对每个元素执行相应的逻辑,最终再返回一个Option<T>类型。
你可能已经注意到了,代码清单 6-73 中迭代器适配器 Map 的源码上方使用了#[must_use="……"]属性,该属性是用来发出警告,提示开发者迭代器适配器是惰性的,也就是说,如果没有对迭代器产生任何“消费”行为,它是不会发生真正的迭代的。这就好比水龙头上装好了花洒,但是不打开水龙头,就无法真正使用花洒。而调用next方法就属于“消费”行为。Rust中所有的迭代器适配器都使用了must_use来发出警告。
了解Map适配器之后,再回到代码清单6-71来查看其整个执行流程示意,如图6-6所示。
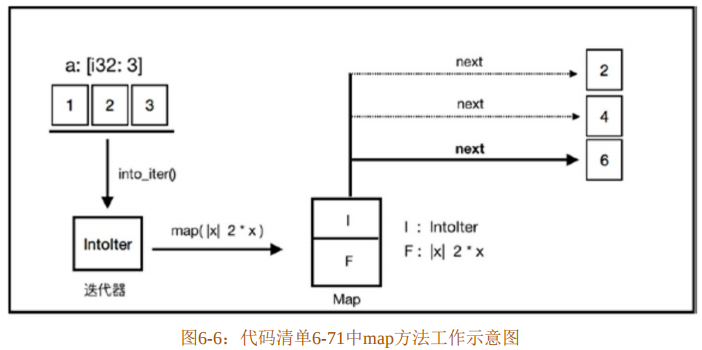
图6-6是代码清单6-71的执行过程的简单示意图。数组a通过into_iter方法创建了迭代器IntoIter并转移所有权,然后IntoIter再调用Iterator trait中实现的map方法,传入闭包,IntoIter迭代器创建了一个迭代器适配器Map。Map中存储了迭代器IntoIter和传入的闭包F,然后通过next方法遍 历“消费”其元素,依次产生新的数据。
其他适配器
除了Map,Rust标准库中还提供了很多迭代器适配器,都定义于std::iter模块中。下面是一个迭代器适配器常用列表。
- Map,通过对原始迭代器中的每个元素调用指定闭包来产生一个新的迭代器。
- Chain,通过连接两个迭代器来创建一个新的迭代器。
- Cloned,通过拷贝原始迭代器中全部元素来创建新的迭代器。
- Cycle,创建一个永远循环迭代的迭代器,当迭代完毕后,再返回第一个元素开始迭代。·
- Enumerate,创建一个包含计数的迭代器,它会返回一个元组(i,val),其中 i 是 usize类型,为迭代的当前索引,val是迭代器返回的值。
- Filter,创建一个基于谓词判断式(predicate,产生布尔值的表达式)过滤元素的迭代器。
- FlatMap,创建一个类似Map的结构的迭代器,但是其中不会含有任何嵌套。
- FilterMap,相当于Filter和Map两个迭代器依次使用后的效果。
- Fuse,创建一个可以快速结束遍历的迭代器。在遍历迭代器时, 只要返回过一次None,那么之后所有的遍历结果都为None。该迭代器适配器可以用于优化。
- Rev,创建一个可以反向遍历的迭代器。
代码清单6-74展示了其中一部分迭代器适配器使用的示例。
代码清单6-74:部分迭代器适配器使用示例
fn main() {
let arr1 = [1, 2, 3, 4, 5];
let c1 = arr1.iter().map(|x| 2 * x).collect::<Vec<i32>>();
assert_eq!(&c1[..], [2, 4, 6, 8, 10]);
let arr2 = ["1", "2", "3", "h"];
let c2 = arr2.iter().filter_map(|x| x.parse().ok())
.collect::<Vec<i32>>();
assert_eq!(&c2[..], [1, 2, 3]);
let arr3 = ['a', 'b', 'c'];
for (idx, val) in arr3.iter().enumerate() {
println!("idx: {:?}, val: {}", idx, val.to_uppercase());
}
}代码清单6-74第2行到第4行使用了map方法,相应地,它会创建Map适配器。最终通过collect方法迭代生成第3行断言中所显示的Vec<i32>动态数组。
代码第5行到第8行使用了filter_map方法,它会创建FilterMap适配器。同样通过collect方法生成第7行断言中所示的Vec<i32>动态数组。
代码第9行到第12行使用了enumerate方法,它会创建Enumerate适配器,这里使用了for循环,因为此迭代器的next方法返回的是元组,所以第10行for循环内使用(idx,val)形式。
另外一个值得介绍的迭代器适配器是 Rev,它使用 rev 方法,可以支持反向遍历,如代码清单6-75所示。
代码清单6-75:rev方法示例
fn main() {
let a = [1, 2, 3];
let mut iter = a.iter().rev();
assert_eq!(iter.next(), Some(&3));
assert_eq!(iter.next(), Some(&2));
assert_eq!(iter.next(), Some(&1));
assert_eq!(iter.next(), None);
}代码清单6-75中使用rev方法创建了迭代器适配器,调用其next方法就是反向遍历。这里面存在什么“魔法”呢?代码清单6-76展示了rev方法 的源码。
代码清单6-76:rev源码示意
pub trait Iterator {
type Item;
fn rev(self) -> Rev<Self>
where Self: Sized + DoubleEndedIterator,
{
Rev {iter: self}
}
}看得出来,rev 方法返回了 Rev 结构体,它就是实现反转遍历的迭代器适配器。注意这里Self的trait限定中包含了一个DoubleEndIterator trait,意味着只有实现该trait的类型才可以使用此方法。
代码清单6-77展示了Rev迭代器适配器的源码。
代码清单6-77:Rev迭代器适配器源码示意
pub struct Rev<T> {
iter: T,
}
impl<I> Iterator for Rev<I>
where I: DoubleEndedIterator,
{
type Item = <I as Iterator>::Item;
fn next(&mut self) -> Option<<I as Iterator>::Item> {
self.iter.next_back()
}
}Rev泛型结构体中只有一个成员字段iter,只用来保存迭代器。在为其实现Iterator时,指定了DoubleEndIterator限定。并且将关联类型Item 通过无歧义完全限定语法指定了Iterator中的关联类型。
值得注意的是,在 next 方法中,调用了 Rec 中存储的迭代器的next_back 方法。这个next_back方法实际上是在DoubleEndIterator中定义的,代码清单6-78展示了其源码。
代码清单6-78:DoubleEndIterator源码示意
pub trait DoubleEndedIterator: Iterator {
fn next_back(&mut self) -> Option<Self::Item>;
}限于篇幅,代码清单 6-78 只展示了 DoubleEndIterator 的部分源码。看得出来,DoubleEndIterator是Iterator的子trait,这样定义实际是为了扩展Iterator。next_back和next方法签名非常相似,反转遍历正是基于 此方法来实现的。代码清单6-79展示了next_back的使用示例。
代码清单6-79:next_back方法使用示例
fn main() {
let numbers = vec![1, 2, 3, 4, 5, 6];
let mut iter = numbers.into_iter();
assert_eq!(Some(1), iter.next());
assert_eq!(Some(6), iter.next_back());
assert_eq!(Some(5), iter.next_back());
assert_eq!(Some(2), iter.next());
assert_eq!(Some(3), iter.next());
assert_eq!(Some(4), iter.next());
assert_eq!(None, iter.next());
assert_eq!(None, iter.next_back());
}代码清单6-79第4行调用了next方法,返回的是Some(1),属于正常遍历。
代码第5行和第6行调用了next_back方法,返回的分别是Some(6)和Some(5),说明这两次遍历是反向遍历,但是第7行到第9行依次又调用了next方法,返回值分别是Some(2)、Some(3)和Some(4)。这说明,在执行next_back方法之后,迭代器的“游标”还是会返回到上一次next执行的位置继续执行next,这也是该方法命名为next_back的原因。在第10行和第11行中,迭代已经完毕,均返回None。
至此,我们就知道了Rev迭代器适配器的工作机制:在next迭代中,调用next_back方法。只有实现了 DoubleEndIterator 的迭代器才有next_back 方法,也就是说,只有实现了DoubleEndIterator的迭代器才能调用Iterator::rev方法进行反向遍历。
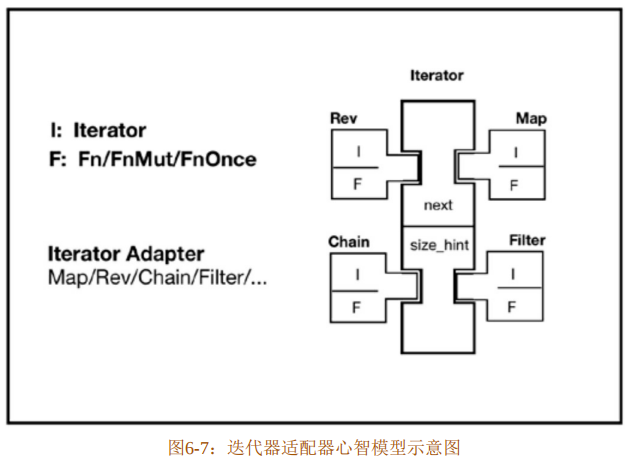
Rust标准库中还提供更多的迭代器适配器,这些迭代器适配器可以自由灵活地组合,以便应对不同的需求。图6-7展示了迭代器适配器的心智模型。
6.3.5 消费器
Rust 中的迭代器都是惰性的,也就是说,它们不会自动发生遍历行为,除非调用 next方法去消费其中的数据。最直接消费迭代器数据的方法就是使用for循环,前面已经了解到,for循环会隐式地调用迭代器的next方法,从而达到循环的目的。
为了编程的便利性和更高的性能,Rust也提供了for循环之外的用于消费迭代器内数据的方法,它们叫作消费器(Consumer)。下面列出了Rust标准库std::iter::Iterator中实现的常用消费器。
- any,其功能类似代码清单6-42中实现的any方法的功能,可以查找容器中是否存在满足条件的元素。
- fold,来源于函数式编程语言。该方法接收两个参数,第一个为初始值,第二个为带有两个参数的闭包。其中闭包的第一个参数被称为累加器,它会将闭包每次迭代执行的结果进行累计,并最终作为 fold 方法的返回值。在其他语言中,也被用作 reduce或inject。
- collect,专门用来将迭代器转换为指定的集合类型。比如代码清单 6-74 中使用collect::<Vec<i32>>()这样的turbofish语法为其指定了类型,最终迭代器就会被转换为Vec<i32>这样的数组。因此, 它也被称为“收集器”。
(1) any和fold
代码清单6-80展示了消费器any和fold的使用示例。
代码清单6-80:any和fold的使用示例
fn main() {
let a = [1, 2, 3];
assert_eq!(a.iter().any(|&x| x != 2), true);
let sum = a.iter().fold(0, |acc, x| acc + x);
assert_eq!(sum, 6);
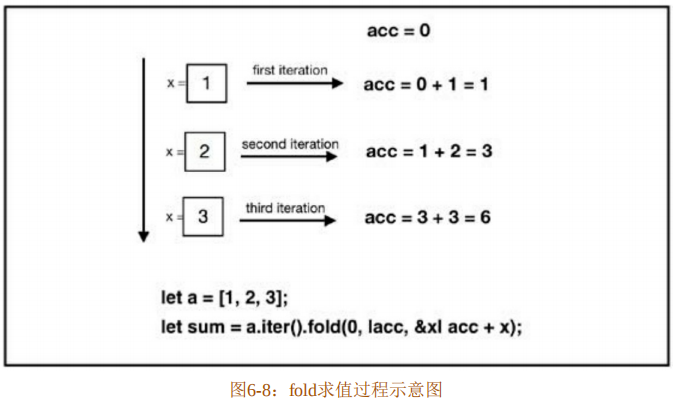
}在代码清单6-80的第3行中,any方法检查数组a中是否存在不等于2的元素,返回true。代码第4行使用fold方法来对数组a进行求和,图6-8展示了fold的求值过程。
代码清单6-80中值得注意的地方在于,any和fold传入的闭包的参数是一个引用。这是为什么呢?代码清单6-81展示了any和fold的源码。
代码清单6-81:any和fold的源码示意
pub trait Iterator {
type Item;
...
fn any<F>(&mut self, mut f: F) -> bool
where Self: Sized,
F: FnMut(Self::Item) -> bool,
{
for x in self {
if f(x) {
return true;
}
}
false
}
...
fn fold<B, F>(self, init: B, mut f: F) -> B
where Self: Sized,
F: FnMut(B, Self::Item) -> B,
{
let mut accum = init;
for x in self {
accum = f(accum, x);
}
accum
}
}看得出来,any和fold的内部都包含了一个for循环,它们实际上是通过for循环来实现内部迭代器的。内部迭代器的特点是,一次遍历到底,不支持return、break或continue操作,因此可以避免一些相应的检查,更有利于底层LLVM的优化。
在代码清单6-80的第3行中,使用的是数组的iter方法,创建的迭代器是Iter类型,该类型的next方法返回的是Option<&[T]>或Option<&mut [T]>类型的值。而for循环实际上是一个语法糖,会自动调用迭代器的 next 方法,for 循环中的循环变量则是通过模式匹配,从next返回的Option<&[T]>或Option<&mut [T]>类型中获取&[T]或&mut [T]类型的值的。
因此,在代码清单6-81的第8行中,any方法的内部for循环中的循环变量x是一个引用。所以,在代码清单6-80中,第3行传给any的闭包参数只能是引用形式,否则就会报错。代码清单6-82展示了更多细节。
代码清单6-82:any方法示意
fn main() {
let arr = [1, 2, 3];
let result1 = arr.iter().any(|&x| x != 2);
let result2 = arr.iter().any(|x| *x != 2);
// error:
// the trait bound `&{integer}:std::cmp::PartialEq<{integer}>` is not satisfied
// let result2 = arr.iter().any(|x| x != 2);
assert_eq!(result1, true);
assert_eq!(result2, true);
}在代码清单6-82中,第3行和第4行的any方法闭包参数分别使用了&x和x,都可以正常运行。对于&x参数的闭包来说,在any方法内部调用时,会因为闭包参数的模式匹配获取x的值,故而可以正常运行。对于x参数的闭包来说,因为闭包执行体使用了解引用操作符,因此也可以正常运行。但是像第7行那样的用法就会抛出注释所示的错误。这是因为此时x为引用,不能进行比较操作。
对于fold方法来说,也是同样的道理,如代码清单6-83所示。
代码清单6-83:使用fold对数组求和示例
fn main() {
let arr = vec![1, 2, 3];
let sum1 = arr.iter().fold(0, | acc, x| acc + x);
let sum2 = arr.iter().fold(0, | acc, x| acc + *x);
let sum3 = arr.iter().fold(0, | acc, &x| acc + x);
let sum4 = arr.into_iter().fold(0, | acc, x| acc + x);
assert_eq!(sum1, 6);
assert_eq!(sum2, 6);
assert_eq!(sum3, 6);
assert_eq!(sum4, 6);
}代码清单6-83中,第3行、第4行和第5行通过iter方法获取的动态数组arr的不可变迭代器为Iter类型,所以能获取多次。第6行使用into_iter方法来创建的迭代器是IntoIter类型,会获取arr的所有权。
因为Iter类型的迭代器在for循环中产生的循环变量为引用,所以在fold内部的for循环中传入闭包的循环变量也是引用。故而代码清单6-83 的第3行、第4行和第5行都可以正常运行。加法操作对引用是适用的。
而IntoIter类型的迭代器的next方法返回的是Option<T>类型,在for循环中产生的循环变量是值,不是引用。所以在代码清单6-83第6行使用fold时,其内部的for循环的循环变量也是值,所以这里闭包参数也只能是值。如果把第6行闭包参数中的x改为&x,或者把闭包体内的x改为*x,均会报错。
Rust除了提供any和fold两个消费器(内部迭代器),还提供了其他的内部迭代器,比如all、for_each和position等,可以在std::iter::Iterator的文档中找到它们的用法和源码。在众多消费器中,最特殊的应该算collect消费器了。
collect消费器
通过前面的几个示例我们已经知道,collect消费器有“收集”功能, 在语义上可以理解为将迭代器中的元素收集到指定的集合容器中,比如前面示例中所看到的collect::<Vec<i32>>(),就是将迭代器元素收集到 Vec<i32>类型的动态数组容器中。通过turbofish语法还可以指定其他的集合容器,比如collect::<HashMap<i32,i32>>()等。代码清单6-84展示了collect消费器源码。
代码清单6-84:collect源码示意
pub trait Iterator {
type Item;
...
fn collect<B: FromIterator<Self::Item>>(self) -> B where Self:Sized {
FromIterator::from_iter(self)
}
}看得出来collect消费器的源码很简单,其内部只是调用FromIterator::from_iter方法。前面已经讲过,FromIterator和IntoIterator 是互为逆操作的两个 trait。代码清单 6-85 展示了FromIterator的源码。
代码清单6-85:FromIterator源码示意
pub trait FromIterator<A>: Sized {
fn from_iter<T: IntoIterator<Item=A>>(iter: T) -> Self;
}该 trait 只定义了唯一的泛型方法 from_iter,它的方法签名中使用了trait 限定IntoIterator<Item=A>,表示只有实现了IntoIterator的类型才可以作为其参数。集合容器只需要实现该trait,就可以拥有使用collect消费器收集迭代器元素的能力,代码清单6-86所展示的集合MyVec就实现了FromIberotor trait。
代码清单6-86:自定义集合MyVec实现FromIterator
use std::iter::FromIterator;
#[derive(Debug)]
struct MyVec(Vec<i32>);
impl MyVec {
fn new() -> MyVec {
MyVec(Vec::new())
}
fn add(&mut self, elem: i32) {
self.0.push(elem);
}
}
impl FromIterator<i32> for MyVec {
fn from_iter<I: IntoIterator<Item = i32>>(iter: I) -> Self {
let mut c = MyVec::new();
for i in iter {
c.add(i);
}
c
}
}
fn main() {
let iter = (0..5).into_iter();
let c = MyVec::from_iter(iter);
assert_eq!(c.0, vec![0, 1, 2, 3, 4]);
let iter = (0..5).into_iter();
let c: MyVec = iter.collect();
assert_eq!(c.0, vec![0, 1, 2, 3, 4]);
let iter = (0..5).into_iter();
let c = iter.collect::<MyVec>();
assert_eq!(c.0, vec![0, 1, 2, 3, 4]);
}在代码清单6-86中,通过元组结构体包装Vec<i32>创建了MyVec结构体,将其作为自定义的集合容器,并为其实现FromIterator。然后在main函数中就可以使用collect来把迭代器元素收集到自定义的MyVec容器中了。
这里需要注意的是,直接调用MyVec::from_iter方法和使用collect方法的效果是一样的。
6.3.6 自定义迭代器适配器
Rust虽然提供了很多迭代器适配器,但是面对实际开发中各种各样的需求时还是显得不够用。幸运的是,在Rust中可以很容易地自定义迭代器适配器,这得益于Rust的高度一致性。
接下来要实现一个自定义的迭代器适配器,主要功能是让迭代器按指定的步数来遍历,而不是逐个遍历。首先,需要定义一个迭代器适配器Step<I>,如代码清单6-87所示。
代码清单6-87:定义迭代器适配器Step<I>
#[derive(Clone, Debug)]
#[must_use = "iterator adaptors are lazy and do nothing unless consumed"]
pub struct Step<I> {
iter: I,
skip: usize,
}代码清单6-87定义了泛型结构体Step<I>,将它作为迭代器适配器,其成员iter用于存储迭代器,skip用于存储迭代的步数。接下来,需要为其实现Iterator,如代码清单6-88所示。
代码清单6-88:为Step实现Iterator
impl<I> Iterator for Step<I>
where I: Iterator,
{
type Item = I::Item;
fn next(&mut self) -> Option<I::Item> {
let elt = self.iter.next();
if self.skip > 0 {
self.iter.nth(self.skip - 1);
}
elt
}
}代码清单6-88为Step实现了Iterator中定义的两个核心方法next。值得注意的是,这里需要将关联类型Item指定为原迭代器的关联类型I::Item。
实现next和size_hint方法时,必须符合Iterator trait中next方法签名规定的参数和返回值类型。其中next方法必须按指定的步数来迭代,所以此处next方法实现的时候,需要根据Step适配器中的skip字段来跳到相应的元素。如果skip是2,调用next时则需要跳过第一个元素,直接到第二个元素。注意代码第8行使用了nth方法,该方法会直接返回迭代器中第n个元素。
接下来,需要创建一个step方法来产生Step适配器,如代码清单6-89所示。
代码清单6-89:创建step方法来产生Step适配器
pub fn step<I>(iter: I, step: usize) -> Step<I>
where I: Iterator,
{
assert!(step != 0);
Step {
iter: iter,
skip: step - 1,
}
}代码清单6-89创建了step方法,接收两个参数,第一个为迭代器,第二个为指定步数。返回一个Step结构体实例。
现在,一个完整的迭代器适配器已经创建好了。最后只需要为所有的迭代器实现step方法即可,如代码清单6-90所示。
代码清单6-90:为所有的迭代器实现step方法
pub trait IterExt: Iterator {
fn step(self, n: usize) -> Step<Self>
where Self: Szied,
{
step(self, n)
}
}
impl<T: ?Sized> IterExt for T where T: Iterator {}代码清单6-90做了两件事。第一件事是自定义了一个继承自Iterator 的子 trait,名为IterExt,其中定义了step方法并给出了默认的实现:直接使用step函数创建Step适配器并返回。第二件事如代码第8行所示,使用impl为所有实现了Iteraotr的类型T实现IterExt。至此,整个迭代器适配器才算大功告成,可以直接使用了,如代码清单6-91所示。
代码清单6-91:应用迭代器适配器Step
fn main() {
let arr = [1, 2, 3, 4, 5, 6];
let sum = arr.iter().step(2).fold(0, |acc, x| acc + x);
assert_eq!(9, sum); // [1, 3, 5]
}在代码清单6-91中,数组arr通过iter方法转换为迭代器之后,就可以直接调用step方法来指定迭代的步数了,此例中指定步数为2,迭代的元素应该是[1,3,5],所以使用fold消费器对其求和所得值等于9。
以上就是自定义迭代器适配器的具体思路。
实际上,Rust社区有很多第三方包(crate)也提供了迭代器适配器,其中最常用的是Itertools。代码清单6-92是Itertools包中实现的Positions适配器示例。
代码清单6-92:Itertools包中实现的Positions迭代器适配器
#[must_use = "iterator adaptors are lazy and do nothing unless consumed"]
#[derive(Debug)]
pub struct Positions<I, F> {
iter: I,
f: F,
count: usize,
}
pub fn positions<I, F>(iter: I, f: F) -> Positions<I, F>
where I: Iterator,
F: FnMut(I::Item) -> bool,
{
Positions {
iter: iter,
f: f,
count: 0,
}
}
impl<I, F> Iterator for Positions<I, F>
where I: Iterator,
F: FnMut(I::Item) -> bool,
{
type Item = usize;
fn next(&mut self) -> Option<Self::Item> {
while let Some(v) == self.iter.next() {
let i = self.count;
self.count = i + 1;
if (self.f)(v) {
return Some(i);
}
}
None
}
fn size_hint(&self) -> (usize, Option<usize>) {
(0, self.iter.size_hint().1)
}
}
impl<I, F> DoubleEndedIterator for Positions<I, F>
where I: DoubleEndedIterator + ExactSizeIterator,
F: FnMut(I::Item) -> bool,
{
fn next_back(&mut self) -> Option<Self::Item> {
while let Some(v) = self.iter.next_back() {
if (self.f) (v) {
return Some(self.count + self.iter.len())
}
}
None
}
}
pub trait Itertools: Iterator {
fn positions<P>(self, predicate: P) -> Positions<Self, P>
where Self: Sized,
P: FnMut(Self::Item) -> bool,
{
positions(self, predicate)
}
}
impl<T: ?Sized> Itertools for T where T: Iterator {}
fn main() {
let data = vec![1, 2, 3, 3, 4, 6, 7, 9];
let r = data.iter().positions(|v| v % 3 == 0);
let rev_r = data.iter().positions(|v| v % 3 == 0).rev();
for i in r {println!("{:?}", i)} // OUTPUT: 2 3 5 7
for i in rev_r {println!("{:?}", i)} // OUTPUT: 7 5 3 2
}代码清单6-92是从Itertools包中摘选出来的Positions迭代器适配器的完整实现,从main函数中可以看出,其功能是输出满足闭包内指定条件元素的索引(位置)。
第3行到第7行定义了Positions结构体,包含三个成员字段。其中iter用来存储迭代器,f用来存储闭包,count用来计数。
第8行到第17行实现了positions方法,用来生成Positions迭代器实例。
第18行到第36行为Positions实现了Iterator中核心的next方法和size_hint方法。注意其中的next方法,在每次迭代时,会使用count来进行计数并执行闭包,如果满足闭包条件则返回相应的计数,就是所得索引值。
第37行到第49行为Positions实现了DoubleEndIterator和ExactSizeIterator,支持反向遍历和确定迭代器大小。
第50行到第57行创建了Itertools,其继承自Iterator的子trait,作用是扩展Iterator。该trait实现了positions方法,迭代器就可以调用了。
在main函数中,第61行和第62行分别使用了positions方法正确获得Positions迭代器,并在其后的两个for循环中获得预期的结果。
除了Positions适配器,Itertools还提供了更多的适配器和其他扩展迭代器的方法。如有需要,可以在crates.io网站找到它。
6.4 小结
本章从函数式编程范式的角度探讨了Rust中的函数和闭包。在Rust中,函数是一等公民,可以作为其他函数的参数或返回值。将函数作为参数或返回值的函数,叫高阶函数。在函数之间传递的是函数指针类型fn。虽然Rust也支持高阶函数,但是函数本身并不能捕获环境变量,无法完成某些情况下的需求,所以Rust也引入了闭包。
闭包可以捕获其在被定义时环境中的变量。在Rust中,闭包实际上是一种trait语法糖。对应所有权系统,闭包有三个trait,分别是Fn、FnMut、FnOnce,它们由编译器自动生成。生成哪种类型的闭包,与捕获变量属于复制语义还是移动语义有关联。闭包也可以作为函数的参数 和返回值,这就极大地提高了Rust语言的抽象表达能力。但是因为闭包是trait语法糖,所以在返回闭包的时候,需要把闭包装箱用作 trait 对象。闭包装箱会带来性能问题,所以Rust官方团队在Rust 2018版本中引入了impl Trait功能,来支持直接返回闭包,而不再需要trait对象。顾名思义,impl Trait代表实现了指定Trait(比如闭包的Fn、FnMut、FnOnce)的类型,它类似返回值上的trait限定,属于静态分发。
闭包最常见的应用就是迭代器,Rust迭代器的应用非常广泛。Rust基于trait和结构体非常漂亮地实现了迭代器模式,以及迭代器适配器模式,不仅在标准库中提供了很多迭代器相关的方法,而且开发者还可以非常方便地编写自己的迭代器适配器,来扩展Rust的迭代器。Rust迭代器是基于for循环的外部迭代器,for循环其实也是语法糖,它会自动调用next方法来遍历集合容器中的元素。
Rust的迭代器和迭代器适配器均是惰性的,也就是说,如果没有真正的消费数据的行为发生,它们是不会工作的。这种用于消费迭代器数据的工具叫消费器。Rust提供了有限的几种消费器,比如collect和fold。这些消费器实际上是一种内部迭代器。内部迭代器的好处是不支持return、break和continue,减少了相关的检查,可以方便编译器进行优化,在某些场景中提升性能。这些内部迭代器实际上是基于for循环实现的。std::iter模块中还定义了很多迭代器相关的方法,读者可以自行探索和练习。
通过学习函数、闭包和迭代器,读者应该对Rust有了更深的认识, 也应该能更进一步地体会到Rust语言设计的一致性了。基于trait、结构体和所有权,完美地提供了函数式编程范式中的常用高级语言特性,也许这正是Rust语言的优雅性所在。




